Mac на процессоре Intel: по следам сенсации
Владимир Новиков aka VN_MAClover
Итак, keynote Стива Джобса завершён, можно сделать некоторые выводы. Джобс вышел на сцену в брюках, вместо обычных джинсов, что прямо указывало на то, что "базар пойдёт серьёзный". И действительно...
CEO Apple открыто раскритиковал IBM за
неспособность производить в нужном количестве процессоры G5, особенно их двухъядерные версии, давно объявленные, но до сих пор недоступные; отсутствие прогресса в плане тактовой частоты, которая за два года выросла (всего-то:-)) с 2.0 до 2.7 GHz); нежелание произвести версию для ноутбуков.После чего объявил о том, что, начиная с 2006 года, вся линейка компьютеров Apple постепенно перейдёт на процессоры от Intel.
Он показал Mac OS X 10.4 Tiger, работающую на Pentium 4, и заявил, что Xcode 2.1 позволит компилировать как для G3/G4/G5, так и для x86. А Mac OS X 10.5 (Leopard) будет представлен для обеих архитектур сразу. Кроме того, был представлен новый эмулятор Rosetta, который будет работать под х86 и на ходу перекомпилировать код PowerPC на почти 100% скорости. Поскольку эмулятор делает сам Apple, можно быть уверенным в том, что так и будет. Стив Джобс показал Adobe PhotoShop CS и MS Office, которые работали так же быстро, что и на среднестатистических сегодняшних Маках.
Разработчикам уже сегодня доступен компьютер G5 с процессором Intel.
А теперь выводы. Сразу предупреждаю, что всё это - только моё личное мнение. Но я считаю для себя возможным сделать такой анализ, исходя из двух истин. Истина первая, историческая: Apple НИКОГДА не говорила о будущем. Значит, появилась необходимость... Истина вторая, экономическая: два года без новых моделей не прожить ни одной компьютерной фирме. Это означает, что за пазухой спрятан большой кирпич...
Итак:
Ничего нового сказано не было, и так всем было известно, что Mac OS X давно и прекрасно работает на х86. Не будем забывать, что корнями он восходит к Next, а FreeBSD, на базе которого построен Darwin, вообще изначально только под х86 архитектуру и существовал.Да и сам Darwin всегда был доступен в версии для х86, а уж перекомпилировать интерфейс... Разработчикам дали понять, что Classic настал конец. Сразу поясняю, что Classic - это что-то типа поддержки приложений Windows 3.11 в Windows 95. Но и это не новость. Вот уже 2 года как OpenFirmware (маковская разновидность BIOS) всех Маков не поддерживает запуск Mac OS 9.2.2. Для работы со старыми приложениями надо либо покупать б/у Маки, либо работать в Classic, т.е. в эмуляции. Да, есть Rosetta, но это будет эмулятор на эмулятор... Тем же разработчикам более чем прозрачно намекнули, что не надо использовать чужие компиляторы (Metrowerks встал и раскланялся), а осваивать Xcode. Но вот беда, Xcode заточен под Cocoa софт, а с Carbon приложениями работает хуже. Carbon приложения - это старые приложения от "девятки", которые сделали совместимыми с Mac OS X, но не до конца, а просто почистив код. То есть это лучше Classic, но хуже Cocoa, родных приложений для Mac OS X. Большой камень в огород Microsoft и Adobe, руководство которых поспешило выйти на сцену и громко заявить, что всё перепишет в лучшем виде... Все уже поняли, что надо писать только и исключительно Cocoa приложения. Замечу в скобках, что Cocoa приложения давно уже совместимы с Linux, так как есть такая вещь как GNUStep. В качестве примера приведу очень хороший и незаслуженно неизвестный почтовик GNUmail. Новая версия Xcode позволит компилировать либо отдельные версии для двух поддерживаемых архитектур, либо fat binary, так хорошо знакомую мне по эпохе перехода с архитектуры 68xxx на Power. Ничего про новые машины сказано не было... А теперь смотрим. Apple форсирует тотальный перевод всех приложений на Cocoa, а также их чистку на предмет отсутствия всяких хаков, которые могут помешать при компиляции под х86. Adobe и Microsoft начинают, утерев слёзы, переписывать свои монстроидальные софтины, к великой радости окружающих. А дальше...
