Shtml

Использование шины НyperТransport на примере двухпроцессорной системы на базе AMD Opteron
HyperTransport

Эмблема HyperTransport Technology Consortium
HyperTransport – это прежде всего технология, управлением спецификациями и продвижением которой занимается HyperTransport Technology Consortium, куда входят такие компании, как Advanced Micro Devices (AMD), Alliance Semiconductor, Apple Computer, Broadcom Corporation, Cisco Systems, NVIDIA, PMC-Sierra, Sun Microsystems, Transmeta и ещё более 140 малых и больших компаний.
Как мы видим, последовательные интерфейсы
Как мы видим, последовательные интерфейсы пришли в компьютерную индустрию всерьёз и надолго. Не за горами времена, когда такие почётные долгожители, как PCI, IDE(PATA), SCSI, совсем уйдут со сцены, ибо преемники – PCI Express, Serial ATA, Serial Attached SCSI – уже агрессивно отвоёвывают позиции у «старичков». В стане процессорных шин пока паритет – архитектура K8 компании AMD c организацией процессорной шины на основе HyperTransport уже зарекомендовала себя как удачное решение, но и компания Intel с «последней редакцией» параллельной шины FSB (QPB) чувствует себя довольно уверенно и не собирается от неё отказываться.
Что касается возможной войны технологий PCI Express и HyperTransport, то здесь не тот случай – уж слишком разные сферы применения уготованы разработчиками этим решениям. Для вторжения в сферу сверхбыстрых передач у PCI Express недостаточно пропускной способности (максимум 8 ГБ/с для х16 против 41 ГБ/с у HyperTransport). Что касается работы HyperTransport с периферийными контроллерами, то данная шина не обладает для этого достаточными возможностями протоколов в силу своего изначального предназначения – замены процессорной шины, первое упоминание о «горячем» подключении появилось лишь в спецификации HyperTransport 3.0, да и стандартом пока что не предусмотрено внешних разъёмов.
| 8.обратно | Заложены в изначальной спецификации. |
Основные особенности и возможности, предоставляемые технологией HyperTransport
Технология HyperTransport (ранее известная как Lightning Data Transport) – это последовательная (пакетная) связь, построенная по схеме peer-to-peer (точка-точка), обеспечивающая высокую скорость при низкой латентности (low-latency responses). HyperTransport имеет оригинальную топологию на основе линков, тоннелей, цепей (цепь – последовательное объединение нескольких туннелей) и мостов (мост выполняет маршрутизацию пакетов между отдельными цепями), что позволяет этой архитектуре легко масштабироваться. Иными словами, HyperTransport призвана упростить внутрисистемные сообщения (передачи) посредством замены существующего физического уровня передачи существующих шин и мостов, а также снизить количество узких мест и задержек. При всех этих достоинствах HyperTransport характеризуется также малым числом выводов (low pin counts) и низкой стоимостью внедрения. HyperTransport поддерживает автоматическое определение ширины шины6, допуская ширину от 2 до 32 бит в каждом направлении, использует Double Data Rate, или DDR (данные посылаются как по переднему, так и по заднему фронтам сигнала синхронизации), кроме того, она позволяет передавать асимметричные потоки данных к периферийным устройствам и от них.

Топология шины HyperTransport
На данный момент консорциумом HyperTransport разработана уже третья версия спецификации, согласно которой шина HyperTransport может работать на частотах до 2,6 ГГц (сравните с шиной PCI и её 33 или 66 МГц). Это позволяет передавать до 5200 миллионов пакетов в секунду при частоте сигнала синхронизации 2,6 ГГц; частота сигнала синхронизации настраивается автоматически.
Полноразмерная (32-битная) полноскоростная (2,6 ГГц) шина способна обеспечить пропускную способность до 20800 МБ/с (2*(32/8)*2600) в каждую сторону, являясь на сегодняшний день самой быстрой шиной среди себе подобных.
Самые известные решения c использованием HyperTransport:
шина, созданная по технологии HyperTransport, является основной шиной, используемой в процессорах восьмого поколения компании AMD – Athlon 64 и Opteron, а также внутри поддерживающих их устройств: концентратора ввода-вывода (I/O hub) AMD-8111, AMD-8131 PCI-X tunnel и AMD-8151 AGP 3.0 graphics tunnel SiPackets предлагает мост между HyperTransport и PCI (HyperTransport-to-PCI bridge)7 соединение между северным и южным мостами в чипсетах NVIDIA nForce (nForce-nForce 6) платформенная архитектура обработки данных NVIDIA (NVIDIA nForce Platform Processing Architecture), включающая встроенный графический процессор NVIDIA (NVIDIA nForce Integrated Graphics Processor (IGP) и процессор передачи данных NVIDIA (NVIDIA nForce Media and Communications Processor (MCP) соединение между мостами в чипсете ATI Radeon® Xpress 200 для процессоров AMD консольный чипсет игровой приставки Xbox фирмы Microsoft (Microsoft Xbox) системный контроллер ServerWorks HT-2000 HyperTransport™ SystemI/O™ Controller компьютеры фирмы Apple с процессором PowerPC G5
Увеличить Использование шины НyperТransport на примере двухпроцессорной системы на базе AMD Opteron
| 1(к тексту) | Компьютерная шина (магистраль передачи данных между отдельными функциональными блоками компьютера) – совокупность сигнальных линий, объединённых по их назначению (данные, адреса, управление), которые имеют определённые электрические характеристики и протоколы передачи информации. Шины отличаются разрядностью, способом передачи сигнала (последовательные или параллельные), пропускной способностью, количеством и типами поддерживаемых устройств, протоколом работы, назначением (внутренняя, интерфейсная). Шины могут быть синхронными (осуществляющими передачу данных только по тактовым импульсам) и асинхронными (осуществляющими передачу данных в произвольные моменты времени), а также могут использовать мультиплексирование (передачу адреса и данных по одним и тем же линиям) и различные схемы арбитража (то есть способа совместного использования шины несколькими устройствами). |
| 2(к тексту) | Основным отличием параллельных шин от последовательных является сам способ передачи данных. В параллельных шинах понятие «ширина шины» соответствует её разрядности – количеству сигнальных линий, или, другими словами, количеству одновременно передаваемых («выставляемых на шину») битов информации. Сигналом для старта и завершения цикла приёма/передачи данных служит внешний синхросигнал. В последовательных же каналах передачи используется одна сигнальная линия (возможно использование двух отдельных каналов для разделения потоков приёма-передачи). Соответственно, информационные биты здесь передаются последовательно. Данные для передачи через последовательную шину облекаются в пакеты (пакет – единица информации, передаваемая как целое между двумя устройствами), в которые, помимо собственно полезных данных, включается некоторое количество служебной информации: старт-биты, заголовки пакетов, синхросигналы, биты чётности или контрольные суммы, стоп-биты и т. п. Но в свете последних достижений в «железной» сфере компьютерной индустрии малое количество сигнальных линий и логически более сложный механизм передачи данных последовательных шин оборачиваются для них существенным преимуществом – возможностью практически безболезненного наращивания рабочих частот в таких пределах, каких никогда не достичь громоздким параллельным шинам с их высокочастотными проблемами ожидания доставки каждого бита к месту назначения. Проблема в том, что каждая линия такой шины имеет свою длину, свою паразитную ёмкость и индуктивность и, соответственно, своё время прохождения сигнала от источника к приёмнику, который вынужден выжидать дополнительное время для гарантии получения данных по всем линиям. Так, к примеру, каждый байт, передаваемый через линк шины PCIExpress, для увеличения помехозащищённости «раздувается» до 10 бит, что, однако, не мешает шине передавать до 0,25 ГБ за секунду по одной паре проводов. Да, ширина последовательной шины на самом деле является количеством одновременно задействованных отдельных последовательных каналов передачи. |
| 3(к тексту) | Кстати, именно результирующей «учетверённой» частотой передачи данных (как и в случае с «удвоенной» передачей DDR-шины, где данные передаются дважды за такт) хвастаются производители и продавцы, умалчивая тот факт, что для многочисленных мелких запросов, где данные в большинстве своём умещаются в одну 64-байтную порцию (и, соответственно, не используются возможности DDR или QDR/QPB), на чтение/запись важнее именно частота тактирования. |
| 4(к тексту) | Пример: для системы на базе процессора Athlon 64-3000+ (1,8 ГГц) с установленной памятью DDR-333 стандартная частота ядра (1,8 ГГц) достигается умножением на 9 частоты НТТ, равной 200 МГц, стандартная частота шины HyperTransport (1 ГГц) – умножением НТТ на 5, а частота шины памяти (166 МГц) – делением частоты ядра на 11. |
| 5(к тексту) | Пример: процессор Intel Celeron 1,7GHz Willamette с заявленной на коробке частотой шины FSB-QPB 400 МГц, тем не менее, имеет коэффициент умножения 17 (1700=100*17), а не 4,5. |
| 6(к тексту) | Несмотря на присутствие такого параметра, как ширина, шина HyperTransport является последовательной, что не позволяет соотносить ширину шины с её разрядностью. |
| 7(к тексту) | Напомним, что к процессору х86-архитектуры нельзя напрямую подключать устройства с шинами PCI, так как этот процессор использует свою специализированную процессорную шину, которая, однако, может быть различной у разных процессоров. |
PCI

Эмблема PCI Conventional
Вот уже более десяти лет PCI – шина для подключения периферийных устройств к материнской плате компьютера – находится внутри практически каждого компьютера и, даже несмотря на моральное устаревание и уже недостаточную пропускную способность, продолжает (пока ещё) оставаться основной шиной для подключения к системе внешних устройств. Тем не менее она неуклонно сдаёт позиции новой последовательной шине PCI-Express, о которой чуть ниже.
В далёком 1991 году компания Intel представила первую спецификацию системной шины PCI – Peripheral Component Interconnect (дословно: взаимосвязь периферийных компонентов). А в 1993 году уже началось активное продвижение на рынок шины PCI 2.0, которая дала толчок увеличению числа ориентированных на неё продуктов и довольно быстро вытеснила изрядно устаревшие к тому времени шины ISA и EISA.
Причины успеха PCI – это гораздо большая скорость и возможность динамического конфигурирования периферийных устройств, подключённых к PCI (чего не было в ISA), то есть распределения ресурсов между периферийными устройствами наиболее приемлемым в данный момент времени образом и без постороннего вмешательства.
Основные тактико-технические характеристики PCI 2.0:
частота шины – 33,33 МГц, передача синхронная разрядность шины – 32 бит пиковая пропускная способность – 133 Мбит/с адресное пространство памяти – 32 бит (4 Гбайт) адресное пространство портов ввода-вывода – 32 бит (4 Гбайт) количество подключаемых устройств – до четырёх (для увеличения их количества используется мост PCI-to-PCI) конфигурационное адресное пространство (для одной функции) 256 байт напряжение 3,3 или 5 ВВскоре PCI «взяли на вооружение» также платформы с процессорами Alpha, MIPS, PowerPC, SPARC и другие.
Ещё большее распространение получил стандарт 2.2.
Отличия PCI 2.2 от 2.0:
возможность одновременной работы нескольких устройств bus-master (так называемый конкурентный режим) появление универсальных карт расширения, способных работать как в слотах 5 В, так и в 3,3 В появились расширения PCI66 и PCI64 (ширина шины может быть увеличена до 64 бит, а также допускается разгон тактовой частоты до 66 МГц – вдвое по сравнению с PCI 2.0) сделанные в соответствии с этими стандартами карты расширения имеют универсальный разъём и способны работать практически во всех более поздних разновидностях слотов шины PCI, а также, в некоторых случаях, и в слотах 2.1
Типы PCI-разъёмов
Со времён анонса PCI 2.0 разработкой и продвижением стандарта занимается специальная организация– консорциум PCI-SIG (Special Interest Group), она же занимается продвижением PCI Express.
Существует множество вариаций на тему PCI 2.Х, наиболее распространённые из которых:
AGP – разработана на базе PCI 2.1 и предназначена для использования с графическими адаптерами, характеризуется отсутствием арбитража интерфейса, то есть допускается подключение к этой шине только одного устройства, также устранена мультиплексированность PCI-X – ускоренная до 133 МГц (также выпускались варианты с 266 и 533 МГц) шина PCI 2.2 с обязательно 64-битной разрядностью интерфейса

PCI-Express

Эмблема PCI Express
Разработка рабочей группой Arapahoe, основанной компаниями Compaq, Dell, IBM, Intel и Microsoft при участии организации PCI-SIG, нового межкомпонентного интерфейса была начата фирмой Intel еще тогда, когда только ожидался выход в свет AGP 3.0 (он же AGP 8х). Так, программную модель PCI планировали унаследовать и в новом интерфейсе, чтобы системы и контроллеры могли быть доработаны для использования новой шины путём замены только физического уровня, без доработки программного обеспечения. Сам же интерфейс должен был быть последовательным. Это означало, во-первых, однозначное подключение «точка-точка», исключающее арбитраж шины и перетасовку ресурсов (как частный случай – прерываний). Во-вторых, упрощалась схемотехника, разводка и монтаж. В-третьих, экономилось место.
Анонс первой базовой спецификации PCI-Express состоялся в июле 2002 года, когда уже стало ясно, что PCI-Express – это последовательный интерфейс, нацеленный на использование в качестве локальной шины и имеющий много общего с сетевой организацией обмена данными, в частности, топологию типа «звезда» и стек протоколов.
Для взаимодействия с остальными узлами ПК, которые так или иначе обходятся собственными шинами, основной связующий компонент системной платы – Root Complex Hub (узел, являющийся перекрёстком процессорной шины, шины памяти и PCI-Express) – предусматривает систему мостов и свитчей. Логика всей структуры такова, что любые межкомпонентные соединения непременно оказываются построенными по принципу «точка-точка», свитчи-коммутаторы выполняют однозначную маршрутизацию пакета от отправителя к получателю.
Соединение между двумя устройствами PCI Express называется link и состоит из одного (называемого 1x) или нескольких (2x, 4x, 8x, 12x, 16x и 32x) двунаправленных последовательных соединений lane. Каждое устройство должно поддерживать соединение 1x.
| 1 | 250 Мбайт/с | 500 Мбайт/с |
| 2 | 500 Мбайт/с | 1 Гбайт/с |
| 4 | 1 Гбайт/с | 2 Гбайт/с |
| 8 | 2 Гбайт/с | 4 Гбайт/с |
| 16 | 4 Гбайт/с | 8 Гбайт/с |
| 32 | 8 Гбайт/с | 16 Гбайт/с |
Таблица. Пропускная способность шины PCI Express с разным количеством связей
В спецификации PCI-Express 2.0 планируется увеличить пропускную способность lane до 5 Гбит/с при сохранении совместимости с PCI-Express 1.1.

Шины (links) PCI Express показаны оранжевым цветом Кроме всего прочего, PCI Express предлагает:
стек протоколов, каждый уровень которого может быть усовершенствован, упрощён или заменён, не влияя на остальные. Например: может быть использован иной носитель сигнала – или может быть упразднена маршрутизация в случае выделенного канала только для одного устройства (как в случае PCI Express x16 для графики) возможности «горячей» замены карт (заложены в спецификации, опционально реализуются в серверных системах) возможности создания виртуальных каналов, гарантирования пропускной полосы и времени отклика, сбора статистики QoS (Quality of Service – качество обслуживания)8 возможности контроля целостности передаваемых данных (CRC)8 поддержка технологий энергосбережения (ACPI)8
Процессорная шина
Любой процессор архитектуры x86CPU обязательно оснащён процессорной шиной. Эта шина служит каналом связи между процессором и всеми остальными устройствами в компьютере: памятью, видеокартой, жёстким диском и так далее. Так, классическая схема организации внешнего интерфейса процессора (используемая, к примеру, компанией Intel в своих процессорах архитектуры х86) предполагает, что параллельная мультиплексированная процессорная шина, которую принято называть FSB (Front Side Bus), соединяет процессор (иногда два процессора или даже больше) и контроллер, обеспечивающий доступ к оперативной памяти и внешним устройствам. Этот контроллер обычно называют северным мостом, он входит в состав набора системной логики (чипсета).
Используемая Intel в настоящее время эволюция FSB – QPB, или Quad-Pumped Bus, способна передавать четыре блока данных за такт и два адреса за такт! То есть за каждый такт синхронизации шины по ней может быть передана команда либо четыре порции данных (напомним, что шина FSB–QPB имеет ширину 64 бит, то есть за такт может быть передано до 4х64=256 бит, или 32 байт данных). Итого, скажем, для частоты FSB, равной 200 МГц, эффективная частота передачи адреса для выборки данных будет эквивалентна 400 МГц (2х200 МГц), а самих данных – 800 МГц (4х200 МГц)3.
В архитектуре же AMD64 (и её микроархитектуре K8), используемой компанией AMD в своих процессорах линеек Athlon 64/Sempron/Opteron, применён революционно новый подход к организации интерфейса центрального процессора – здесь имеет место наличие в самом процессоре нескольких отдельных шин. Одна (или две – в случае двухканального контроллера памяти) шина служит для непосредственной связи процессора с памятью, а вместо процессорной шины FSB и для сообщения с другими процессорами используются высокоскоростные шины HyperTransport. Преимуществом данной схемы является уменьшение задержек (латентности) при обращении процессора к оперативной памяти, ведь из пути следования данных по маршруту «процессор – ОЗУ» (и обратно) исключаются такие весьма загруженные элементы, как интерфейсная шина и контроллер северного моста.