Apple в состоянии выпустить машины с ЛЮБЫМ из mainstream камней, IBM, Intel, AMD...
Операционка позволяет, Cocoa софт надо лишь перекомпилировать. Если подтянется IBM, то и чудненько, если нет - Intel inside в новых ноутах.
Одним словом, не могу не снять шляпу перед очередным гениальным ходом Джобса. Как MacUser со стажем, я должен был бы рвать и метать, что меня кинули... а я радуюсь. У нас опять есть выбор, платформа будет жить.
И последнее. Джобс ясно сказал, что железо будет делать Apple. То есть фантазировать по поводу работы Mac OS X на самосборных Пентюхах явно не нужно. Наверняка появятся хаки, но это будет уже не то...
Под конец и по горячим следам, несколько постоянно встречающихся вопросов и мои попытки дать на них ответы (опять таки, отражающие лишь мое личное мнение):
В1: Они, падлы, нас подло кинули, я только что себе купил iMac, iBook, Power что-то там...
О1: Ну а я приятелю посоветовал Р4 за неделю до выхода ADM dual core камней. И что? Когда серия Х доходит до магазинов, пресса вовсю тестирует серию Х+1, а на заводах уже перестраивают линии на серию Х+2. Кроме того, человеческим языком сказали, что в течение многих лет будут выходить машины на базе PowerPC, если IBM наладит выпуск камней, а также будет возможность компилировать под них. ОК, Маки служат в среднем дольше IBM-PC. Возьмём сегодняшний Мак, поставляемый с Тигром. Леопард будет в начале 2007 года, в нём поддержка PowerPC сохранится полностью, так как на тот момент переход не будет завершён, да и установленная база будет против... В 2009 году будет версия 10.6 (что ещё из кошек осталось? Прим. ред.: если по нарастающей крутизне, боюсь, что только ископаемые махайроды и смилодоны - А.Ф.), там явно тоже всё будет в порядке. Даже если представить себе, что в 2011 поддержку прекратят, скажем прямо, этот Мак доживёт своё спокойно...
В2: А вот Sony и MS бегут на поклон к IBM и будут использовать в новых игровых приставках камень Cell. А Apple что, самый умный, что ль?
О2: Процессор Cell пока существует только в виде прототипа, равно как и процессор G5 с частотой 3.5 GHz, его версия для ноутов, ну и так далее.
Ничто не помешает Apple использовать этот камень, если вдруг он будет хорош до безобразия, а у Intel возникнут проблемы. Сегодня Джобс дал понять всем, что незаменимых нет, только и всего.
В3: А AMD всё равно круче!
О3: Ничто не мешает Apple производить машины на базе камней AMD. Ещё раз, сегодня было сделано заявление о том, что "мы можем всё", а машины будут через год. За это время много воды утечёт...
В4: Тогда уж пусть просто делают софт, который будет ставиться на любые машины.
О4: Спасибо, уж лучше Вы к нам... Apple делает рабочие станции, у которых не бывает проблем с драйверами, если использовать сертифицированное оборудование. Уже сейчас разработчикам продают Power Mac G5 с камнем от Intel, а не Dell какой-нибудь. Ясно, что в машинах будет много своих технологий. Ничто не помешает умельцам поставить Mac OS X на самосборную машину, но официально это не будет разрешено, во всяком случае на первых порах.
В5: Всё равно обидно, ведь они были не такие, как все...
О2: А они были, есть и будут не такие, как все. Психология осталась прежней: делать машины, которые работают. При этом пользователь может даже не знать, как они устроены. Но Apple вынужден быть прагматиком и отказываться от проприетарных технологий. Шина NUBUS, порт ADB, винты SCSI, наконец, экраны с подключением через ADC (Apple Display Connector). Просто никто не хотел производить совместимую периферию...
В6: Конец, теперь будут вирусы, трояны, пиратские диски и Маки по 300 баксов на Савёловском.
О6: Пиратские диски и так есть, Маков за 300 у.е. пока не будет (см. выше), а вирусы и трояны пишутся под ОСь, а не под камень. А Mac OS X - это UNIX-подобная система, и трояна туда засадить трудно. Несколько попыток написать гадость были, но без соучастия пользователя (пусть и невольного) не обойтись...
В7: А тогда зачем это всё?
О7: Истинные мотивы знает только Джобс, будущее покажет. Однако, ИМХО, дело в софте. Аналогичная ситуация сложилась в момент перехода с архитектуры 68ххх на PowerPC.
Старый софт работал через эмулятор, и разработчики не спешили с его портированием. Так и теперь. До сих пор есть софт, который существует только под "девятку" (некоторые функции Cleaner), масса Carbon софта (вся линейка Adobe, Microsoft, суперпопулярный Graphic Converter...), а на Cocoa пишет сам Apple и разработчики свободного ПО. Разумеется, масса компаний предпочла полностью переписать софт в Cocoa (Nisus Writer), но тяжёлая артиллерия пока выжидала. А это значит, что софт не может быть по определению оптимизирован под новые камни и 64-разрядную архитектуру, к примеру. Или над этим надо специально работать...
В8: А я не знаю Objective-C...
О8: Не будучи разработчиком, мне трудно сказать, насколько легко разрабатывать Cocoa приложения на С/С++. Однако знаю, что это возможно. Но ведь есть ещё Java, котоая прекрасно интергирована в систему и позволяет общаться с Cocoa. Проект Neooffice/J прекрасно работает. А ещё есть Qt/Mac для любителей С++. Крупных проектов пока нет, однако MyPasswordSafe, к примеру, прекрасно работает. Наконец, есть порт GTK+, правда, пока он далёк от завершения. Но Abiword уже пашет. Одним словом, разработка приложений для Мака - уже не проблема. Более того, GTK+ и QT кроссплатформенны по определению, про Java и говорить нечего, а Cocoa приложения совместимы с Linux благодаря проекту GNUStep.
В9: А я всё-таки не буду переписывать мою гениальную Carbon программу.
О9: Тоже не проблема, XCode 2.1 работает с Carbon софтом и позволит делать версию для х86, однако Appele предупреждает, что ручками придётся работать значительно больше... может на Cocoa перейти сейчас, чтобы потом не было мучительно больно и обидно...?
Mactel, или блеск и нищета бенчмарок
Владимир Новиков aka VN_MAClover
Данная тема может стать прекрасным сюжетом для социологического исследования наших реакций на корпоративные маркетинговые слоганы. Всё есть, и непонимание, и тупое слияние в экстазе, и отрицание, недоверие и всё, что хочешь... Психолога в студию.
Кроме того, это наглядная иллюстрация двух старинных русских пословиц, а именно "шило в мешке не утаишь" и "всё тайное становится явным". О себя добавлю, что в XXI веке быстро становится... В понедельник Apple 100 раз просила не публиковать бенчмарки тестовых машин, в среду бенчмарки эти уже валялись по всей Сети...
Одним словом, так. На нескольких "яблочных" форумах вовсю разгорается перепалка под общим названием "Стив опять всех надул по полной..." Предметом разборок стали обнародованные самим же Стивом Джобсом в апреле бенчи, сравнивающие лучших представителей архитектуры х86 и новые G5 2.7 GHz. Ясно, кто там одерживает верх по всем пунктам. Один из французских сайтов скомпилировал эти бенчи в виде графики.