В классической же схеме с шиной FSB и контроллером памяти, вынесенным в северный мост, возможна (и используется) асинхронность шин FSB и ОЗУ, а опорной частотой для процессора выступает частота тактирования5 (а не передачи данных) шины FSB, частота же тактирования шины памяти может задаваться отдельно. Из наиболее свежих чипсетов возможностью раздельного задания частот FSB и памяти обладает NVIDIA nForce 680i SLI, что делает его отличным выбором для тонкой настройки системы (разгона).
Современные внутренние шины – смена приоритетов!
Максим Шиша
Тестовая лаборатория Ferra Всё течёт, всё меняется. В сфере компьютерных технологий эта фраза никогда не потеряет актуальности, равно как и девиз «Быстрее! Выше! Сильнее!». И действительно, последние несколько лет можно назвать «временами перемен» компьютерной индустрии. В полной мере это коснулось и такой специфичной области, как шины передачи данных.
Среди наиболее динамично развивающихся областей компьютерной техники стоит отметить сферу технологий передачи данных: в отличие от сферы вычислений, где наблюдается продолжительное и устойчивое развитие параллельных архитектур, в «шинной»1 сфере, как среди внутренних, так и среди периферийных шин, наблюдается тенденция перехода от синхронных параллельных шин к высокочастотным последовательным. (Заметьте, «последовательные» – не обязательно значит «однобитные», здесь возможны и 2, и 8, и 32 бит ширины при сохранении присущей последовательным шинам пакетной передачи данных, то есть в пакете импульсов данные, адрес, CRC и другая служебная информация разделены на логическом уровне2).
Все эти нововведения и смена приоритетов преследуют в конечном итоге одну цель – повышение суммарного быстродействия системы, ибо не все существующие архитектурные решения способны эффективно масштабироваться. Несоответствие пропускной способности шин потребностям обслуживаемых ими устройств приводит к эффекту «бутылочного горлышка» и препятствует росту быстродействия даже при дальнейшем увеличении производительности вычислительных компонентов – процессора, оперативной памяти, видеосистемы и так далее.
Сводная таблица конструктивов карт и слотов в зависимости от версии стандарта
| PCI 1.x-2.0 | 133 | 32 бит, 5 В | 32 бит, 5 В |
| PCI 2.1-2.3 33 MГц | 133 | 32 бит, 5 В | 32 бит, 5 В / универсальный |
| PCI 2.2-2.3 66 MГц | 266 | 32 бит, 3,3 В | 32 бит, 3,3 В / универсальный |
| PCI64 33 МГц (v 2.1) | 266 | 64 бит, 5 В | 64 бит, 5 В / универсальный |
| PCI64 33 МГц (v 2.2) | 266 | 64 бит, 3,3 В | 64 бит, 3,3 В / универсальный |
| PCI64 66 МГц | 533 | 64 бит, 3,3 В | 64 бит, 3,3 В / универсальный |
| PCI-X 1.0 | 1024 | 64 бит, 3,3 В | 64 бит, 3,3 В / универсальный |
| PCI-X 1.0 | 4096 | 64 бит, 3,3 В | 64 бит, 3,3 В |
Однако, как и многие параллельные шинные решения (те же Parallel ATA, SCSI), шина PCI в данное время находится на границе разумного масштабирования производительности, после которого «гонка частот и разрядности» приведёт к непозволительно высоким технологическим усложнениям и, соответственно, к затратам. Но на данный момент проблема эффективной масштабируемости и наращивания уже решена, ведь в компьютерной индустрии уже полным ходом идёт переезд с PCI на новую последовательную шину PCI-Express.

Различия топологий PCI и PCI-Express
Кодовое имя «Conroe» — заявка на победу
Евгений Патий
"Экспресс Электроника"
Известно, что в историческом плане все развивается по спирали. В доказательство можно привести массу примеров. А сегодня это утверждение как нельзя лучше подходит к процессорному бизнесу компании Intel.
На архитектуре NetBurst можно ставить крест. Хотелось бы добавить: «Как на не оправдавшей надежд». Но поостережемся и не будем рубить с плеча — все не так однозначно, кое-какие выводы компания Intel для себя сделала. Более того, NetBurst стала родительницей многих технологий и заставила производителей ощутимо напрячься в конкурентной борьбе. Как сказал кто-то из древних, опыт берет большую плату за обучение, но и учит лучше других учителей.
Уже можно считать, что процессора Pentium 4 нет, он стал достоянием истории. Блеск и нищета платформы NetBurst — это был Pentium 4.
Давайте припомним, как все началось и чем закончилось. За прекрасным процессором Pentium III (Tualatin), последним отпрыском семейства P6, свет увидел первый Pentium 4 с ядром Willamette, крайне неоднозначно принятый рынком. Первые модели безоговорочно проигрывали Pentium III практически по всем фронтам, несмотря на более высокую тактовую частоту. Однако Intel заверяла общественность, что это лишь старт и Pentium 4 попросту не способен раскрыть свой потенциал на такой невысокой, с точки зрения новой архитектуры NetBurst, частоте. Дальше, мол, все будет гораздо радужнее.
Процессор Pentium 4 и архитектура NetBurst оказались заложниками тактовой частоты, что привело к достаточно неприятным последствиям. Хотя и здесь дела обстоят не просто: изначально, на бумаге, процессоры — потомки NetBurst выглядели великолепно. Но выяснилось, что, если воплотить все инженерные идеи в кремнии, цена конечного изделия будет совершенно не совместима со здравым смыслом, его попросту никто не купит. Скрепя сердце, пришлось здесь урезать, тут ужать, там уменьшить и переделать. Осталось уповать лишь на сверхвысокую тактовую частоту, на которой процессор действительно способен себя проявить.
Ведь непривычно длинный конвейер NetBurst частично избавится от своей «болезни непредсказуемости» лишь на высокой частоте, точнее, именно в этом случае частый сброс конвейера из-за очередного неверного предсказания не будет столь сильно бить по производительности. В итоге получился замкнутый круг: длинный конвейер позволяет разогнать ядро до очень высокой частоты, а частота, в свою очередь, позволяет закрыть глаза на промашки алгоритмов предсказания. Как видим, повышение частоты — единственный возможный путь развития архитектуры NetBurst.
Достаточно быстро и без особых проблем удалось достичь тактовой частоты в 2 ГГц. Затем последовали перевод производства чипов на более тонкий технологический процесс (со 180 до 130 нм), перепрофилирование фабрик на выпуск 300-мм кремниевых пластин вместо 200-мм и выпуск нового процессорного ядра Northwood (разумеется, также спроектированного с учетом идей NetBurst). Northwood выглядел намного привлекательнее Willamette: увеличенный объем полноскоростной кэш-памяти второго уровня, утонченный техпроцесс, позволяющий еще больше разогнать ядро, и значительно переработанный блок ветвлений и предсказаний, предоставляющий возможность конвейеру подольше оставаться на плаву без сброса.
Этот момент можно назвать переломным: именно Northwood помог привлечь покупателей и утвердить их в мысли, что Pentium 4 — все-таки хороший процессор. Про Pentium III тем временем и про архитектуру P6 забыли. Как выяснилось, до поры до времени.
Далее следует новейшая история. Еще более усовершенствованное ядро Prescott вкупе с еще более тонкими технологическими нормами и очередной сменой форм-фактора процессора, все та же архитектура NetBurst, и… технологический потолок достигнут. Этому способствовала тактовая частота, на которую ставила Intel. Первые тревожные звоночки появились еще до Prescott: последние модели Pentium 4 (Northwood) ощутимо нагревались и требовали мощной системы охлаждения. Причина проста: процессор, состоящий из многих миллионов транзисторов (львиная доля которых «откусывается» кэш-памятью второго уровня — для организации только одной ячейки необходимо шесть транзисторов) и работающий на высокой частоте, требует значительного количества энергии.
Если бы вся она уходила лишь на вычислительные нужды, на это можно было бы смело закрыть глаза: все-таки расходуется с пользой. Но из-за несовершенства технологии очень большая часть энергии расходовалась на паразитные токи утечки, то есть в никуда. Но и без этого не обойтись: либо данный процессор работает с токами утечки, либо не работает вовсе. Токи утечки стали причиной того самого нагрева, который необходимо свести к минимуму при помощи радиаторов и вентиляторов. Техпроцесс 90 нм у Prescott проблему не решил, а лишь ненадолго отодвинул неизбежное.
Pentium 4 официально так и не добрался даже до отметки 4 ГГц, несмотря на то что еще в 2001–2002 годах Intel называла цифры 5 и даже 10 Гц. Сегодня представители Intel признают, что такого поворота событий они не ожидали. Конечно, теоретически можно «загнать» частоту до 5 ГГц, применив какую-нибудь хитроумную систему охлаждения (с жидким азотом), но для массового рынка такое решение неприемлемо, хотя и неоднократно опробовано энтузиастами.
Казалось бы, ситуация практически тупиковая, однако спасение пришло оттуда, откуда его мало кто ждал. Параллельно с Pentium 4 компания развивала линейку мобильных процессоров, предназначенных для использования в портативных компьютерах — Pentium M (ядро Banias, затем — Dothan). В данном секторе о высокой тактовой частоте речи в принципе не заходило: слишком уж дорогое удовольствие для аккумулятора ноутбука. Поэтому архитектура NetBurst здесь была совершенно не к месту. Но ведь не из воздуха появилось ядро Banias? Разумеется нет. Для его разработки инженеры взяли лучшее от проверенной архитектуры P6, основы процессоров от Pentium Pro до Pentium III, которая при достаточно низкой тактовой частоте показывает прекрасную производительность (конвейер-то намного короче, чем у NetBurst, часто сбрасывать его нет необходимости). А если к этому добавить уже отлаженный тонкий техпроцесс, позволяющий заметно снизить тепловыделение и нарастить кэш-память второго уровня, получается практически идеальный мобильный процессор.
Вполне можно считать, что P6 вовсе не умирала. Она развивалась параллельно с NetBurst, чтобы, согласно упомянутой исторической спирали, в нужный момент вновь появиться на сцене.
После того как NetBurst оказалась в технологическом тупике, события развивались довольно стремительно. Intel, вооруженная отработанной к тому времени технологией размещения двух ядер в рамках одного чипа, оценив перспективы совершенствования Pentium M, поступила единственно правильным способом: совместила обе разработки и заодно внесла необходимые усовершенствования. Кроме того, весьма кстати оказались отточенные в эпоху NetBurst алгоритмы ветвления и предсказания, а также многие технологии из области энергосбережения.
Так родилась архитектура Intel Core — по сути P6 в квадрате, доработанная буквально до неузнаваемости. Здесь уже не декларируются высокие тактовые частоты: во-первых, они уже не так важны, как прежде, во-вторых, как бы не случилось конфуза (как с NetBurst). Два ядра показывают достойную производительность и на частотах, далеких от 4, 5 или 10 ГГц.
Intel Core успешно стартовала на рынке мобильных и настольных систем, только в первом случае это были ноутбуки на платформе Windows, а во втором — компьютеры Apple Macintosh, что в свое время наделало много шуму на рынке. Все-таки не будем забывать: пока речь идет о мобильных процессорах, которые Apple решилась использовать в нехарактерной для них среде настольных ПК.
Компания Intel решила полностью заместить NetBurst на Intel Core в сегменте мобильных, настольных и серверных систем. И если на первом и последнем рынках это уже произошло (портативные ПК на базе Intel Core продаются несколько месяцев, а серверная платформа Bensley, включающая как вариант процессор на базе Core, совсем недавно увидела свет), то сегмент традиционных настольных ПК, не допускающих вживление мобильных или серверных чипов, пока не охвачен вниманием. Точнее, соответствующего процессора для него не было объявлено. Хотя все прекрасно знают, что это чип с кодовым именем “Conroe”.
Задолго до официального анонса и начала продаж Conroe о новом процессоре было известно практически все, включая цены. Чипы Conroe будут поставляться в четырех вариантах: E6300, E6400, E6600 и E6700 с тактовой частотой 1,86, 2,13, 2,40 и 2,67 ГГц соответственно. Буква Е в названии процессора обозначает энергопотребление свыше 50 Вт, аналогично, U — до 14 Вт, L — 15–24 Вт, T — 25–49 Вт. Цена варьируется в пределах $209–530 в партиях от 1000 штук.
Согласно стратегии платформизации, Intel не может не охватить вниманием огромный рынок настольных систем. Она планирует создать две платформы на базе Conroe, которые нацелены на бизнес-сегмент рынка, традиционно приносящий компании хорошую прибыль: Averill Pro и Averill Fundamental. Первая из них — сочетание процессора серии E6000, чипсета Q965 и южного моста ICH8 с поддержкой технологий виртуализации и активного управления (Virtualization Technology и Active Management Technology). Редакция платформы Averill Fundamental включает процессоры Pentium 4 и D, а также серии E4000 и E6000 вкупе с наборами системной логики Intel 946, 975X, Q963 или Q965. Справедливости ради отметим, что есть вполне реальные шансы увидеть Conroe не только в десктоп-системах. Некоторые азиатские производители ноутбуков (в первую очередь речь идет о ноутбуках класса «замена настольного ПК») начинают задумываться об использовании в мобильных ПК процессоров нового поколения Intel Conroe, изначально разработанных для настольных ПК. Новая серия мобильных процессоров Intel Merom при меньшей производительности оказывается дороже с точки зрения цены. Так, процессор Conroe с частотой 2,67 ГГц обходится на $107 дешевле, нежели Merom с частотой 2,33 ГГц.
Необходимо более пристально рассмотреть организацию и архитектуру процессора, хотя бы для того, чтобы в первом приближении оценить его рыночные перспективы. А также по той простой причине, что Conroe кардинально отличается от предшествующих разработок корпорации Intel.
Предыдущие поколения настольных двухъядерных процессоров от Intel состояли из двух отдельных процессорных ядер, находящихся в одном чипе.
Ядра связывались системной шиной FSB. Каждое из них оснащалось собственным кэшем L2, и к кэшу другого процессорного ядра можно было получить доступ лишь через упомянутую шину.
Архитектура Conroe придерживается иного принципа. На кристалл интегрируются два раздельных ядра, которые используют общий кэш L2. Кэш распределяется между ядрами, в зависимости от нагрузки на них, с помощью технологии Intel Advanced Smart Cache, о чем наш журнал уже писал ранее в материале об архитектуре Intel Core. Если запущено неоптимизированное однопоточное приложение, потребляющее ресурсы одного из ядер (а большинство программ сегодня по-прежнему однопоточные, то есть неоптимизированные), то активное ядро может получить доступ ко всем 4 Мбайт кэш-памяти L2. Это одна из причин, почему процессор в итоге оказывается гораздо быстрее Pentium D. Если же параллельно запущены два приложения и одно из них требует лишь небольшого объема кэша, то второе приложение может получить весь оставшийся объем кэша L2. Собственно, технология общего кэша появилась чуть раньше, когда были выпущены мобильные двухъядерные процессоры Core Duo (кодовое имя Yonah). Эта технология является одной из характерных особенностей Intel Core.
В принципе, Conroe очень близка к своему мобильному родственнику с ядром Yonah, хотя и обладает некоторыми отличиями. В первую очередь необходимо отметить развитие идей энергосбережения, которые, по правде говоря, более уместны именно у Yonah, в мобильном сегменте. Но так или иначе, Conroe гораздо тщательнее проработан в отношении энергопотребления и, как следствие, рассеиваемого тепла. Intel уделила много внимания реализации технологии SpeedStep, позволяющей управлять тактовой частотой процессора в зависимости от вычислительной нагрузки — совершенно аналогично решениям для мобильного рынка.