Очень забавно, что кричат громче всех те, кто в апреле с пеной у рта доказывал, что для бенчей были выбраны наиболее благоприятные для G5 тесты, а в остальных преимущество не столь и заметно. Авторитетный в маковских кругах тестовый сайт Barefeats провёл свои исследования и постановил, что Стив глобально прав, хотя в реальности всё гораздо более сложно. Действительно, в некоторых ситуациях картина почти обратная и ПК обходит лучший из Маков.
Очень забавно. Видимо, руководитель фирмы должен был выйти на сцену и заявить, что сейчас он покажет, как машины конкурентов обставляют его собственные... Всё-таки надо повзрослеть и начать отличать рекламный дезодорант "Axe", от настоящего...
Другой авторитетный сайт, а именно знаменитый Think Secret протестировал тестовые Маки на базе камней х86, которые с понедельника продают разработчикам. Российский сайт Mikeosx опять же перевёл это в графику, за что ему отдельный респект. Понятное дело, кто побеждает здесь.

Ну и что мы увидели? Что и должны были увидеть. Сегодня лучшие G5 обходя по скорости х86 со свистом, что и показали в апреле. Именно по этой причине переход на архитектуру х86 начнётся только в 2006 году, и начнется он с ноутбуков и непрофессиональных машин. Именно там ситуация вообще критическая, так как G4 уже дышит на ладан, а обещанные обновления всё не идут. В этом сегменте Маки уже сейчас начинают отставать по мощности от ПК.
А вот профессиональная линейка перейдёт на х86 лишь в 2007 году, когда появятся совсем новые камни от Intel, которые "догонят и перегонят" IBM G5. А может ещё и IBM проснётся (см. мою предыдущую статью по этому поводу). Заодно и учтут опыт перехода первых машин, как "железный", так и софтверный.
И все-таки: почему Mactel?
Владимир Новиков aka VN_MAClover
Появилась новая информация, раскрывающая причины перехода Маков на процессоры от Intel. Её дали во время конференции разработчиков сотрудники Apple. Ясно, что это не вся правда, но всё же...
Итак, Freescale (бывшая Motorola) тихо уходит в процессоры для бытовой электроники и "умных домов". Планы "двухголовых" G4 всё откладывались и откладывались..., так что даже "переходные" ноутбуки на двухъядерных кристаллах выпустить практически невозможно. А не будем забывать, что Apple продаёт больше ноутбуков, чем настольных машин.
Отношения IBM и Apple были испорчены из-за ... Microsoft. Дело в том, что Sony, Nintendo и Microsoft стройными рядами пошли на поклон к IBM и решили установть ее новый процессор Cell на свои игровые приставки. Таким образом, IBM обязалась поставить в ближайшие три года 100 миллионов камней Cell с тактовой частотой 3.2 гигагерца. Разработчики Apple признались во время конференции, что протестировали Cell и выяснили, что с нормальными программами он работает хуже двухгигагерцного PowerPC. К сожалению, Apple в одночасье перестал интересовать IBM в качестве приоритетного партнёра, так как процессоры Cell не будут менять тактовую частоту все три года, а Apple требовал новые линейки хотя бы раз в полгода. Как известно, серверные камни от IBM тоже раз в год обновляются. В общем, имея такое маркетинговое покрытие от рынка игровых приставок, IBM просто похерил G5 и его версию для ноутов, в которой Apple позарез нуждается...
Что касается AMD, то значительную долю ее процессоров делает... IBM. Для Apple было просто опасно связываться с AMD, так как IBM мог обидеться... Кроме того, AMD просто не в состоянии так увеличить производство камней (и нынче-то у них напряги с поставками - А.Ф.). Наконец, уже сейчас известно, что ничто не помешает установить Mac OS X на компьютеры с камнями от AMD, так как именно эти камни стоят на машинах для внутреннего пользования Для сторонних же разработчиков раздают с Intel inside, контракт обязывает.
В общем, оставалось только пойти на поклон к Intel, благо те вот уже 25 лет зовут. Intel дал конкретные обещания не только поставлять камни, но и разработать нужные чипсеты, и так далее, что экономит для Apple миллионы долларов в год. Наконец, если и у Intel возникнут проблемы, то они будут у HP, Dell etc. - то есть у прямых конкурентов.
Ничего нового нет на белом свете. Опять деньги и конкурентная борьба, в которой не гнушаются даже кидаловом "в особо крупных размерах".
Ну и последняя новость для любителей хакинга, тюнинга и протчая. В пиринговых сетях уже лежит Mac OS X 10.4.1 for Intel, которая поставляется с машинами для разработчиков. По подчерпнутым мной, но непроверенным в связи с наличием нормального Мака сведениям, она прекрасно ставится на почти любой ПК, включая те, что с Савёловского, при условии наличия
контроллера SATA, к которому пристёгнут тот винчестер, на который система будет ставиться, DVD плеера, чипсета от Intel с встроенным видео либо одной из поставляемых Apple с Маками карт ATI (9000, 9200, 9600, 9650, 9700, 9800, X800). Сообщается, что пока встроенная графика от Intel работает лучше, а ATI - как повезёт, так как в мире ПК стопроцентно родных ATI карт мало.
Matrix: Reload, Revolution, RAID!
Евгений Патий, «Экспресс-Электроника», #12/2004
В числе основных инноваций, присутствующих в наборах системной логики i 915/925, отметим поддержку памяти DDR 2, шины PCI Express, новую архитектуру Socket 775, а также технологии High Definition Audio и Matrix Storage Technology, более известную как Matrix RAID. О последней технологии мы расскажем подробнее – в ближайшие годы она будет играть достаточно важную роль в нашей жизни.
Как ни странно, пресса почти не проявила интереса к одному из самых оригинальных технологических решений, использованному в последних чипсетах Intel. В этой статье мы попытаемся проанализировать новую технологию хранения данных, выявить ее преимущества и, естественно, недостатки, без которых не обходится ни одна новая платформа.
Сегодня в секторе настольных систем (а именно для них и предназначены наборы логики Intel 915/925) доминируют два традиционных метода хранения данных – RAID 0 и RAID 1. Технология Matrix RAID призвана не только дополнить их, но и разрешить извечный вопрос, с которым неизбежно сталкиваются пользователи при выборе метода хранения информации, – чему отдать предпочтение? Поставить во главу угла скорость обмена данными, постоянно чувствуя угрозу их потери в результате сбоя, или стабильность и безопасность зеркалирующего массива в ущерб скорости? Эта дилемма типична для IT -рынка в целом: скорость против стабильности.
В сущности, ситуация вовсе не безвыходная и имеются способы угодить всем, используя методы RAID 5 и RAID 0+1 ( RAID 10), обеспечивающие и скорость, и избыточность данных на случай непредвиденного сбоя. Оба подхода позволяют добиться высокой скорости обмена данными с помощью дисков, работающих не в режиме RAID, а также защиты от сбоя благодаря мгновенному бэкапу данных на резервный диск ( RAID 1, RAID 0+1). Необходимый результат можно получить, применив разряды четности, которые используются для восстановления информации, если на диске ( RAID 5) произошел сбой. Действительно, такие решения существуют, однако основной их недостаток – практически полная непригодность в составе массовых настольных решений, ведь цена, которую придется платить за скорость и безопасность, крайне высока (необходимо минимум три-четыре жестких диска и специализированный RAID -контроллер для объединения и управления всем этим дисковым хозяйством).
Хотя обычный пользователь просто не станет покупать больше двух жестких дисков, а уж если и купит – три-четыре жестких диска непросто разместить в корпусе настольного ПК, обеспечить им стабильное питание (мощный блок питания), охлаждение (один-два дополнительных вентилятора). Словом – кошка за мышку, мышка за репку – очень уж накладное и громоздкое получается решение.