На повестке дня — еще одно расширение набора инструкций для обработки потоковых данных, на этот раз — SSE4. О чем это говорит прежде всего? Разумеется, об оптимизации программного обеспечения, без которой SSE4 будет совершенно бесполезен. А рынок ПО издавна знаменит своей латентностью, поэтому до того момента, когда SSE4 станет полезным, может пройти немало времени.
Из действительно полезных нововведений упомянем еще более отполированные механизмы работы с памятью и аппаратной предвыборки данных. Пожалуй, у Intel, как ни у одной другой компании — производителя микропроцессоров, имеется колоссальный опыт в доводке предвыборки данных — в славные времена Pentium 4 это был единственный путь не потерять в производительности.
Мы уже говорили, что, как и у Yonah, в Conroe реализована общая кэш-память для обоих ядер процессора, причем балансировка ее объема для каждого ядра выполняется динамически в зависимости от загрузки каждого ядра.
128-разрядные инструкции SIMD выполняются за один машинный такт в каждом исполнительном устройстве (по этому параметру Conroe вдвое превосходит Yonah, у которого обработка SIMD выполняется за два машинных такта). Также отличие состоит в количестве декодеров макроопераций — четыре у Conroe и три у Yonah (как и у Pentium M).
Чтобы не быть голословными, мы решили оценить производительность нового процессора. Для этого был собран стенд следующей конфигурации:
процессор Intel Conroe (инженерный образец) 2,66 ГГц, системная шина 1066 МГц, кэш-память второго уровня 4 Мбайт; системная плата Intel D975XBX (Intel 975X), rev. 304; оперативная память Hynix DDR2-667, 1 Гбайт; видеоадаптер ATI Radeon 1900XTX, 512 Мбайт видеопамяти; жесткий диск Western Digital WD1600JS, 160 Гбайт. Оценка производительности процессора проходила в типичных вычислительных задачах: синтетические тесты, игровые приложения и медиакодирование (см. диаграмму). В целом Conroe, да и вся архитектура Intel Core, выглядит очень впечатляюще. Рискнем предположить, что начиная с момента вывода на рынок процессоров Core исчезнет львиная доля проблем с программным обеспечением, и вот почему.
Во времена доминирования NetBurst разработчикам ПО приходилось несладко — существовала необходимость скрупулезнейшей отладки кода с учетом капризного многостадийного конвейера.
Желательно было свести к минимуму количество ветвлений в программном коде, чтобы процессор не ошибся в предсказании и не пришлось сбрасывать все стадии конвейера. Core позволяет программировать «в лоб», максимально сосредоточившись на решении задачи. Это простой и мощный процессор, выполняющий то, что от него ожидается в соответствии с алгоритмической логикой программы.
Пожалуй, такого значимого продукта не было уже давно. Извечному противнику Intel, компании AMD, придется сильно напрячься, дабы удержать завоеванные позиции. И мы не рискнем давать каких-либо прогнозов относительно ситуации на этом рынке в ближайшем будущем. Как говорят, будет такая битва за мир, что камня на камне не останется.
Что же ожидает нас? Сегодня известны некоторые планы Intel касательно архитектуры Core, хотя, конечно, здесь нельзя быть уверенным на все сто процентов: история знает немало примеров, когда из роадмапов компаний выпадали процессоры либо добавлялись новые. Мы будем руководствоваться апрельской информацией от Intel и считать ее актуальной.
К концу 2006 года компания собирается выпустить преемника Conroe — процессор с кодовым именем Allendale. Можно предположить, что этот чип не станет революционным. Скорее всего, в нем будут развиты идеи Conroe, ведь два знаковых процессора для одного сегмента рынка, да еще в течение полугода, — это чересчур даже для Intel.
В 2007 году появится процессор, также из семейства Core, Penryn, который будет производиться с применением технологических норм 45 нм. Более того, Intel планирует применить новый литографический материал для «печатания» процессора. Уже добрый десяток лет компания использует для этого двуоксид кремния, Penryn же будет первым процессором компании, в котором она отойдет от традиций и применит изолятор под кодовым наименованием P1266.
Компания планирует, что Penryn окажется последним настольным процессором с архитектурой Intel Core (недолгая, однако, ей уготована судьба на этом рынке), — в 2008 году его сменит Nehalem, представитель еще более инновационной архитектуры, хотя и запланированный к производству по нормам 45 нм. Еще через год, в 2009-м, будет выпущен Nehalem-C, для которого Nehalem станет своеобразным отладочным полигоном (аналогично тому, как мобильный Yonah стал базой для настольного Conroe). Nehalem-C, наконец-то, будет выпускаться с использованием технологии глубокого ультрафиолета (Extreme Ultraviolet), о которой говорят уже пять лет и которая все никак не может быть отлажена до производственного уровня ввиду различных сложностей.
Вслед за Nehalem-C ожидается процессор Gesher, который, видимо, станет результатом внедрения еще более тонких технологических норм, 32 нм. Кроме того, в Gesher будет воплощена идея пространственного размещения транзисторов. С точки зрения нынешнего дня, когда реальны 65 нм, это выглядит как достаточно далекое будущее. Есть предположения, что уровень пространственной упаковки полупроводниковых элементов — 32 и 22 нм, а нанотехнологии станут актуальными не ранее 2013–2014 годов.
CPU - это не только мегагерцы!
Эрнст Долгий
«Экспресс-Электроника», #3/2004
Среднестатистический пользователь - тот самый, покупающий компьютер в магазине, при выборе процессора обычно обращает внимание лишь на его торговую марку, тактовую частоту, ну и еще, быть может, на объем кэша. Нельзя сказать, будто это неправильно - просто за бесконечными анонсами и представлениями новых моделей процессоров мы забываем, что любой из них является сложнейшим электронным устройством, за которым стоит не один год кропотливой работы многих исследователей, ученых и разработчиков.
Если обратиться к Большой Советской Энциклопедии, то в ней говорится, что "микропроцессор - это электронное устройство, выполненное в виде интегральной микросхемы и состоящее из цепей управления, регистров, сумматоров, счетчиков команд, а также очень быстрой памяти малого объема". Данное определение, несмотря на свой почтенный возраст, согласитесь, остается вполне актуальным. В этой статье мы расскажем о технологиях производства микропроцессоров, а также о тех достижениях, без которых современный процессор в вашем компьютере не был бы таким, какой он есть.
Его величество транзистор
Ключевое словосочетание в определении из БСЭ - "интегральная микросхема", ведь именно возможность создавать высокоинтегрированные электронные схемы позволила вычислительной технике развиваться столь стремительными темпами. Многим известно, что до применения транзисторов существовали ламповые компьютеры, но их габариты, сложность обслуживания и быстродействие было на абсолютно доисторическом уровне. В любом случае, появлению полупроводниковых устройств мы обязаны в первую очередь общепризнанным изобретателям транзистора - исследователям Bell Labs - Джону Бардену, Уолтеру Брэттэну и Уильяму Шокли (J.Barden, W.Brattain, W.B.Shockley). Почему "общепризнанным"? Дело в том, что за много лет до того, в 1922 году, наш соотечественник, радиолюбитель из Нижнего Новгорода - 19-летний Олег Лосев создал первый в мире полупроводниковый усилитель! И это еще не все - после недолгих экспериментов молодой Левша сконструировал на основе своего изобретения приемник и назвал его "кристадин" (от слова кристалл). Важным моментом в этой истории является тот факт, что изобретение Лосева не было незамеченным - о его кристадинах в те времена писала вся научная пресса, называя новое изобретение не иначе как "переворот в радиоэлектронике, вытесняющий вакуумную лампу". Поэтому к вкладу в становление основ современной микроэлектроники в немалой степени причастны и российские исследователи. Впрочем, важность открытия ученых из лаборатории Bell тоже нельзя недооценивать, ведь переворот, о котором так много писали в 1930-е годы, свершился только через четверть века, когда физика твердого тела доросла до уровня кристадина и смогла объяснить суть явлений, происходивших в нем.
Революционное значение транзистора - в его малых размерах, ведь объединение большого числа транзисторов на единой подложке позволило сначала создавать отдельные функциональные узлы, чуть позже процессоры, а теперь и законченные интегрированные устройства. Одновременно уменьшались габариты вычислительных машин, и возрастала их производительность.
Для того чтобы наглядно представлять принцип работы современных процессоров, что называется "из сердца", стоит рассказать, как они производятся.
Поэтому мы кратко коснемся технологии выращивания микросхем. Главный материал при полупроводниковом производстве - кремний, самый распространенный полупроводник на Земле. Именно из него создают подложки современных микросхем. Для этой цели применяется химически чистый кремний, который переплавляется в большие цилиндрические заготовки. После множества дополнительных химических чисток монокристалл кремния разрезается на тончайшие пластины - именно они в будущем и послужат подложкой для изготовления кристаллов процессоров. До недавнего времени стандартом при производстве кремниевых пластин являлся типоразмер 200 мм, однако сейчас все больше компаний переходит на заготовки с диаметром 300 мм. Необходимо отметить, что использование 300-мм заготовок выгодно, в первую очередь, с экономической точки зрения, так как в этом случае сокращается производственный цикл - указанные стадии для одного и того же количества создаваемых процессоров производятся реже. Кроме того, переход от 200-мм пластин к 300-мм, дает увеличение их эффективной площади на 240%. По данным компании Intel, одна только экономия воды, задействованной при шлифовке и полировке кремниевых пластин, достигает 40%. Экономия электроэнергии также довольно высока. В целом, ввод в эксплуатацию оборудования, рассчитанного на использование увеличенных пластин, сказывается на себестоимости готовой продукции, позволяя экономить около 30% на технологических ресурсах и около 50% - на снижении трудозатрат. Поэтому многие компании активно переориентируют свое производство под новый типоразмер. Однако вернемся к процессу производства микросхем. Одним из первых этапов производства микропроцессоров является воздействие на заготовку кислородом, которое происходит под высокой температурой. Таким образом, на поверхности заготовки создается тончайший слой диоксида кремния. Затем на полученную механически защищенную пластину наносят специальные обозначения, по которым позже пластина будет позиционироваться в экспонирующих аппаратах.
Следующий наносимый слой - фоторезист ( светочувствительное вещество, которое при облучении становится растворимым в определенных веществах). Именно это его свойство используется для того, чтобы "открыть" слой кремния в необходимых местах для последующей обработки. Полученная фоточувствительная заготовка устанавливается, по нанесенным заранее разметкам, в специальный экспонометр, с помощью которого на пластине формируется первичное изображение. Негативом в экспонометре служит прецизионная маска, она обычно больше пластины и создается отдельно для каждого слоя микропроцессоров (их несколько). В основе ее создания лежит эффект отрыва электронов с поверхности металла, позволяющий бомбардировкой электронов создавать на кварцевом стекле хромовые рисунки, служащие впоследствии негативом. В результате засвеченный слой, чьи структура и химические свойства изменились под действием излучения, а также находящийся под ним слой диоксида кремния могут быть удалены с помощью химикатов, методом травления (каждый слой - своим химикатом). Так изготовляются профили, где каждый выступ представляет собой одну из составных частей интегральной микросхемы - транзисторов, формирующих логические блоки создаваемого процессора. В наиболее современных процессорах компании Intel, на базе ядра Prescott применяется семь слоев металлизации (в Northwood - шесть), которые организуют необходимые электрические связи между блоками процессора. Наведения электрических связей в кристалле также производятся методом фотолитографии - в пластине производятся новые выемки, куда закладывают алюминий или медь. Медь является более выгодным электрическим и термопроводящим элементом, однако на пути ее внедрения в микропроцессор возникла определенная проблема, давшая почву для размышлений о скором конце кремниевой технологии. Суть проблемы в том, что в нормальных условиях медь не образует электрический контакт с кремнием. Однако после более глубоких исследований ученым удалось найти способ соединения с применением сверхтонкой полимерной разделительной области между кремниевой подложкой и медными проводниками, предотвращающей диффузию этих материалов. Чтобы отделить готовый слой от создаваемого, на первичное изображение микросхемы напыляется новый слой диоксида кремния.После этого на него наносится еще один слой поликристаллического кремния и новый фотослой. Далее при помощи следующей фотомаски создается рельеф второго слоя, который путем высвечивания фоторезиста и последующего его травления организует на микросхеме рабочие элементы "второго этажа". Потом на микросхему вновь наносится слой металлизации, таким образом, цикл повторения замыкается и может продолжаться далее. При создании современных процессоров обычно наносится порядка 20 слоев. Конечный этап при производстве процессоров - разрезание плиты кристаллов, монтировка их в корпуса, подключение к сокетным выводам, тесты и, наконец, упаковка.
И все это ради мегагерц
Процессор является одним из тех устройств, в которых логика функционирования неразрывно связана с технологией производства. Подтверждает это и вторая часть определения из БСЭ, где говорится о логической структуре процессоров. О ней и пойдет речь дальше.
Микропроцессор состоит из нескольких структурных блоков, так или иначе представленных во всех современных процессорах. Среди них: кэш инструкций, кэш данных, предпроцессор и постпроцессор. Поскольку перечисленные блоки имеются во всех существующих сегодня процессорах, принцип обработки в них должен быть похожим. В общем случае его можно разделить на несколько этапов.
Первый из этапов - предварительная обработка данных, которая заключается в размещении их в оперативной памяти или кэше процессора. Далее идет стадия преобразования данных в код, понятный процессору. Этот процесс происходит в предпроцессоре, передающем данные преобразованного формата (внутренний формат процессора) в постпроцессор, где и происходит их обработка. Завершается работа четырехступенчатого конвейера обратной записью в кэш либо оперативную память.
Важно понимать, что любой ход процессора не может быть произведен раньше предыдущего, равно как и все операции происходят строго циклично, то есть тактуются. Это означает, что за один Герц процессор способен провести лишь один из этапов. Вот почему так важно, чтобы частота процессора была высокой. Впрочем, количество проработанных процессором тактовых импульсов не всегда равно числу обработанных им команд, ведь существуют инструкции, которые могут быть выполнены за разное количество тактов - как менее, так и более одного. В случае, когда разработчики говорят, что их процессор может обрабатывать более одной команды за такт, речь идет о том, что структурный блок, отвечающий за их выполнение, содержит свой собственный подконвейер - он-то и выполняет собственные подинструкции за единицу собственного тактования. Именно поэтому встретить процессор, длина конвейера которого равна четырем, невозможно. И это не так плохо, ведь длинный конвейер способствует росту частоты, а значит - числу инструкций, которые могут быть обработаны в единицу времени.
Но в том-то и дело, что это в идеале, ведь вычислительный конвейер процессора мало чем отличается от калькулятора, способного вычислить все, если вы правильно поставите ему задачу.
Так и конвейер полностью полагается на работу других блоков процессора, в числе которых блок предсказания ветвлений, позволяющий обрабатывать данные спекулятивно, то есть заранее, не дожидаясь выполнения множественных циклов и других логических операторов, коими наполнен код любой программы. Все задачи, исполняемые процессором, можно разделить на две большие части. Первая из них - целочисленные операции (как правило, офисные приложения) и операции с плавающей точкой (мультимедийные приложения). Первый тип обрекает нас на большое количество переходов, предсказание которых очень трудно, и коэффициент правильного предсказания в таких приложениях весьма низок. Как следствие, при их выполнении существует постоянная необходимость заполнения конвейера правильными инструкциями (как только осуществляется неверный переход, содержимое конвейера обнуляется и он загружается заново, что приводит к существенным временным потерям). И прежде чем мы получим результат первого вычисления, пройдет несколько десятков процессорных тактов (например, для Pentium 4 Prescott - 31), что при большом количестве таких ошибок пагубно отразится на производительности. В частности, на офисных приложениях новый процессор теряет до 20-30% своей производительности в сравнении с аналогичными моделями Pentium III. Второй тип задач - мультимедийные приложения, напротив, характеризуется очень малым количеством переходов и высокой степенью их предсказания, и, как следствие, на них процессор с конвейером любой длины может реализовать всю свою мощь наилучшим образом. Если учесть, что пользователю не столь важно ускорение работы офисных программ, которым зачастую достаточно производительности процессоров двух-, трехлетней давности, то процессоры с удлиненным конвейером видятся, пожалуй, наиболее перспективными разработками. Это отражают и характеристики современных процессоров - и в продукции компании Intel, и AMD (в меньшей степени) чувствуется все большая ориентация на мультимедийные приложения. Об этом могут говорить и постоянно удлиняющиеся конвейеры, и поддержка SIMD-инструкций (Single Instruction Multiple Data), позволяющих за один такт выполнять однотипные, часто встречающиеся в потоковых приложениях алгоритмы.
Литография - скромный попутчик больших революций
Одним из способов увеличения стабильности работы чипа на более высоких частотах является переход к более низким проектным нормам. Сам по себе этот путь очень дорогой, и не только потому, что заключается в модернизации парка производственного оборудования, но и в виду сложных научных исследований, предшествующих ему. Не секрет, что, скажем, компания Intel тратит на развитие научной базы десятки миллионов долларов в год. Кроме, собственно, исследований полупроводниковых материалов и новых схеморешений ведутся разработки и в параллельных областях науки, например, в квантовой физике, так как если для фотолитографии при процессе 0,35 мк использовались ртутные лазеры с длиной волны 0,365 мк, то в технологии 0,25 мк принимали участие лазеры на основе ультрафиолета хлорида криптона с длиной волны 0,248 мк. Сегодня эти показатели еще больше приблизились к показателям рентгеновского излучения.
Для техпроцессов следующего за 90-нм технологией поколения - 65 нм, 45 нм и 32 нм - возникает необходимость использования более совершенного литографического оборудования. Дело в том, что применяемые в настоящее время литографические аппараты, при переходе к более тонким технологическим нормам, вряд ли смогут обеспечить необходимую "жесткость" излучения и должный уровень разрешающей способности при формировании проекции маски-шаблона. Длина волн 248 нм или 193 нм, которые применяются в сканерах и степперах для производства микросхем с уровнем детализации 90 нм, недостаточна для перехода к более тонким нормам. Поэтому изготовители литографического оборудования и их заказчики находятся в поиске рационального решения. Им приходится выбирать между весьма дорогостоящими инструментами нового поколения с длиной волны 157 нм и альтернативными методиками.
Само по себе внедрение 157-нм литографии сопряжено с рядом трудностей, в частности, с отсутствием методики синтеза качественного фторида кальция, из которого изготавливается литографическая оптика нового поколения, а также с проблемой фоторезистов, теряющих чувствительность в указанном спектре длин волн.
Кроме того, как утверждают представители компании Intel, внедрение 157-нм литографии сопряжено с невозможностью найти разумный ценовой компромисс, поэтому сейчас рассматриваются альтернативные методики. В частности, инженеры компании Intel изучают возможность использования литографии с применением жесткого ультрафиолета (EUV-литографии), о которой заговорили давно. Источником света для установок данного типа служат компактные газоразрядные лампы, представляющие собой цилиндр диаметром 0,5 мм и длиной несколько мм. В них применяется плотная плазма с температурой 200000-300000 0К, полученная с помощью полого катода, питаемого током около 10000 А. Лампы такого типа способны излучать электромагнитные волны в крайнем ультрафиолетовом диапазоне - порядка 13,5 нм и импульсами длительностью 30 нс. Срок службы таких ламп составляет до 100 млн пульсаций, при неизменной длине волн, что вполне приемлемо с экономической точки зрения. Компания Intel является одним из сторонников литографии с применением жесткого ультрафиолета вместо 157-нм сканеров. В ее производственных планах использование данной технологии намечено на 2007 год. В то же время немецкая компания Infineon установила экспериментальное оборудование для получения световых волн EUV-спектра в своей лаборатории, для проведения исследований в области фоторезистов и других материалов, необходимых для литографии следующего поколения. А в Японии консорциум Extreme Ultraviolet Lithography System Development Association (EUVA) приступил к разработке первой EUV-установки. Появление рабочего прототипа системы ожидается в 2005 году. Интересно отметить, что в EUVA входят два известных производителя литографического оборудования - Canon и Nikon, давние конкуренты не только в области литографического оборудования. Обе компании будут заниматься совместной разработкой оптических систем для опытной EUV-установки, но несмотря на это, намерены выводить на рынок свои собственные конечные EUV-продукты. Впрочем, EUV-литография - не единственная альтернатива.
Сегодня все чаще обращают внимание на технологию импринт-литографии, которая во многом является развитием идеи EUV-литографии. В перспективе импринт-литография позволит применить наноскопическую печать на полимерах через маску масштаба 1:1 при использовании света в ультрафиолетовом диапазоне. Такие системы проецирования маски-шаблона значительно удешевят литографические системы, поскольку отпадает необходимость использования сложных и дорогих оптических систем, составляющих львиную долю современных литографических инструментов. В настоящее время для нанесения рисунка применяются маски масштаба 4:1, следовательно, для получения точной проекции рисунка маски требуется дорогостоящая оптика. Процесс нанесения рисунка на подложку до травления в импринт-литографии не зависит от качества применяемой оптики. Мономер, покрывающий поверхность кристалла, под действием ультрафиолетового излучения полимеризуется и застывает на поверхности. Он содержится в растворе и легко удаляется при необходимости, оставляя необходимый рисунок на поверхности подложки. При этом на формирование рисунка требуется всего несколько нанолитров вытравливающего реагента. В 1997 году импринт-литографическую технологию, позволяющую создавать рельефы с шириной каналов 10 нм, уже демонстрировали исследователи из Принстонского университета. Но из-за того, что при использовании данной технологии долгое время не удавалось выровнять слои полупроводника, о технологии на некоторое время забыли. Сейчас, когда специалисты компании Nanonex добились неплохих результатов выравнивания слоев при использовании обратного сканирующего туннельного микроскопа, о перспективах импринт-литографии заговорили вновь. Основное преимущество импринт-литографии перед аналогами - низкая себестоимость производства микропроцессоров - подкрепляется тем, что производительность полупроводниковой линии может достигнуть небывалых показателей, ведь для нанесения одного слоя требуется всего 20-30 с. Таким образом, за час может быть обработано до 3000 пластин.Кроме того, импринт-литография откроет новые горизонты для молекулярной электроники, позволив печатать интегральные схемы с точностью до нескольких молекул мономера.
Миниатюрность прежде всего!
Главный попутчик роста производительности современных процессоров - миниатюризация их составных частей. Однако необходимо добавить, что желание разработчиков уменьшать процессорные компоненты является еще и главной сложностью на этом пути. Например, разрабатывая 90-нм технологии, которые должны обеспечить нормальное функционирование процессоров Prescott, инженеры Intel вынуждены были преодолевать немало препятствий. Важный момент в том, что природа этих преград не в недостаточном разрешении производственного оборудования, а в невозможности изготовления столь малых транзисторов по традиционным технологиям. Так, при толщине барьера из четырех-пяти атомов диоксида кремния (это толщина слоя диэлектрика между затвором и каналом при использовании 90-нм масок) дали о себе знать утечки заряда из этой области, из-за чего управлять транзистором стало невозможно. Дело в том, что при уменьшении толщины слоя диэлектрика его изоляционные свойства значительно ухудшаются, и ток утечки, которым можно пренебречь при больших габаритах элементов транзистора, становится недопустимо большим.
Кроме того, на границе с затвором наблюдается иное явление, выражающееся в значительном повышении порогового уровня напряжения, необходимого для изменения состояния проводимости канала транзистора. Решение было найдено в виде металлического затвора. Применив новый сплав для изготовления затвора, исследователи компании Intel продемонстрировали высокопроизводительные КМОП-транзисторы со стеками high-k/metal-gate. Последние имеют физическую длину затвора 80 нм и толщину изолятора около 1,4 нм. По мнению разработчиков, эта технология позволит осуществить переход на технологические нормы 45 нм.
Впрочем, применение металлических затворов несколько замедлило скорость срабатывания транзисторов, из-за чего на первом этапе дальнейшая миниатюризация техпроцесса была сомнительна. Но и эту проблему удалось решить. Так, например, Intel в своем 90-нм техпроцессе применяет технологию "напряженного кремния", идея которого в том, чтобы растянуть кристаллическую решетку транзистора для увеличения расстояния между атомами и тем самым облегчить прохождение тока. При этом инженеры разработали два независимых способа "растяжения" кремния для разных типов транзисторов. Напомним, что существует два типа CMOS-транзисторов: n-типа, обладающие электронной проводимостью, и p-типа - с дырочной проводимостью. В NMOS-устройствах поверх транзистора в направлении движения электрического тока наносится слой нитрида кремния (Si3N4), в результате кремниевая кристаллическая решетка "растягивается". В PMOS-устройствах "растяжение" достигается за счет нанесения слоя кремний-германия (SiGe) в зоне образования переносчиков тока - здесь решетка "сжимается" в направлении движения электрического тока, и потому "дырочный" ток течет свободнее. В обоих случаях прохождение тока значительно облегчается: в первом случае - на 10%, во втором - на 25%. Сочетание же обеих технологий дает 20-30%-ное ускорение протекания тока.
А дальше?
Вот в принципе и все, что ожидает нас в году текущем. Рано говорить о 2005-м, ведь конвергенция все набирает обороты, а закон Мура все еще действует. Хотя в принципе уже очевидно — прирост частоты и увеличение кэша не приносит должного прироста производительности, так что компании решили сделать ставку на технологии. Ведь микроархитектуру нельзя усовершенствовать до бесконечности, да и нет в том смысла. Несомненно, будущее за интеграцией различных технологий и возможностей в чипы. Так, компания Intel в серверном секторе делает ставку на многоядерность, а в настольном сегменте – на многопоточность. Компания AMD же, не желая вкладывать огромные инвестиции в подобные исследования, делает ход конем: повсюду продвигает технологию производства SOI и ставит на расширение микроархитектуры до 64 разрядов, а также на шину HyperTransport.
Далее, в первом полугодии 2005-го, ядро Paris будет плавно заменено аналогичным со схожими параметрами, только выполненным по технологии 0,09 мк, имеющим кодовое наименование Victoria. Впрочем, не исключено, что оно появится раньше – в конце текущего года, если того потребует рынок. Во втором полугодии его сменит чип Palermo. Мобильный Athlon 64 на ядре Odessa будет заменен на аналогичное под названием Oakville, видимо, с увеличенным объемом кэш-памяти. Во втором полугодии мобильному Athlon XP-M на ядре Dublin придет на смену Trinidad. Серверное трио Athens/Troy/Venus заменит, соответственно, Egypt/Italy/Denmark, а SanDiego превратится в Toledo.
| I квартал 2004 |
II квартал 2004 |
III квартал 2004 |
IV квартал 2004 |
1 полугодие 2005 | 2 полугодие 2005 | |
| Opteron (Socket 940) | SledgeHammer 0,13 мк; 1 Mбайт L2 850 (2,4 ГГц) 250 (2,4 ГГц) 150 (2,4 ГГц) |
Athens/Troy/ Venus 0,09 мк; 1 Mбайт L2 852 (2,6 ГГц) 252 (2,6 ГГц) 152 (2,6 ГГц) Full & Low Power |
Egypt/
Italy/ Denmark 0,09 мк SOI |
|||
| Athlon 64 FX (Socket 940/ Socket 939) |
ClawHammer
0,13 мк; FX-53 |
ClawHammer 0,13 мк; 1 Mбайт L2 FX-53 (2,4 ГГц) Socket 939 |
San Diego 0,09 мк; 1 Mбайт L2 FX-55 (2,6 ГГц) |
Toledo
0,09 мк SOI |
||
| Athlon 64 (Socket Socket 939) | NewCastle 0,13 мк; 512 кбайт L2 3700+ (2,4 ГГц) 3400+ (2,2 ГГц) |
Winchester 0,09 мк; 512 кбайт L2 4000+ (2,6 ГГц) 3700+ (2,4 ГГц) |
||||
| Athlon 64 (Socket 754) | 3700+ (2,4 ГГц, 1 Mбайт L2) 3400+ (2,2 ГГц, 512 кбайт L2) |
|||||
| Athlon XP (Socket 754) | Paris 0,13 мк, SOI, 256 кбайт L2 Athlon XP 2800+ |
Paris 0,13 мк SOI; 256 кбайт L2 Athlon XP 3000+ |
Victoria
0,09 мк SOI; 256 кбайт L2 |
Palermo
0,09 мк SOI |
||
| Athlon 64 Mobile |
Athlon 64 Mobile
0,13 мк SOI |
Odessa
0,09 мк SOI |
Oakville
0,09 мк SOI |
|||
| Athlon XP-M |
Dublin
0,13 мк SOI, Socket 754, 256 кбайт L2 |
Trinidad
0,09 мк SOI |
Борьба противоположностей, или Микропроцессоры 2004 года
Александр Дудкин, «Экспресс-Электроника», #3/2004
Как известно, жизнь развивается по спирали, ну или по синусоиде, если хотите. Основа жизни – борьба противоположностей. И компьютерная отрасль не исключение. Какие бы хитрости для управления ценами и объемами производства компании ни применяли, технологический прогресс все равно не остановить. Ведь его существование основано на естественном стремлении человека к совершенствованию, унификации, упрощению (как ему кажется) жизни. В борьбе конкурентов и рождается истина, которая, в общем-то, выгодна не только конечному пользователю.
Самым знаменательным событием прошлого года стало появление 64-разрядных процессоров AMD, Opteron и Athlon 64/FX, и ответный ход Intel — процессор Intel Pentium 4 Extreme Edition. Периодические успехи обеих компаний, как правило, обусловлены не только удачным выпуском отдельных продуктов, но и поражением конкурентов. В любом случае, подобное волновое развитие дает перспективы и стимулирует как развитие технологий, так и скорейшее их применение.
Нетрудно заметить, с каждым годом данные процессы все ускоряются, и остановить их нельзя. Ведь не секрет, что за последние два года компания Intel «достала из рукава» немало козырей в виде технологий оптимизации микросхем, а вместе с ними и процессоров, и чипсетов (Hyper-Threading, PAT, Multiple VID). Разумеется, она еще более усердно взялась за создание новых технологий, чтобы дать будущее своим новым разработкам. Однако, углубившись в эти разработки, компания натолкнулась на очередную преграду – экстремально увеличилось тепловыделение микросхем, возникли проблемы с дальнейшим уменьшением размеров транзисторов. Следовательно, перспективным технологиям производства транзисторов 65 и 32 нм предстоит пережить еще немало кризисов перед тем, как они увидят свет. Вероятно, и AMD столкнулась с определенными технологическими проблемами при разработке будущих технологий, но об этом компания умалчивает.
На фоне таких событий сформировались две противостоящие концепции.
В понимании компании Intel конвергенция на данный момент коснется лишь сетевой компоненты развития микросхем. Процессоры же пока подлежат только «мобилизации», в то время как серверные функции процессоров должны принадлежать исключительно серверным процессорам, а обычным пользователям хватит стандартных, базовых и мультимедийных функций. Иными словами, 64-разрядные технологии у пользователя «на столе» появиться не должны. В принципе это справедливо, но тогда не совсем понятно будущее таких процессоров. Хотя компания AMD считает, что самый оптимальный путь развития микропроцессорных технологий — внедрение 64-битных технологий везде и подряд, почти за одни и те же деньги. Пример тому — ее новые процессоры Athlon 64 и Athlon 64 FX 51 для настольных компьютеров. Только опять же непонятно — чем все это закончится? Более того, понимая неустойчивость подобного положения, обе компании начали искать возможные методы дополнительного внедрения своих технологий. Например, Intel видит будущее за интеграцией сетевых возможностей в ее процессоры. Короче говоря, делает их более «интеллектуальными». По мнению Сунлиня Чжоу, генерального менеджера подразделения Intel Technology Manufacturing Group, возможности нанотехнологий велики и еще 10-15 лет кремниевые технологии будут актуальны. Далее вероятен переход на углеродные нанотрубки, но все это пока весьма туманно. Не менее важно понимать, что в борьбе «за место под солнцем» еще более актуальна маркетинговая политика компаний. К примеру, в борьбе за российского потребителя, Intel буквально наводнила своими акциями крупные города России.
Так мы вошли в 2004 год. Прошедший год не принес особых потрясений. В отличие от 2003-го, роадмапы компаний на год текущий более открыты, так что теперь можно готовиться к гораздо более насыщенной «программе». Ну что ж, давайте посмотрим, чем грозит нам ближайшее будущее.
Мобильные процессоры
5 января 2004 года корпорация Intel официально представила новое семейство мобильных процессоров Celeron M, рассчитанных на использование в недорогих ноутбуках. Celeron M делает еще доступнее для покупателей удачную платформу Intel Centrino.
Процессор Celeron M построен на основе ядра Banias (0,13-мк техпроцесс) и имеет вдвое урезанный по сравнению с Pentium M кэш второго уровня объемом 512 кбайт. Чип поддерживает системную шину 400 МГц и обладает встроенной технологией DeeperSleep, позволяющей экономить электроэнергию в периоды бездействия системы. Пока выпускаются три варианта Celeron M: с тактовыми частотами 1,30 и 1,20 ГГц и стандартным энергопотреблением (напряжение ядра 1,365 В; тепловыделение — 24,5 Вт), а также с частотой 800 МГц и сверхнизким энергопотреблением (напряжение ядра 1,004 В, тепловыделение — 7 Вт). Новые чипы полностью совместимы с наборами логики для Pentium M семейства i855, а также с чипсетом i852GM. Оптовая цена при поставках партиями по 1000 штук Celeron M 1,30; 1,20 ГГц и 800 МГц составляет $134, $107 и $161 соответственно. К концу года планируется увеличить частоту Celeron M до 1,5 ГГц. Что ж, это ожидаемый шаг со стороны Intel, позволяющий еще больше сократить расход энергии аккумулятора портативных ПК.
Появился и новый чипсет линейки i855 — 855GME. В этом наборе микросхем реализованы новые энергосберегающие функции, которые можно задействовать при применении памяти DDR333. Также в чипсет входит усовершенствованный графический процессор, способный динамически снижать свою тактовую частоту при работе от батарей. Кроме того, 855GME может автоматически, в зависимости от освещенности, подстраивать режим работы подсветки, экономя до 25% потребляемой лампами энергии. На нынешний год намечен выпуск вариантов Centrino с поддержкой протоколов 802.11a/b и 802.11b/g.
Недавно компания VIA заявила о своем желании создать набор системной логики для платформы Centrino. Компания собирается выйти на этот рынок с двумя чипсетами: PN800 и PN880.
Заявлено, что они будут поддерживать оперативную память DDR400 и поставляться со встроенным графическим ядром Unichrome Pro с аппаратным декодером MPEG-4.
Процессор Pentium M второго поколения на основе ядра Dothan (системная шина 400 МГц) будет официально представлен во II квартале 2004 года, возможно, в мае. Первоначально планировалось объявить о новом чипе в феврале, однако специалисты Intel обнаружили в этой микросхеме недоработки, для устранения которых потребовалось время. По заявлению компании, такая отсрочка необходима из-за экономической нецелесообразности выпуска процессора в том виде, в каком он должен был предстать перед изначально. Эти чипы, выполненные по 0,09-мк технологии на ядре Dothan, сначала будут иметь тактовые частоты от 1,6 до 1,8 ГГц, а частота работы системной шины к I кварталу 2005 года достигнет 533 МГц. Энергопотребление, в зависимости от модификации, составит от 21 до 25 Вт. При производстве ядра Dothan также будет использоваться технология напряженного кремния, применяемая во всех процессорах Intel, изготовленных по 0,09-мк техпроцессу. Версия чипа с поддержкой системной шины 533 МГц будет потреблять уже 30 Вт энергии.
Стало известно, что во второй половине 2005 года должны появиться процессоры на ядре Jonah, созданные по 65-нм технологии. Энергопотребление чипов Jonah, по всей видимости, вплотную приблизится к отметке 50 Вт. Высокое энергопотребление будущих чипов Intel может подтолкнуть производителей портативных компьютеров к переходу на процессоры от сторонних изготовителей. Например, кристаллы Transmeta Efficeon, выполненные по 90-нм технологии, при сравнимых с Jonah тактовых частотах будут иметь энергопотребление около 25 Вт. Впрочем, скорее всего, к моменту появления чипов Jonah на рынке их характеристики изменятся в лучшую сторону. Крупнооптовая цена процессора Dothan с тактовой частотой 1,80 ГГц составит $637, с частотой 1,70 ГГц - $455, а с частотой 1,60 ГГц - $326. Двухгигагерцевый Pentium M ожидается не ранее начала 2005 года, а чип с частотой 2,13 ГГц – во II квартале.
На конец 2004 – начало 2005 года запланирован и переход на системную шину 533 МГц. Второе поколение платформы Centrino - Sonoma, в состав которой войдут чипы на ядре Dothan, набор логики Alviso GM и контроллер беспроводных сетей Intel Pro/Wireless 2200, появится к концу года.
Северный мост чипсета Alviso оснащен новым графическим ядром и имеет технологию динамического экрана, которая позволяет автоматически переходить в режим пониженного энергопотребления в зависимости от изображения на экране. Кроме того, чипсет Alviso поддерживает память DDR2 SDRAM. В качестве южного моста используется ICH6-M. Другие спецификации чипсета Alviso:
поддержка мобильных процессоров Intel на ядре Dothan;
Serial-ATA
PCI Express
поддержка ExpressCard формата "add-in";
интегрированный 7.1-канальный аудиокодек Azalia.
В январе Intel выпустила модуль беспроводной связи Pro/Wireless 2200GB. Новый модуль, известный под кодовым именем Calexico 2, позволяет подключаться к беспроводным сетям стандартов IEEE 802.11b/g. До недавнего времени в состав платформы Centrino входили только контроллеры Intel Pro/Wireless 2200 и Pro/Wireless 2200A, работающие в сетях стандартов 802.11b и 802.11a. В текущем году Intel планирует представить контроллер, способный поддерживать стандарты 802.11a/b/g. Цена одного модуля Pro/Wireless 2200GB при поставках партиями по 10000 штук составит около $25. С введением новых стандартов беспроводной связи платформа Centrino становится все более конкурентоспособной и занимает все большую долю рынка, которая еще в прошлом году перевалила рубеж 40%. Таблица 1. План выпуска мобильных процессоров Intel
| Цена | II квартал 2004 года | III квартал 2004 года | IV квартал 2004 года | I квартал 2005 года |
| $3000+ | 1,80 ГГц¶ | 1,80 ГГц¶ | 2,0 ГГц¶ | 2,13a ГГц |
| $2500+ | 1,70А¶; 1,70* | 1,70А¶; 1,70* | 1,80¶ | 2Аa, 2¶ |
| $2000+ | 1,60¶, 1,60* | 1,70А¶; 1,70* | 1,70A¶ | 1,87a, 1,80¶ |
| $1400+ | 1,50*, 1,40* | 1,60А¶, 1,60*, 1,50* | 1,60А¶, 150А¶ | 1,73a, 1,70А¶, 1,60Ba, 1,60А¶ |
| LV (с низким энергопотреблением) | 1,30 ГГц¶ | 1,30ГГц¶ | 1,40 ГГц¶ | 1,40+a, 1,40¶ |
| Ultra LV (cо сверхнизким энергопотреблением) | 1,0А¶, 1,0* | 1,0А¶, 1,0* | 1,10¶, 1,0А¶ | 1,10+¶, 1,0А¶+ |
| *-0,13-мк техпроцесс, кэш L2 - 1 Мбайт, шина 400 МГц (Banias) ¶-0,09-мк техпроцесс, кэш L2 - 2 Мбайт, шина 400 МГц (Dothan) a-0,09-мк техпроцесс, кэш L2 - 2 Мбайт, шина 533 МГц (Dothan) |
Эти чипы, рассчитанные на использование в ноутбуках класса "замена настольного ПК", будут иметь кэш-память объемом 1 Мбайт и системную шину 533 МГц. Первые модели станут работать на частоте 3,46 ГГц, которая к концу 2004 года вырастет до 3,73 ГГц. Вот только не понятно, для чего в ноутбуках нужны такие высокопроизводительные процессоры, ведь потреблять энергию они будут «по-десктопному». На проходившем в сентябре 2003 года в Сан-Хосе IDF компания Intel обнародовала планы по выпуску новых мобильных процессоров и оборудования для беспроводных сетей. Речь идет о новых процессорах серии XScale, основанных на ядре ARM и использующихся в КПК на платформе PocketPC и некоторых смартфонах. В мае запланировано появление процессоров PXA263 под кодовым названием Bulverde, они будут иметь частоты 412 и 540 МГц. В новых процессорах реализовано сразу несколько важных нововведений, призванных повысить производительность мобильных устройств (в том числе в мультимедийных приложениях) и в то же время способствовать снижению их энергопотребления. Последнюю задачу должна решать технология Wireless SpeedStep — с ее помощью можно динамически управлять напряжением питания и тактовой частотой процессора. По сравнению с используемой сейчас технологией Intel Dynamic Voltage в Wireless SpeedStep добавлены три новых режима энергосбережения, что позволяет более гибко управлять производительностью и потреблением энергии. Для повышения производительности в мультимедийных приложениях новые чипы XScale используют набор дополнительных инструкций Wireless MMX, созданных на базе технологии MMX, реализованной еще в первом поколении процессоров Pentium. Применение Wireless MMX позволит повысить скорость работы с двухмерной и трехмерной графикой, а также со сжатым видео формата MPEG-4. Еще одно мультимедийное новшество в Bulverde – технология QuickCapture. По своей сути, QuickCapture - это интерфейс для подключения к мобильному устройству внешних фото- или видеокамер. По заверениям Intel, обеспечиваемой QuickCapture пропускной способности достаточно для нормального обмена информацией с 4-мегапиксельным фотоаппаратом или для записи видео со скоростью до 40 кадр/с. Помимо процессоров XScale на новом ядре Bulverde, компания намерена выпустить очередной процессор для смартфонов и коммуникаторов на ядре Manitoba.Модель PXA800EF отличается от прежних "сотовых" процессоров Intel поддержкой протокола EDGE. Ну что ж, такая активность компании Intel еще раз подтверждает данные аналитиков IDC о том, что с расширением количества продуктов Intel и наступлением на новые рынки, все больше сокращается рыночная доля компании AMD, несмотря на достаточно успешный IV квартал прошлого года.
"Настольные" процессоры
Несмотря на все слухи и разногласия о том, что Pentium 4 Extreme Edition должен был стать не самостоятельной линейкой процессоров, а одиночной моделью, призванной составить должную конкуренцию хиту прошлого года – процессору Athlon 64 FX, 2 февраля прошла официальная презентация этого "игрового" процессора с тактовой частотой 3,40 ГГц. Как и его предшественник, работающий на частоте 3,20ГГц, он выполнен на ядре Gallatin по 0,13-мк технологии. Новинка оснащена кэш-памятью третьего уровня объемом 2 Мбайт, второго уровня объемом 512 кбайт, L1 для данных – 8 кбайт и кэш-памятью для микроинструкций на 12000 микрокоманд. Ядро имеет площадь 237 мм2 и 178 млн транзисторов. Причем он, как и простой Northwood, предназначен для работы с чипсетами i865/i875 и имеет системную шину 800 МГц. Цена этого чипа составляет $999, а младшая модель будет продаваться за $925. В начале 2004 года планируется появление этого процессора, выполненного по 0,09-мк техпроцессу с частотой 4 ГГц. Чип, пока известный под кодовым наименованием Potomac, будет иметь кэш L3 объемом 4 Мбайт.
Последним настольным Pentium 4 на ядре Northwood стала модель с тактовой частотой 3,40 ГГц и 512 кбайт кэш-памяти L2. В тот же день был представлен процессор Pentium 4 на основе ядра Prescott (0,09-микронный техпроцесс) с кэшем второго уровня объемом 1 Мбайт. Интересно, что новые чипы не получили какого-либо нового названия, а сохранят старое — Pentium 4, в то время как предлагалось название Pentium 4 SSE3. На базе нового ядра пока будут выпускаться процессоры с частотами от 2,80 до 3,40 ГГц. Кстати, младшая модель имеет шину 533 МГц и маркируется как 2,80А, чтобы отличить ее от модели с такой же частотой и шиной на ядре Northwood. Модели с шиной 800 МГц и частотами 2,80, 3, 3,20 и 3,40 ГГц имеют индекс «E» в маркировке — так их можно отличить от моделей с той же частотой и шиной на ядре Northwood. В III квартале 2004 года будет выпущен Pentium 4 с тактовой частотой 3,80 ГГц, а к концу года можно ожидать и покорения рубежа в 4 ГГц.
Основными особенностями нового ядра стал его полный редизайн, удлиненный до 31 стадии конвейер, новая методика изготовления с применением технологии напряженного кремния и диэлектриком CDO в межсоединениях, а также 13 новых инструкций (SSE3).
Кроме того, улучшены технология Hyper-Threading, прогнозирование переходов, предварительная выборка данных в кэш и управление питанием. Также ускорены операции умножения целых чисел, введены дополнительные буферы записи. В новинке должна быть поддержка 64-битных инструкций, которые не совместимы с 64-битными инструкциями AMD и заблокированы, по крайней мере, пока. Предусмотрена технология аппаратного шифрования данных La Grande, но программная поддержка появится позже. Новый кристалл имеет площадь 112 мм2 и содержит 125 млн транзисторов. В связи с этим изменился и терморежим нового процессора – спецификация FMB 1.5. Термопакет теперь расширил свои диапазоны: старшая модель будет иметь тепловыделение 103 Вт. Однако из-за этого возникают проблемы совместимости с большинством имеющихся системных плат. Цены на процессоры этой линейки колеблются от $163 до $417, но вскоре, для стимуляции спроса, они сравняются с ценами на линейку Northwood.