Технология Intel Matrix RAID Storage призвана принести преимущества метода RAID 0+1 в массы. Алгоритмы Matrix RAID интегрированы непосредственно в чипсет, кроме того, для организации массива требуется лишь два жестких диска. Итак, на первый взгляд все выглядит великолепно: отдельный контроллер не нужен, поскольку «родной» уже имеется в микросхеме южного моста чипсета, жестких дисков необходимо всего два, а не три-четыре, как у стандартных уровней RA ID -массивов. Но, как известно, бесплатный сыр бывает только в мышеловке, поэтому нелишне выяснить, есть ли тут подвох, и если есть, то где он кроется.
Matrix RAID в теории
Принципы работы Matrix RAID достаточно просты. Напомним основы организации классических RAID -массивов: мы оперируем целыми жесткими дисками как таковыми. Из этих двух организуем RAID уровня 0, из тех тех-четырех – RAID уровня 5. Все операции по организации и управлению массивами реализуются на аппаратном уровне с помощью BIOS системной платы или выделенного RAID -контроллера — без вмешательства операционной системы.

Рис. 1. Архитектура Matrix RAID Matrix RAID позволяет осуществить более гибкий подход – при наличии в системе южного моста ICH 6 R и двух жестких дисков с интерфейсом SerialATA есть возможность разделить общее дисковое пространство на две части, причем объем каждой из них определяется пользователем. Одна часть функционирует как RAID уровня 0, другая – как RAID -массив уровня 1. Налицо и скорость, и возможность резервного копирования на случай сбоя. Для большего понимания механизма приведем пример: имеются два жестких диска объемом 200 Гбайт каждый. И первый, и второй диски разделяем на части объемом 50 Гбайт и 150 Гбайт.
Из томов объемом 150 Гбайт организуем скоростной массив уровня 0 с некритичными данными, из томов-пятидесятников – надежный, но неторопливый массив уровня 1.
Очень важно, что Matrix RAID, в отличие от привычных методов организации массивов хранения данных, не является программно-независимым. Скорее наоборот. Задействовать эту технологию удастся только под операционными системами Microsoft Windows 2000, XP, 2003, а также Linux, для чего имеется соответствующее обновление ядра 2.4. Если кому-то не хватает RAID -массивов под ОС Windows 95, 98 и M Е – беда невелика, а вот отсутствие поддержки Windows NT расстраивает по-настоящему.
Таким образом, Matrix RAID является, скорее, не аппаратной, а программно-аппаратной технологией. Причина тому — использование не только контроллера-концентратора ввода-вывода ICH 6 R, но и утилиты Intel Application Accelerator версии 4.х, являющейся на самом деле «сборной солянкой» из драйвера и управляющего ПО, с помощью которого и производится разбивка физических жестких дисков на тома, определение их ролей и т. д.
Организация такого «псевдо»- RAID массива при помощи Intel Application Accelerator выглядит несложно – пользователь создает первый том необходимого размера, определяя и его роль – то есть в каком режиме (0 или 1) он будет функционировать. Оставшееся свободное место выделяется под второй том, также с возможностью выбора режима функционирования. После завершения этих нехитрых процедур в системе появляется два жестких диска – на одном встроенном в южный мост контроллере и двух физических накопителях SerialATA мы получаем искомую скорость и стабильность. На данном этапе недостаток состоит в том, что размеры томов фиксированы – пользователь не имеет возможности впоследствии что-либо изменить, поэтому стоит заблаговременно определить необходимые размеры.
Как же обстоит дело с горячей заменой дисков, являющейся одним из несомненных преимуществ RAID -массивов? Применительно к Matrix RAID выходит, что один из дисков нельзя удалить «на ходу», не разрушив целостность данных.
Хотя полностью исключить возможность горячего подключения также нельзя – подобная возможность существует, но для третьего физического диска. Например, если подключить к Matrix RAID -массиву третий физический диск, то он вполне может быть задействован для репликации данных с RAID 1 в случае отказа какого-либо из соответствующих дисков. Кроме того, если после изъятия диска он не был подключен в течение десяти секунд, то автоматического определения вновь подключенного накопителя не происходит – необходимо сделать принудительное обнаружение новых устройств.