К середине года Intel изменит форм-фактор процессоров на ядре Prescott с Socket 478 на Socket 775 (Socket T). Пока что удается использовать старый корпус, за счет того, что с 24 ноября 2003 года все процессоры Pentium 4 с 800 МГц шиной выпускаются в измененном корпусе. Степпинг ядра Northwood сохранился (D1, CPUID 0F29h), а вот сама упаковка изменилась. Число слоев микроплаты процессора увеличилось с 6 до 8, высота процессора выросла с 3,46 до 3,75 мм, а на обратной стороне вместо привычных 12 конденсаторов установлено целых 30! Процессоры Prescott с текущим степпингом C0 еще совместимы с некоторыми имеющимися материнским платами, но их частота не превысит 3,6 ГГц. Скорее всего, степпинг C1 будут иметь процессоры Prescott в исполнении Socket T (LGA 775). И только тогда они смогут перешагнуть барьер в 4 ГГц. Поскольку в ближайшее время в продаже появятся в основном модели с низкой частотой, проблемы пиковых токов в топовых моделях не возникает. Необходимость в технологии «без ножек», по-видимому, продиктована желанием избавиться от паразитных емкостей между контактами. Появление бюджетных Celeron на ядре Prescott (с частотами 2,80; 2,60 и 2,53 ГГц) ожидается во II квартале 2004 года.
Естественно, они изготовлены по 0,09- мк технологии, имеют 256 кбайт кэша второго уровня и поддерживают системную шину 533 МГц.
Будущее процессоров Pentium – это четвертое поколение архитектуры NetBurst – процессор, известный под кодовым названием Tejas. Ранее его выпуск планировался на конец 2004-го, затем был перенесен на I квартал 2005-го, а сейчас стало известно, что он появится не раньше II квартала 2005 года. В I же квартале 2005 года, скорее всего, будет выпущена 4,2-ГГц версия процессора Prescott.
Спецификации Tejas:
90 нм/65 нм техпроцесс;
улучшенная Hyper-Threading;
120-140 мм2 площадь кристалла (90 нм)/80-100 мм2 площадь кристалла (65 нм);
1 Mбайт кэш L2, 24 кбайт кэш L1, 16K uOps Trace Cache;
8 новых инструкций;
800/1066 МГц FSB;
775 LGA (Land Grid Array) Package.
Опытные образцы Tejas пока имеют частоты от 2,80 ГГц. Они отличаются повышенным тепловыделением – порядка 150 Вт. Все образцы Tejas выполнены в новом корпусе LGA-755, у которого отсутствуют традиционные "ножки", поэтому для крепления данного чипа необходим новый разъем со специальным прижимным устройством - рамкой.
Новые чипсеты Grantsdale и Alterwood для Pentium 4 на ядре Prescott появятся во II квартале 2004 года, в их состав войдет доработанный южный мост ICH6W (кодовое название — Caswell) со встроенным контроллером стандарта IEEE 802.11b/g. Кроме того, южный мост ICH6W будет иметь встроенный 4-канальный контроллер Serial ATA, поддержку до четырех устройств с интерфейсом PCI Express, звуковое ядро Azalia и некоторые другие интересные возможности. Сначала ожидаются чипсеты i925X (Alderwood), i915P (Grantsdale-P), i915G (Grantsdale-G). В III квартале появятся i915GV (Grantsdale-GV), i910GL (Grantsdale-GL) — облегченные модели со встроенной графикой, а LakePort-P, LakePort-G — во II квартале 2005 года. Все модификации i915 рассчитаны на процессоры без "ножек" для перспективного разъема Socket 775, а 910GL — для чипов на привычном Socket 478.
Планы AMD
Компания AMD настроена оптимистично и готовит к выходу на рынок большое количество новинок. Хотя будут ли эти новинки такими уж революционными?
Нежелая вкладывать еще большие средства в оптимизацию 32-битных технологий, компания обратилась к 64-разрядным системам. По мнению руководства, дни 32-битных процессоров сочтены. В компании считают, что к середине-концу 2005 года 64-битные процессоры полностью вытеснят 32-битные. Однако AMD продолжит продавать 32-битные процессоры ровно столько времени, сколько они будут пользоваться спросом у покупателей. По сути дела, компания создала себе очень выгодное положение, при котором может не беспокоиться о будущем своих процессоров, ведь все 64-битные процессоры, как для настольных систем, так и для серверов, изготовляются на одних и тех же производственных мощностях по одинаковым технологиям. Существующие же 32-разрядные процессоры не требуют от компании особых затрат, поскольку выпускаются по отлаженным технологиям. В то же время такой подход сдерживает компанию от технологического развития и мешает внедрять новые технологии — AMD старается путем наименьших затрат выжать все доступное из существующих. В конечном счете, это препятствует развитию новых архитектур и росту частоты ее процессоров. Ведь в рамках сегодняшней архитектуры K7-K8, которая имеет много «узких мест», очень проблематично увеличить число ступеней конвейера и исполнительных блоков, а также объем кэш-памяти.
Теряя процентную долю рынка, AMD не раз пересматривала свой будущий роадмэп. В связи с этим несколько раз за последние месяцы 2003 года изменялись планы и сроки выпуска процессоров.
Дела с переходом на 0,09-мк техпроцесс у компании идут проблематично, особенно учитывая, что выполняться процессоры должны по технологии SOI. Эта технология очень перспективна и дает много преимуществ в борьбе с утечками тока в транзисторах, однако сложна в исполнении, процент выхода годных кристаллов не высок. AMD объявила, что вынуждена перенести сроки начала массового производства 90-нм микропроцессоров на два-три месяца.
Теперь чипы Opteron, выполненные по 90-нм технологическому процессу мы сможем приобрести лишь во второй половине 2004 года. Большинство остальных процессоров пока будет производиться по технологии 0,13 мк. Генеральный директор компании Гектор Руиз отметил, что AMD просто не поспевает за собственными планами. Для одного из технологических лидеров индустрии это недопустимо. Тем не менее, нынешний год компания начала активно — 6 января был анонсирован выпуск сразу целой линейки процессоров Athlon 64 для настольных и мобильных систем. В список вошли: Athlon 64 3400+, 3200+, 3000+; DTR Athlon 64 3400+, 3200+, 3000+, 2700+;
Mobile Athlon 64 3200+, 3000+, 2800+. В итоге на сегодняшний день характеристики и цены на всю линейку процессоров Athlon 64 (за исключением FX-51) следующие (см. таблицу 2). Таблица 2. Характеристики процессоров линейки Athlon 64.
| Процессор | Модель | Частота, ГГц | Кэш L2, кбайт | Цена, $ |
| Athlon 64 | 3400+ | 2,2 | 1024 | 417 |
| 3200+ | 2,0 | 1024 | 278 | |
| 3000+ | 2,0 | 512 | 218 | |
| DTR Athlon 64 | 3400+ | 2,2 | 1024 | 417 |
| 3200+ | 2,0 | 1024 | 278 | |
| 3000+ | 1,8 | 1024 | 218 | |
| 2700+ | 1,8 (?) | 512 (?) | – | |
| Mobile Athlon 64 | 3200+ | 2,2 | 1024 | 293 |
| 3000+ | 1,8 | 1024 | 233 | |
| 2800+ | 1,6 | 1024 | 193 |
Причем сначала появится версия Athlon 64 FX-53 под разъем Socket 940, а затем уже, через несколько месяцев будет введен разъем Socket 939. Интересно, что Athlon 64 FX-53 станет единственным настольным процессором с разъемом Socket 940. Вот только интересно, зачем же тогда придумывать такой разъем, который в дальнейшем будет использоваться только в семействе Opteron? Ответ прост: FX-53 опять будет обычным Opteron, маркированным как процессор для «стола» с «залоченной» мультипроцессорностью. Примерно в мае должны появиться процессоры Athlon 64 3700+ и 3400+ в исполнении Socket 754. Это будут первые и одновременно последние 64-битные процессоры с разъемом Socket 754. Характеристики данных процессоров таковы: Athlon 64 FX-53 (ClawHammer): 0,13-мк техпроцесс с SOI, Socket 940 (первоначально)/Socket 939, тактовая частота 2,4 ГГц, поддержка двухканальной памяти DDR400, 1 Мбайт кэша L2; Athlon 64 3400+ (NewCastle): 0,13-мк техпроцесс с SOI, Socket 939 / Socket 754, тактовая частота 2,2 ГГц, поддержка одноканальной памяти DDR400, 1 Мбайт кэша L2; Athlon 64 3700+ (NewCastle): 0,13-мк техпроцесс с SOI, Socket 939 / Socket 754, тактовая частота 2,4 ГГц, поддержка одноканальной памяти DDR400, 1 Мбайт кэша L2. Со II квартала 2004 года ожидается перевод всех настольных 64-разрядных процессоров AMD на разъем Socket 939, причем все эти чипы станут поддерживать двухканальную оперативную память. Топовые модели с индексом FX будут, как и прежде, иметь 1 Мбайт кэш-памяти, а "обычные" модификации — кэш-память объемом 512 кбайт. Наличие в таблице двух процессоров 3700+ объясняется просто: эти чипы должны производиться по 0,09-мк технологии, однако пока неизвестно, удастся ли AMD выпустить такой процессор в срок, поэтому он может появиться как во II, так и в IV квартале 2004 года. Планируется, что III квартал будет посвящен подтягиванию «хвостов»: компания займется своим low-end. К этому времени процессоры Duron на своем последнем ядре Applebred уже сойдут с арены, а процессор Athlon XP, сменив Duron, перейдет в low-end.
В III квартале появится новое ядро для Athlon XP, имеющее кодовое наименование Paris. Это совершенно новое ядро, изготовленное по технологии SOI с применением 0,13-мкм технорм. Этим объясняется малый объем кэша L2 – всего 256 кбайт. Процессор получит разъем Socket 754 и в целом будет похож на 64-битные процессоры. Ходят слухи, что ядро Paris сможет поддерживать 64-битные инструкции х86-64 (AMD64), но они просто будут в нем отключены. Очень похожая ситуация складывается с Prescott, компания Intel уже подтвердила наличие в нем 64-битных расширений, так что есть основания этим слухам доверять. Первым процессором данной серии станет Athlon XP 2800+. В этом же квартале будет выпущен первый процессор AMD, изготовленный по технологии 0,09 мкм SOI — мобильный процессор Athlon 64 Mobile под кодовым именем Odessa. Этот процессор получит кэш 1 Мбайт, как самый заправский 64-битный процессор, и уже традиционную технологию PowerNow!. Завершающий квартал года будет исключительно «горячим» на новинки. AMD приступит к массовому производству чипов серий Opteron 100 (Venus), 200 (Troy) и 800 (Athens), а также процессоров Athlon 64 Winchester и Athlon 64 FX San Diego, производящихся по технологии 0,09 мк. В IV квартале текущего года планируется выпустить чипы Athlon 64 FX-55 и Athlon 64 4000+, с тактовой частотой 2,6 ГГц. Модель 3700+, которая появится чуть позже, будет работать на тактовой частоте 2,4 ГГц. Winchester будет иметь кэш L2 объемом 512 кбайт, а его старший брат, теперь больше напоминающий линейку Athlon 64, а не Opteron, как прежде, – San Diego – 1 Мбайт. Оба выполнены в конструктиве Socket 939. С этого времени производство всех 64-разрядных процессоров перейдет на техпроцесс 0,09 мк SOI. Также в IV квартале ожидается появление двух 32-разрядных процессоров 2800+ и 3000+ семейства Athlon XP, рассчитанных на установку в Socket 754. Тактовая частота данных чипов пока не определена, однако, по всей видимости, в этих микросхемах, как и в Athlon 64, будет встроен контроллер оперативной памяти.
Эту линейку low- end планируется выпускать по старой технологии 0,13 мк SOI и кэшем L2 256 кбайт. Точной копией этого ядра для мобильных систем станет ядро Dublin. Этот процессор будет иметь 256 кбайт кэша L2 на борту и производиться по 0,13-мк SOI технологии. Процессор сможет поддерживать технологию энергосбережения PowerNow!, но едва ли будет нацелен на рынок ноутбуков, так как его энергопотребление составит порядка 62 Вт. Dublin будет иметь одноканальный контроллер памяти DDR400. Вероятно, процессор будет поддерживать инструкции AMD64, но пока это лишь предположения. Возможно, Dublin найдет применение в мобильных компьютерах, DTR- и Barebone-системах. Пока известно только, что эти Athlon XP будут выпускаться с рейтингом 3000+ и 3200+. Частоты и цены на них остаются загадкой. Ну а в сегменте HPC в IV квартале нас ожидает настоящий бум. Линейка SledgeHammer ,будет разделена на три самостоятельные линейки продуктов. Впрочем, данные продукты будут совершенно идентичны, за исключением того, что три новых ядра предназначены, соответственно, для восьми-, двух- и однопроцессорных систем на базе процессоров Opteron. Итак, названия трех новых ядер следующие — Athens, Troy и Venus. Все они, конечно, будут выполнены по технологии 0,09 мк SOI. Чипы будут обладать кэшем L2 объемом 1 Мбайт, что не так уж и много. За полгода частота кристаллов вырастет всего лишь на 200 МГц – до 2,6 ГГц. Серии процессоров все также будут именоваться трехзначными цифрами, где первая из них означает количество процессоров в системе с данной моделью. К концу года соответственно выйдут модели 852, 252 и 152. Также планируется выпуск этих же чипов для систем с пониженным энергопотреблением. Пока AMD не сообщает каких-либо технических подробностей о новых чипах. Известно лишь, что энергопотребление модификации Opteron "средней мощности" составит около 55 Вт, а процессору с низким энергопотреблением потребуется примерно 30 Вт. Тактовая частота экономичных процессоров будет, очевидно, ниже, чем у стандартных версий Opteron.
Основной нишей для новых процессоров должны стать блейд-серверы и системы хранения данных, где требования к энергопотреблению и тепловыделению особенно строги. Во всех планах обоих производителей прослеживаются черты «борьбы с природой». Постепенно увеличивается энергопотребление процессоров, а вместе с ним растет и количество ножек в корпусах CPU. Так гнездо Socket 754 будет использоваться для недорогих и мобильных платформ. Процессоры на ядре Paris и Victoria станут конкурировать с Celeron на ядре Northwood-128 и Prescott-256. Socket 940 - бесперспективная платформа. После освоения AMD 0,09-мкм техпроцесса Athlon 64 перейдет с Socket 940 на Socket 939. Так что на сегодняшний день лучше воздержаться от покупки соответствующей материнской платы. И еще забавный факт: AMD, видимо, насмотревшись, как Intel дает имена своим кристаллам, решила присваивать своим ядрам названия исторических городов мира. К чему бы это? Интересно также, что AMD намерена окончательно порвать со своей системой рейтинговой оценки производительности процессоров, называемой TPI. Этот проект было решено свернуть, поскольку он не оправдал возложенных на него надежд, поэтому во всех 64-битных процессорах данный рейтинг уже больше не применяется.
Планы Intel
Прежде всего давайте посмотрим на планы Intel. Ибо их у компании громадье, причем, как правило, связанных с новыми технологиями. Итак, год компания активно начала еще в январе, представив очередной ряд мобильных процессоров, в которых нашли развитие идеи, воплощенные в последнем Intel Celeron. Celeron 2,80 ГГц – это обычный процессор Celeron на ядре Northwood с шиной 400 МГц. Он имеет кэш второго уровня объемом 128 кбайт, напряжение питания 1,525 В и рассеиваемую мощность 68,4 Вт.
Серверные процессоры
В этом сегменте компания Intel будет менее активна. Во II квартале должны выйти давно обещанные чипы под кодовым названием Madison 9M. Это обыкновенный чип Madison с 9 Мбайт кэша L3 и тактовыми частотами от 1,5 ГГц. Такой процессор будет содержать более 500 млн транзисторов. На III квартал 2004 года запланирован выпуск чипов Itanium нового поколения. Новые процессоры, получившие кодовое название Fanwood, будут поддерживать системную шину, работающую на частотах 400 и 533 МГц; кроме того, ожидается появление чипа Fanwood с пониженным энергопотреблением (LV).
Выпуск следующего поколения 64-разрядных двухпроцессорных серверных чипов под названием Montecito перенесен с 2004 на начало 2005 года. Это следующее поколение процессора Itanium 2, которое позиционируется как замена 32-битным Xeon. Похоже, данный процессор, будет производиться по технологии 0,09 мкм и содержать два процессорных кристалла в одном корпусе. У каждого из них предусмотрен собственный кэш L1, L2 и L3. А весь конструктив будет содержать около 1 млрд транзисторов!
Именно в этих процессорах дебютирует новая технология внутренней "распределительной" (arbiter) шины, предназначенной для управления двумя и более процессорными ядрами в едином корпусе – нечто вроде общего процессорного системного интерфейса с пропускной способностью до 6,4 Гбайт/с и производительностью до 400 млн транзакций в секунду. По словам представителей компании, применение такой шины позволит удвоить объем кэш-памяти, поддерживаемой каждым процессором.
Montecito будет иметь 24 Мбайт кэша 3-го уровня, а также два ядра с возможностью многопоточного режима. Будущий последователь Montecito, процессор Tanglewood будет иметь более двух ядер с возможностью установки до 6 Мбайт кэша и пропускной способностью системной шины 6,4 Гбайт/с. Montecito позиционируется как решение для работы с большим количеством данных, что и нашло отражение в размере кэша. Отличительная черта серверов на базе Itanium — возможность восстановления после сбоя (ERP), что позволяет говорить о применимости их для хранения и обработки баз данных.
Согласно заявлениям представителей Intel, в течение второй половины 2003-го объем продаж Italium 2 увеличился на 65% по сравнению с первым полугодием. Следует отметить положительную динамику роста продаж продукции Intel на корпоративном рынке, составляющем 80% от общего рынка серверов, где главным конкурентом Intel является Sun Microsystems.
Как известно, компания Intel планирует и дальше активно использовать 32-разрядные процессоры не только для настольных компьютеров, но и для серверов. Nocona – это следующее ядро для процессоров Xeon MP, которое является аналогом Prescott для «стола». Прежде всего, стоит отметить преимущества ядра Nocona по сравнению с предшественником, ядром Prestonia:
кэш первого уровня увеличен с 12 до 16 кбайт;
Trace-кэш увеличен с 12 до 16 кбайт;
новый механизм предсказания ветвлений;
поддержка набора инструкций SSE3;
улучшенная реализация технологии Hyper-Threading;
800 МГц шина FSB;
0,09-мк техпроцесс.
Процессоры Xeon для двухпроцессорных серверов будут именоваться как Xeon 1M и стартуют с частотами от 2,8 до 3,6 ГГц. Цены на них таковы: Xeon 1M 3.60 ГГц - 851$, Xeon 1M 3,40 ГГц - 690$, Xeon 1M 3,20 ГГц - 455$, Xeon 1M 3,00 ГГц - 316$, Xeon 1M 2,80 ГГц - 209$. Серверный процессор Xeon на основе ядра Nocona, выпущенный по 0,09-микронному техпроцессу, будет представлен не ранее II квартала этого года. Тактовая частота процессора составит от 2,80 до 3,60 ГГц, он будет работать с набором системной логики Lindenhurst (Intel E7710), имеющим двухканальный контроллер памяти DDR333/DDR400 с поддержкой ECC, шину PCI Express x8 и PCI Express x4 и Intel E7515 с теми же функциями, что и E7710, но поддерживающим и шину PCI Express x16. В III квартале ожидается презентация Nocona c пониженным энергопотреблением: этот процессор, предназначенный для блейд-серверов, будет иметь тактовую частоту 2,80 ГГц. В IV квартале Xeon на ядре Nocona получат тактовые частоты от 3,80 ГГц и смогут работать с системной шиной 800 МГц. Преемники процессоров этих Xeon и Xeon MP, чипы с кодовыми названиями Jawhawk и Potomac, а также чипсеты для них (Lindenhurst и TwinCastle) появятся на рынке не ранее I квартала 2005 года. Процессоры Xeon MP с тактовой частотой 3,2 ГГц и кэшем L3 2 Мбайт (оптовая цена - $1040), а также с тактовыми частотами 2,8 и 2,4 ГГц и кэшем L3 1 Мбайт (оптовые цены - $450 и $336 соответственно) будут представлены в I квартале 2004 года.Во II квартале ожидается перевод Xeon на системную шину 800 МГц.
Позже Intel планирует объединить процессоры Xeon и Xeon MP в одно семейство. В конце этого года компания представит три процессора Xeon с 4 Мбайт кэша L3 (частоты 3,0, 2,7 и 2,2 ГГц). Цена этого процессора составит порядка $3700.
Технологии и рынок
Сейчас на рынке микропроцессоров наблюдается интересная тенденция: с одной стороны производители стараются как можно быстрее внедрить новые техпроцессы и технологии в свои новинки, с другой — искусственно сдерживается рост частот процессоров. Во-первых, ощущается неполная готовность рынка к очередной смене семейств процессоров, а фирмы пока не получили достаточно прибыли от объема продаж производящихся сейчас CPU – запас еще не иссяк. Заметно превалирование значимости цены готового изделия над всеми остальными интересами компаний. Во-вторых, заметное снижение темпов «гонки частот» связано с необходимостью внедрения новых технологий, которые реально увеличивают производительность при минимальном объеме технологических затрат. Как уже было сказано, при переходе на новые техпроцессы производители столкнулись с серьезными проблемами.
Технологическая норма 90 нм оказалась достаточно высоким барьером для многих производителей чипов. Это подтверждает и компания TSMC, выпускающая чипы для AMD, nVidia, ATI, VIA. Долгое время ей не удавалось наладить изготовление чипов по технологии 0,09 мк, что привело к низкому выходу годных кристаллов. Это одна из причин, из-за которой AMD долгое время откладывала выпуск своих процессоров по технологии SOI. Суть в том, что именно на данной размерности элементов стали сильно проявляться всевозможные, ранее не столь ощутимые негативные факторы, — токи утечки, большой разброс параметров и экспоненциальное повышение тепловыделения. Но разберемся по порядку.
Как известно, существует два тока утечки: ток утечки затвора и подпороговая утечка. Первая вызвана самопроизвольным перемещением электронов между кремниевым субстратом канала и поликремниевым затвором. Вторая – самопроизвольным перемещением электронов из истока транзистора в сток. Оба эффекта приводят к необходимости поднимать напряжение питания для управления токами в транзисторе, что негативно сказывается на тепловыделении. Уменьшая размеры транзистора, мы прежде всего уменьшаем его затвор и слой диоксида кремния (SiO2), который является естественным барьером между затвором и каналом.
С одной стороны, это улучшает скоростные показатели транзистора (время переключения), но с другой – увеличивает утечку. То есть получается своеобразный замкнутый круг. И переход на 90 нм – это очередное уменьшение толщины слоя диоксида и одновременно увеличение утечек. Борьба с утечками, опять же, приводит к увеличению управляющих токов и, соответственно, к значительному повышению тепловыделения. А в результате оба конкурента вынуждены отложить внедрение нового техпроцесса. Один из возможных выходов – технология SOI (кремний на изоляторе), которую недавно внедрила компания AMD в своих 64-разрядных процессорах. Впрочем, это стоило ей больших усилий и преодоление немалых трудностей. Зато сама технология предоставляет множество преимуществ при сравнительно малом количестве недостатков. Но сейчас речь о другом. И наконец, третья причина, способствовавшая замедлению темпов роста частот – низкая активность конкурентов на рынке. Пожалуй, можно сказать, что каждый занимался своими делами. AMD проводила повсеместное внедрение 64-битных процессоров, для Intel это был период усовершенствования нового техпроцесса. По всей видимости, 2004 год принесет нам большое количество новостей из области технологий, ведь именно в нынешнем году обе компании должны перейти на технологические нормы 90 нм. Но это вовсе не означает стремительного роста частот процессоров, скорее наоборот. Сначала на рынке будет наблюдаться затишье: конкуренты начнут выпускать CPU по новым техпроцессам, но со старыми частотами. По мере освоения процесса производства начнется некоторый рост частоты чипов. Скорее всего, он будет не столь заметен, как прежде. К концу 2004 года компания Intel ожидает покорение вершины в 4 ГГц, а то и более. Процессоры компании AMD будут идти с некоторым отставанием по частоте, которое, в общем-то, не столь заметно сказывается на производительности, как особенности микроархитектуры.
AMD Toledo: SUMA, SRI и интегрированный Northbridge
Архитектура AMD K8 не просто отличается от «интеловской»: она концептуально иная, поскольку в ней нет какого-то выделенного центра. Каждый из процессоров архитектуры AMD64 является независимой и «самодостаточной» единицей, объединяющей в себе почти всю функциональность северного моста традиционных наборов системной логики. Это началось с одноядерных процессоров, а с появлением двухъядерников «обросло» новыми отличиями. Взглянем на блок-схему двухпроцессорной системы на двухъядерных AMD Opteron.