Как уже упоминалось, Intel поддерживает RAID -организацию только для двух дисков, несмотря на то, что южный мост ICH 6 R имеет четыре порта SerialATA 150/ RAID. Теоретически можно организовать два Matrix RAID -массива, но они будут независимыми друг относительно друга.
Компания Intel особо подчеркивает возможность апгрейда системы до Matrix RAID, для этого требуется к имеющемуся в системе SerialATA -винчестеру добавить второй. В принципе это понятно, однако приятно, что при организации массивов данные не теряются – Intel Application Accelerator способен выполнить необходимые действия в фоновом режиме.

Рис. 2. Области применения технологии Matrix RAID В заключение теоретической части определим достоинства и недостатки Matrix RAID.
К достоинствам следует отнести:
? наличие четырехпортового контроллера SATA RAID, подразумевающего возможность создания Matrix RAID -массива;
? RAID BIOS ROM – интегрированную в системный BIOS часть, отвечающую за создание, именование и удаление массивов;
? Intel RAID Migration Technology – технологию, позволяющую производить апгрейд подсистемы хранения данных до Matrix RAID ;
? интерфейс SerialATA AHCI с поддержкой NCQ и горячего подключения ( Advanced Host Controller Interface, присутствует только в Intel 915/925);
? полное программное управление массивами Matrix RAID.
Недостатков немного, но они все же есть. Отметим главный:
? отсутствие возможности динамического изменения объемов томов.
« И опыт, сын ошибок трудных»
В действительности реализация Matrix RAID не выглядит настолько уж простой, как может показаться на первый взгляд. Первым делом стоит воспользоваться BIOS системной платы, где находится программа низкоуровневого управления RAID -массивами, называющаяся Intel Application Accelerator RAID Option ROM. Перед разметкой массивов необходимо переключить режим работы контроллера SerialATA с IDE на RAID.
При корректном подключении SerialATA -дисков (по одному диску на порт SerialATA ), RAID Option ROM автоматически определяет наличие «почвы» для создания RAID -массива, причем, по желанию пользователя, это может быть как Matrix RAID, так и стандартный RAID. На данном этапе никаких проблем в принципе возникнуть не должно, интерфейс программы дает все необходимые сведения о процессе.

Рис. 3. IOMeter— Workstation, RAID 0 (2 диска), IOps

Рис. 4. IOMeter — максимальное время отклика, мс

Рис. 5. IOMeter — Database, RAID 0 (2 диска), IOps

Рис. 6. IOMeter — максимальное время отклика, мс

Рис. 7. IOMeter — File Server, RAID 0 (2 дискa), IOps
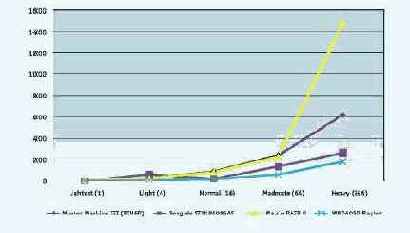
Рис. 8. IOMeter — максимальное время отклика, мс

Рис. 9. IOMeter — Database, RAID 1, IOps

Рис. 10. IOMeter — File Server, RAID 1, IOps Немаловажное обстоятельство: том Matrix RAID является загрузочным (как RAID 0, так и RAID 1), поэтому после разметки массива можно приступать к установке операционной системы. Но вот тут-то и начинаются проблемы. Несмотря на то что «новоиспеченный» Matrix RAID включает загрузочные тома и способен загрузить DOS, иногда инсталлировать Windows на один из томов не представляется возможным – инсталлятор ОС сообщает об удачно обнаруженном контроллере Intel 80801 ER без малейших признаков жестких дисков на нем. В таком случае панацеей от всех бед может стать обновление BIOS системной платы, если же и это не спасает - тогда от использования Matrix RAID стоит отказаться. Нужно помнить: установка Windows на систему с достаточно новым контроллером жестких дисков не всегда проходит гладко – ведь требуется обеспечить программу инсталляции драйверами контроллера от производителя, и вовсе не факт, что это сработает – устройство новое, драйверы, как водится, сырые, различных неувязок и несовместимостей может оказаться с избытком.