Увеличить
Пример двухпроцессорной двухъядерной системы на Opteron 2xx и чипсете AMD 81xx. HT обозначает HyperTransport
Оригинал статьи на "www.ferra.ru"
| Содержание | Часть 3 |
Двухъядерные процессоры Intel и AMD: теория
Сергей Озеров, Алекс Карабуто
Тестовая лаборатория Ferra Недавно два микропроцессорных гиганта – Intel и AMD – дружно выпустили свои первые двухъядерные процессоры, которые уже успели наделать много шума. Новые микропроцессоры получились не просто интересными, но представляют собой весьма многогранные продукты, тщательное исследование которых не может ограничиться одним-двумя обзорами, написанными по горячим следам. Мы постараемся рассказать об этих новых продуктах более подробно и, по возможности, с разных сторон...
Итак, недавно два микропроцессорных гиганта – Intel и AMD – дружно выпустили свои первые двухъядерные процессоры, которые уже успели наделать много шума. Эти продукты стали не просто очередными конкурирующими новинками от лидеров отрасли персональных компьютеров (как это часто бывало в последние годы), но возвестили своим появлением о начале (не побоимся громких слов) целой эры (в тактическом и даже стратегическом понимании) «настольных» вычислений, очередного витка проникновения профессиональных технологий в потребительский сегмент. Новые микропроцессоры получились не просто интересными, но представляют собой весьма многогранные продукты, тщательное исследование которых не может ограничиться одним-двумя обзорами, написанными по горячим следам (каковыми можно признать большинство статей с тестами, спешно выполненными за несколько дней после получения сэмплов). Мы постараемся рассказать об этих новых продуктах более подробно и, по возможности, с разных сторон, не ограничивая себя жесткими временными рамками. Впрочем, мы также приглашаем к обсуждению этих продуктов и наших читателей – нa нашем Форуме и в виде авторских заметок, которые, при удачном сочетании таланта и смекалки их написавших, могут быть опубликованы на нашем ресурсе. :)
Но начнем мы, как и подобает, с теории. Благо, здесь явно есть, что обсудить.
Сергей Озеров, Алекс Карабуто
Тестовая лаборатория Ferra
| Содержание | Часть 3 |
Intel Smithfield: «классика жанра»
При создании многоядерных процессоров для настольных ПК микропроцессорный гигант предпочел пойти на первых порах по пути «наименьшего сопротивления», продолжив традиции создания привычных для себя SMP-систем с общей шиной. Выглядит подобная MP-система чрезвычайно просто: один чипсет, к которому подключается вся оперативная память, и одна процессорная шина, к которой подключены все процессоры:

В случае новеньких двухъядерных процессоров Smithfield два обычных ядра, аналогичных Prescott, просто расположены рядом на одном кристалле кремния и электрически подключены к одной (общей) системной шине. Никакой общей схемотехники у этих ядер нет.

Smithfield
Рисунок. Intel Smithfield чип
У каждого «ядра» Smithfield – свой APIC, вычислительное ядро, кэш-память второго уровня и (что особенно важно) – свой интерфейс процессорной шины (Bus I/F). Последнее обстоятельство означает, что двухъядерный процессор Intel с точки зрения любой внешней логики будет выглядеть в точности как два обыкновенных процессора (типа Intel Xeon).
Рисунок. Ядро Smithfield

Сегодняшнее ядро Smithfield является «монолитным» (два ядра образуют единый кристалл процессора), однако следующее поколение настольных процессоров Intel (Presler, изготавливаемый по 65-нм технологии) будет еще тривиальнее – два одинаковых кристалла одноядерных процессоров (Cedar Mill) просто будут упакованы в одном корпусе (см. рис.).
 |
 |
| Presler | Cedar Mill |
Точно таким же будет и первый серверный процессор Intel данной микроархитектуры, известный сейчас под именем Dempsey. Но если у Smithfield на каждое из ядер приходится по 1 Мбайт кэш-памяти второго уровня, то у Presler и Dempsey это будет уже по 2 Мбайт на ядро.
 |
 |
| Presler | Dempsey |
Между тем, позднее у Intel пойдут другие, более сложные в плане микроархитектуры варианты двухъядерных процессоров, среди которых стоит отметить Montecito (двухъядерный Itanium), Yonah (двухъядерный аналог Pentium M) и Paxville для многопроцессорных серверов на базе Intel Xeon MP.
Еще в марте этого года Патрик Гелсингер объявил, что в разработке у Intel находятся аж 15 различных многоядерных CPU, и пять из них корпорация даже демонстрировала в работе. Причем, если еще в середине 2004 года официальные лица Intel отмечали, что многоядерные процессоры – это не «очередная гонка за производительностью», поскольку программная инфраструктура была тогда еще не очень готова поддержать такие процессоры оптимизированными приложениями, то теперь многоядерность у Intel поставлена во главу угла во всех базовых направлениях деятельности, в том числе – в разработке и отладке приложений (ну разве что кроме коммуникаций и сенсорных сетей – пока ;)). И в этом нет ничего удивительного – тактовую частоту процессоров стало наращивать все труднее и труднее, и, стало быть, надо искать что-то на cмену «гонки за мегагерцами». А добавляя ядра, производительность в ряде современных приложений уже можно заметно поднять, не повышая частоты. Да и пресловутый закон Мура (удвоение числа транзисторов на кристаллах) надо бы чем-то поддержать, а многоядерность – чуть ли не самый простой путь для этого… :) Собственно, мультиядерность в текущем понимании Intel – это один из трех возможных вариантов:



| Часть 2 |
Классификация: SMP, NUMA, кластеры…
Очевидно, что «ноги» у новых процессоров растут из многопроцессорных систем. А вариантов создания многопроцессорных систем – неисчислимое множество: даже простое перечисление всего созданного за прошедшие годы заняло бы слишком много места. Однако существует их общепринятая классификация:
1.SMP-системы (Symmetrical Multi Processor systems). В подобной системе все процессоры имеют совершенно равноправный доступ к общей оперативной памяти (см. рисунок). Работать с такими системами программистам – сущее удовольствие (если, конечно, создание многопоточного кода можно назвать «удовольствием»), поскольку не возникает никаких специфичных «особенностей», связанных с архитектурой компьютера. Но, к сожалению, создавать подобные системы крайне трудно: 2-4 процессора – практический предел для стоящих разумные деньги SMP-систем. Конечно, за пару сотен тысяч долларов можно купить системы и с большим числом процессоров… но при цене в несколько миллионов (!) долларов за SMP с 32-мя CPU становится экономически более целесообразно использовать менее дорогостоящие архитектуры.

2. NUMA-системы (Non-Uniform Memory Access systems). Память становится «неоднородной»: один её кусок «быстрее», другой – «медленнее», а отклика от во-о-он того «дальнего» участка вообще можно ждать «пару лет». В системе при этом образуются своеобразные «островки» со своей, быстрой «локальной» оперативной памятью, соединенные относительно медленными линиями связи. Обращения к «своей» памяти происходят быстро, к «чужой» - медленнее, причем чем «дальше» чужая память расположена, тем медленнее получается доступ к ней (см. рис.). Создавать NUMA-системы куда проще, чем SMP, а вот программы писать сложнее – без учета неоднородности памяти эффективную программу для NUMA уже не напишешь.

3. Наконец, последний тип многопроцессорных систем – кластеры. Просто берем некоторое количество «почти самостоятельных» компьютеров (узлы кластера или «ноды») и объединяем их быстродействующими линиями связи. «Общей памяти» здесь может и не быть вообще, но, в принципе, и здесь её несложно реализовать, создав «очень неоднородную» NUMA-систему. Но на практике обычно удобнее работать с кластером в «явном» виде, явно описывая в программе все пересылки данных между его узлами. То есть если для NUMA еще можно создавать программы, почти не задумываясь над тем «как эта штука работает» и откуда берутся необходимые для работы потоков данные; то при работе с кластером требуется очень четко расписывать кто, что и где делает. Это очень неудобно для программистов, и, вдобавок, накладывает существенные ограничения на применимость кластерных систем. Но зато кластер – это очень дешево.

Intel сегодня предпочитает создавать SMP-системы; AMD, IBM и Sun - те или иные варианты NUMA. Основная «область применения» кластеров – суперкомпьютеры.
Многоядерные процессоры
Основные вехи в истории создания двухъядерных процессоров таковы:
1999 год – анонс первого двухъядерного процессора в мире (IBM Power4 для серверов)
2001 год – начало продаж двухъядерного IBM Power4
2002 год – почти одновременно AMD и Intel объявляют о перспективах создания своих двухъядерных процессоров
2002 год – выход процессоров Intel Xeon и Intel Pentium 4 с технологией Hyper-Threading, обеспечивающей виртуальную двухпроцессорность на одном кристалле
2004 год – свой двухъядерный процессор выпустила Sun (UltraSPARC IV)
2004 год – IBM выпустила второе поколение своих двухъядерных процессоров (IBM Power5). Каждое процессорное ядро Power5 поддерживает аналог технологии Hyper-Threading
2005 год, 18 марта – Intel выпустила первый в мире двухъядерный процессор архитектуры x86
2005 год, 21 марта – AMD анонсировала полную линейку серверных двухъядерных процессоров Opteron, анонсировала десктопные двухъядерные процессоры Athlon 64 X2 и начала поставки двухъядерных Opteron 8xx
2005 год, 20-25 мая – AMD начинает поставки двухядерных Opteron 2xx
2005 год, 26 мая – Intel выпускает двухъядерные Pentium D для массовых ПК
2005 год, 31 мая – AMD начинает поставки Athlon 64 X2
Идея многоядерного процессора выглядит на первый взгляд совершенно тривиальной: просто упаковываем два-три (ну или сколько там влезет) процессора в один корпус - и компьютер получает возможность исполнять несколько программных потоков одновременно. Вроде бы бесхитростная стратегия… но конкретные её реализации в недавно вышедших настольных процессорах AMD и Intel заметно различаются. Различаются настолько, что сугубо «количественные» мелочи в конечном итоге переходят в качественные различия между процессорами этих двух компаний. Поэтому перед тем как переходить собственно к тестам современных двухъядерников, попробуем разобраться в различиях подходов этих микропроцессорных гигантов и, так сказать, «авансом» высказать некоторые предположения об их производительности.
D Creation
Видео из различных несжатых источников монтируется в Premiere 6.5 и экспортируется. Одновременно Photoshop импортирует и модифицирует фотоизображения. После экспортирования видео к нему с помощью After Effects добавляются некоторые спецэффекты.

И снова Pentium D 820 показывает производительность, сравнимую с 3,6 ГГц процессорами. Для одноядерных процессоров в этом подтесте, наряду с частотой, очень важным показателем оказалась величина кэш-памяти.
D Creation
Производится рендеринг 3D-моделей в 3ds max 5. Одновременно с помощью Dreamweaver подготавливаются веб-страницы. В заключение происходит прокрутка трехмерной анимации.

Эффект от второго ядра Pentium D 820 в этом подтесте немного меньше, но все равно уровень процессора 3,2 ГГц примерно сохраняется.
Помимо уже знакомого читателям Athlon
Помимо уже знакомого читателям Athlon 64 4000+ в нашем тесте участвует также Athlon 64 4000+ — новый процессор, выполненный по 90-нанометровому техпроцессу. По сравнению с предшественником эта модель отличается сниженным до 85 Вт максимальным энергопотреблением и, самое главное, поддержкой набора команд SSE3.
Остальные параметры процессора остались без изменений. Это сокет 939, частота ядра 2,4 ГГц, частота шины HyperTransport 250 МГЦ (1000 МГц эффективная), поддержка двухканальной памяти DDR400 и кэш L2 размером 1 Мб. Сейчас в продаже как старый, так и новый процессоры — и, судя по нашим тестам, их производительность разнится незначительно.
Athlon 64 FX-57, также участвующий в нашем тесте, построен на 90-нанометрвом ядре San Diego и от AMD Athlon 64 4000+ отличается только увеличенной до 2,8 ГГц частотой процессора.
Что касается других технологических параметров обоих процессоров, то тут можно упомянуть об использовании технологии "кремний на изоляторе" и площади кристалла, которая составляет 155 мм2 (на ней размещается 114 млн. транзисторов).

CineBench 2003 базируется на Cinema
CineBench 2003 базируется на Cinema 4D восьмого релиза и является популярным Shading и Raytracing тестом. Актуальная версия поддерживает SSE2, а также технологию Hyper-Threading.
В тесте Raytracing с помощью Cinema-4D-Raytracers производится рендеринг сцены Daylight. Она содержит 35 источников света и благодаря 16 картам освещенности формируют мягкие тени. Здесь в основном работает GPU процессора, а мощность графической карты играет второстепенную роль.

Тест работает, в основном, в кэш-памяти, пропускная способность процессорной шины здесь не очень важна. Pentium D 820 уверенно опережает более дорогие Pentium 4 670 и 3,73 ГГц Extreme Edition.
В дисциплине OpenGL-HW тест CineBench 2003 выводит две анимации с помощью OpenGL ускорителя графической карты. Таким образом процессор передает лишь позицию источников света, а также геометрию графической карте. Самое важное здесь — объем кэш-памяти и производительность памяти. Анимация Pump Action состоит из 37000 треугольников в 1046 объектах, во второй сцене Citygen два объекта в целом состоят из 70000 треугольников.
В дисциплине OpenGL-SW Cinema 4D дополнительно принимает расчет освещения — то есть процессор выполняет дополнительную арифметическую работу.
В обоих дисциплинах заметно серьезное преимущество процессоров от AMD — точнее, преимущество архитектуры со встроенным в процессор контроллером памяти. Результаты процессоров от Intel пропорциональны тактовой частоте — и у Pentium D 820 закономерно последнее место.
Communications
Пользователь получает в Outlook 2002 e-mail с файлом zip, в котором содержится несколько документов. Во время чтения e-mail и актуализации календаря VirusScan 7.0 сканирует систему.

Теоретически в этом сценарии двухъядерный процессор должен был показать неплохие результаты, однако этого не произошло. Кроме того, на примере с Pentium 4 670 заметно, что чипсет 955X с памятью DDR2-667 вообще "не любят" этот подтест.
Data Analysis
В данном подтесте сначала производится выборка данных из Access. Затем WinZip 8.1 архивирует большое количество документов. Результаты выборки SYSmark2004 выгружает в Excel и строит там графики.

То, что в этой дисциплине двухъядерность не сыграла никакой роли, скорее всего, объясняется странностью самого подтеста. Не понятно, причем тут архиватор. И если с построением графиков в Excell еще можно согласиться, то выбор СУБД, мягко говоря, неадекватен.
Document Creation
Производится редактирование документа в Word версии 2002. Кроме этого с помощью NaturallySpeaking аудиофайл переводится в документ и конвертируется затем в формат PDF. Затем сценарий SYSmark2004 прокручивает презентацию.

Уж кому многоядерность не нужна, так это тем, кто использует ПК в качестве продвинутой пишущей машинки. Результаты зависят, в основном, только от частот процессоров.
Эволюция + революция, или Пути развития современных процессоров
Андрей Бондаренко, Компьютеры+Программы
Недавнее появление двухъядерных процессоров революционно уже хотя бы потому, что кардинально новые модели процессоров оказались дешевле сравнимых с ними по производительности предшественников.
Оба основных производителя процессоров в последнее время регулярно радуют нас новинками. При этом фактически происходит развитие технологии в двух напрявлениях: в эволюционном (улучшение характеристик классических одноядерных процессоров) и революционном (выпуск новых многоядерных процессоров). При сегодняешнем уровне развития рынка оба направления оправданы и востребованы пользователями — прежде всего, в силу того что типично пользовательское программное обеспечение, такое как игры и офисные программы, слабо оптимизировано под многопоточное выполнение. Поэтому в ближайшее время две рыночные ниши для новых процессоров будут существовать паралельно — и достаточно четко разделятся по критерию создания/просмотра цифрового контента. На ПК, на которых контент (видео, аудио, моделирование, конструирование) создается, более оправданными будут многоядерные процессоры, а на клиентских и игровых ПК целесообразным будет использование обычных процессоров.
В сегменте одноядерных процессоров компанией Intel не так давно были выведены на рынок новые модели с тактовыми частотами 3,8 ГГц. Речь идет о топовом Pentium 4 670 и более демократичной модели — Pentium 4 570. В сегменте же двухъядерных процессоров корпорация представила новый Pentium D 820 по очень привлекательной цене (около $250). Данная модель, по всей видимости, должна стать катализатором интереса к таким процессорам со стороны профессиональных пользователей. Каждое ядро Pentium D 820 работает на частоте 2,8 ГГц. Впрочем, в этой линейке есть и более быстрые процессоры (3,0 и 3,3 ГГц), но и стоят они уже от $550.
Цель данного тестирования — оценить привлекательность Pentium D 820 для профессионального пользователя. Естественно, что в данный момент этот процессор не сможет проявить свой потенциал в играх и в ряде других чисто клиентских приложений — однако нас интересует выгоды использования Pentium D 820 для расчетов или создания цифрового контента. Собственно, этим и определялся выбор используемых тестов.
Один из популярнейших инструментов для
Один из популярнейших инструментов для работы с 3D-графикой, программа Lightwave версии 8.2 хорошо оптимизирована под Pentium 4. Она может работать как используя набор команд SSE2, так и разбивая работу на оптимальное число параллельных потоков. Тестирование в этой программе мы провели как в однопоточном, так и в многопоточном (8 потоков) варианте.
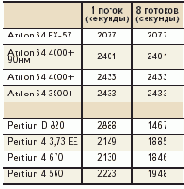
При однопоточном рендеринге Pentium D 820 закономерно не получил никакой прибавки за счет второго ядра. Для одноядерных процессоров при прочих равных условиях здесь наиболее важна скорость кэш-памяти. При восьмипоточном рендеринге Pentium D 820 заметно лидирует и на 26% опережает Pentium 4 670, который, в свою очередь, заметно опережает Pentium 4 560.
Серия процессоров Intel 6хх для
Серия процессоров Intel 6хх для сокета LGA775 состоит из моделей 630, 640, 650, 660 и 670, тактовые частоты которых лежат между 3,00 и 3,80 ГГц. Все они имеют 2-мегабайтный кэш L2, используют FSB с частотой 800 МГц и поддерживают технологию Hyper-Threading. Кроме того, в серии 6хх реализована поддержка 64-битных- расширений команд EM64T, а также технологий SpeedStep (энергосбережение) и XD (защита от атак типа "переполнение буфера").
Представленные еще в июне 2004 г. Pentium-4 500-й серии имеют такие же тактовые частоты, однако кэш L2 для них составляет 1 Мб. Нет также поддержки технологий EM64T и SpeedStep. С конца прошлого года 500-е модели со степингом E0 поддерживают технологию XD. На это указывает индекс "J" в конце номера процессора.
С июня 2005-го линейка процессоров 5х0 была модернизирована до линейки 5х1. Новые модели 521, 531, 541, 551, 561 и 571 по-прежнему имеют частоты от 2,8 до 3,8 ГГц, однако теперь дополнительно поддерживают технологию EM64T.
Pentium D
Двухъядерные процессоры Pentium D — это два независимых ядра, объединенных на одной кремниевой пластине. Каждое ядро имеет собственный кэш L2 объемом 1 Мб. Ядра процессоров базируются на архитектуре NetBurst процессоров Pentium 4. Ядра объединены общей процессорной шиной, работающей на частоте 800 МГц. Рассчитаны эти процессоры только на сокет LGA775.
Ядра процессоров Pentium D не поддерживают технологию Hyper-Threading. Для двухъядерных процессоров она присутствует только в Pentium Extreme Edition, который благодаря этому виден в системе как восьмиядерный.
Все процессоры Pentium D поддерживают 64-битные расширения команд EM64T и технологию XD — защита от атак типа "переполнение буфера". Кроме того, модели 830 и 840 дополнительно поддерживают технологию SpeedStep, при которой возможно динамическое регулирование частоты и напряжения питания ядер процессора.
Все Pentium D выпускаются по 90-нанометровому техпроцессу, при этом на кристалле площадью 206 мм2 размещается 230 млн. транзисторов.
Революция для профи
Может ли быть сразу два правильных пути развития процессоров? На сегодня, наверное, да. Во многих тестах одноядерный Pentium 4 670 благодаря высокой частоте ядра и 2 Мб кэша L2 оказывается на первом месте. Так что для обычного клиентского ПК или, другими словами, для "потребителя" цифрового контента это довольно неплохой выбор. Обычно человек работает с одной программой, а для работающих на заднем плане брандмауэров/антивирусов/меседжеров/качалок вполне достаточно и возможностей Hyper-Threading.
Совсем другое дело те пользователи, для которых ПК является инструментом для создания 3D/видео/аудио или интенсивных расчетов. При вполне достаточной для "single-threaded"-приложений производительности и в разы меньшей, по сравнению с Pentium 4 3,73 EE и Pentium 4 670, стоимости двухъядерный процессор Pentium D 820 обеспечивает значительно большую производительность на профессиональных задачах и, кроме того, "нафарширован" всеми модными технологиями типа EM64T и XD.
Так что на сегодня наличие двух "правильных" путей развития процессоров выглядит вполне логично. Профессиональные пользователи пойдут по революционному (и более дешевому!) пути многоядерности, а обычные пользователи будут довольствоваться плодами эволюции одноядерных процессоров.
Несколько разочаровывает пока связка чипсета 955X с памятью DDR2-667. Можно считать, что скоростной потенциал новой памяти оценить на данном этапе не удалось.
Autodesk известна своим софтом для
Компания Discreet/ Autodesk известна своим софтом для 3D-моделирования, анимации и рендеринга 3ds max. Актуальная версия — 6. С июня 2004 г. для этой программы существует тест SPECapc. С его помощью можно определить производительность 3ds max 6 на различных аппаратных платформах.

SPECapc для 3ds max 6 представляет собой реальный проект с использованием функций wireframe modeling, shading, texturing, lighting, blending, inverse kinematics, object creation, scene creation, particle tracing, animation и rendering.
При рендеринге 3ds max 6 полностью использует до шести процессоров, поэтому многоядерность Hyper-Threading должна значительно ускорять работу.

Как и представлялось изначально, в 3ds max процессор Pentium D 820 значительно опережает все одноядерные модели. Объем кэш-памяти особой роли в этом тесте не сыграл.
с плавающей запятой мы скомпилировали
Для определения Base-рейтинга вычислений с плавающей запятой мы скомпилировали тест с помощью Intel C++ 8.1 и MS Visual Studio а также Intel Fortran 8.1.
SPECfp_base2000 также выполняется как однопоточное приложение, выдавая в качестве результата чистую производительность FPU процессора.

Процессоры AMD64 тестировались с ключами компиляции -QxW для включения поддержки SSE2.
Результаты этого теста пропорциональны тактовым частотам, поэтому лидирующий результат Pentium 4 670 вполне закономерен.
При определении максимальной пропускной способности
При определении максимальной пропускной способности вычислений с плавающей запятой в системе параллельно запускается несколько копий теста. Обычно число копий является равным числу видимых операционной системой реальных или виртуальных ядер процессоров.
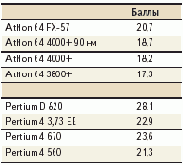
И опять при определении максимальной пропускной способности вычислений Pentium D 820 значительно опережает все классические процессоры.
рейтинг теста SPEC при рекламе
Как Intel, так и AMD используют Base- рейтинг теста SPEC при рекламе своих продуктов. Мы также воспользовались этими тестами, скомпилировав их с помощью Intel C++ 8.1 и MS Visual Studio.
Подтест SPECint_base2000 работает как однопоточное приложение, поэтому, естественно, не использует ни Hyper-Threading, ни двухъядерность. Соответственно, результаты позволяют оценить чистую целочисленную производительность ядра процессора.
В таблице приведены развернутые результаты по каждой тестовой подзадаче:
В итоге в тесте SPEC CPU2000 Integer, SPECint_base2000 имеем следующие результаты:

Pentium D 820 уверенно занял последнее место — и так же уверенно первое место досталось Pentium 4 670. Результат закономерный, так как при однопоточном выполнении целочисленных вычислений важны, в первую очередь, тактовая частота и объем кэша L2.
Этот тест позволяет определить пропускную
Этот тест позволяет определить пропускную способность системы при выполнении целочисленных вычислений. При этом в системе запускается несколько копий теста параллельно. Обычно число копий является равным числу видимых операционной системой реальных или виртуальных ядер процессоров. То есть для процессоров от AMD запускалась одна копия (хотя при запуске двух результат остается тем же), а для всех процессоров Intel — две (двухъядерность или Hyper-Threading).

Pentium D 820 ни оставил одноядерным собратьям никаких шансов. Этот процессор работает при 2,80 ГГц тактовой частоты на 22% быстрее, чем Pentium 4 670 с 3,80 ГГц. Прибавка же производительности от второго ядра составила около 80%.
Новый тестовый пакет SYSmark2004 от
Новый тестовый пакет SYSmark2004 от компании BAPCo является наследником индустриально признанного предшественника SYSmark2002. Тестовый пакет использует 17 обновленных приложений и содержит исправления некоторых спорных моментов предшественника.
SYSmark2004 не только открывает несколько программ одновременно, но и позволяет приложениям работать в фоновом режиме. Следовательно, многоядерные процессоры в этом тесте могут показать свой потенциал (как и процессоры, поддерживающие Hyper-Threading).

В общей оценке Pentium D 820 эффект от его второго ядра примерно эквивалентен прибавке частоты в 400 МГц для одноядерного процессора. То есть по производительности он примерно равен 3,2 ГГц процессору Pentium 4 540J.
Не очень убедительно в общем зачете выглядит Pentium 4 670, работающей на новой 955X материнке с памятью DDR2-667. Его производительность практически равна таковой у Pentium 4 560 (925X чипсет с памятью DDR2-533).
SYSmark2004: Internet Content Creation
В этой дисциплине лидируют, прежде всего, процессоры с быстрыми блоками FPU. Кроме того, участвующие в этом подтесте приложения активно используют набор команд SSE2 и многопоточную обработку.
В состав теста входят Macromedia Dreamweaver и Flash MX, Discreet 3ds max 5.1, Adobe AfterEffects 5.5, Photoshop 7.0.1 и Premiere 6.5, Microsofts Windows Media Encoder 9, WinZip 8.1 а также McAfee VirusScan 7.0.

В этой дисциплине процессор Pentium D 820 наглядно демонстрирует преимущества двухъядерной архитектуры. Здесь он практически равен моделям с частотой в 3,6 ГГц. Особенно большой прирост в производительности показали 3ds max и Photoshop.
Весьма неплохо показал себя и Pentium 4 670.
Наряду с общей суммой баллов в подтесте, SYSmark2004 вычисляет еще и производительность для подкатегорий 2D Creation, 3D Creation и Web Publication.
SYSmark2004: Office Productivity
В категории Office Productivity тестовый пакет SYSmark2004 использует 10 различных приложений: Microsofts Word, Excel, PowerPoint, Access и Outlook (все версий 2002), McAfee VirusScan 7.0, ScanSoft Dragon Naturally Speaking 6, WinZip 8.1, Adobe Acrobat 5.0.5 и Internet Explorer 6.0.

В категории Office Productivity двухъядерность не сыграла никакой роли. Обычные процессоры здесь лидируют — и среди них наилучшие результаты показывают модели, использующие память DD2-533.
Наряду с общей суммой для офисной производительности SYSmark2004 дополнительно делает оценки в категориях Communications, Document Creation и Data Analysis.
Тестовые платформы
Pentium 4 670 и двухъядерный Pentium D 820 и тестировались нами в комплекте с материнской платой Intel Desktop Boards D955XBK (чипсет 955X) и памятью DDR2-667 SDRAM CL4.
Остальные процессоры Pentium 4 тестировались на материнке Intel Desktop Board D925XECV2 с памятью DDR2-533 SDRAM CL4. Одноядерные процессоры от AMD тестировались на MSI K8N Diamond (чипсет NVIDIA nForce4 SLI) с памятью DDR 400 CL2.

Чтобы гарантировать одинаковые тестовые условия, все системы оснащались видеокартой MSI GeForce 6800 GT в PCI-Express (драйвер ForceWare 67.66, DirectX 9.0c) с 256 Мб памяти GDDR3 и SerialATA-винчестером Maxtor MaxLine III 250 Гб.
Web Publication
В этом тесте сценарии SYSmark2004 распаковывают архив с WinZip. Параллельно с помощью Flash MX открывается, модифицируется и экспортируется трехмерная векторная графика. Видео из подсценария 2D Creation архивируется с помощью Windows Media Encoder 9. Dreamweaver с помощью своих сценариев обрабатывает веб-страницы и в конце VirusScan проверяет систему на вирусы.

Благодаря параллельной работе приложений второе ядро Pentium D 820 дает в этом тесте прибавку производительности, примерно эквивалентную 1 ГГц. Все одноядерные процессоры остались позади.