Кроме такого досадного обстоятельства существует еще множество подводных камней. Например, после установки тома RAID 0 с помощью Intel Application Accelerator и последующей перезагрузки может появиться ошибка чтения диска, обусловленная рассинхронизацией данных между дисками и программным обеспечением ( IAA в нашем случае) – данные приходят не в те моменты времени, когда ПО их ожидает. Как средство, Intel предлагает обновить IAA RAM Option ROM до более свежей версии, то есть обновить BIOS системной платы.
Не стоит забывать и о возможности подключения обычных IDE -дисков к портам SerialATA при помощи переходников – впрочем, точно поведение системы в этом случае предсказать довольно сложно. Правда, Intel не отрицает возможности такого подключения, но категорически не рекомендует его производить. Замечание, кстати, уместное для отечественного пользователя, стремящегося сэкономить в любых случаях. Так почему бы не подключить два старых IDE -винчестера по 20 Гбайт каждый через переходники и не сделать из них Matrix RAID ?
В заключение теоретических и практических изысканий хотелось бы привести результаты сравнительного тестирования, в котором участвовали «смешанный» Matrix RAID и «честный» RAID 0/1.
Тестовая платформа:
? процессор : Intel Pentium 4 ( Prescott ) 3,6 ГГц ;
? системная плата : ASUS P5AD2 Premium;
? оперативная память: Micron PC2-4300 (DDR2-533, 2x512 MB);
? жесткие диски: Western Digital WD1600JB (160 Гбайт, 7200 об/мин);
? операционная система : Windows XP Professional Service Pack 2.
Как видим, производительность «нулевой компоненты» Matrix RAID весьма высока. Более того, единственным решением, опережающим по скорости Matrix RAID 0, на сегодняшний день является RAID -массив из SCSI -дисков. Производительность массива Matrix RAID 1, хотя и не принципиальна, все же выше, чем у массива из IDE -дисков.
В любом случае решение Matrix RAID — практически единственный выход для пользователей, которые хотят добиться от своих дисков скорости и стабильности.И хотя сегодня технология выглядит «сырой», видимо, стоит подождать несколько месяцев до появления стабильных версий BIOS.
Забудьте о мегагерцах!
Евгений Патий, «Экспресс-Электроника», #11/2004
Сегодня уровень развития микропроцессоров самой распространенной из архитектур достиг той отметки, когда линейный рост тактовой частоты уже не приносит желаемого эффекта. Так, разницу между скоростью работы, к примеру текстового редактора, на процессорах с маркировкой 1200, 2200 или даже 3200 (причем не важно чего – мегагерц или рейтинговых единиц), увидеть просто невозможно. Но с другой стороны, существует целый ряд приложений, где производительности никогда не бывает много, а потому вопрос «как же ее повышать?» становится самым актуальным.
Первой данный факт признала компания Intel, кстати, негласно исповедовавшая принцип продажи мегагерц. Естественно, ею был сделан новый и, как водится, революционный ход стало — в процессорах для настольных систем компания внедрила технологию Hyper-Threading. Решение, надо признать, простое и элегантное: простаивающие ресурсы физического процессора (а это происходит всегда) отдаются «в подчинение» логическому чипу, который в результате оказывается «вторым».
Однако и здесь не все гладко. Смысл от внедрения нескольких процессоров — физических или логических — появляется лишь в том случае, когда операционная система, системные и прикладные программы «умеют» задействовать имеющиеся возможности. Хотя нужен ли второй процессор, если Windows 98 все равно работает с одним? И лишь Windows XP, более того, Windows XP с установленным Service Pack 2 уже способна адекватно работать с логическими процессорами. Подчеркнем — с логическими, то есть можно говорить о корректной поддержке технологии Hyper-Threading. Реально многопроцессорными конфигурациями операционные системы семейства Windows NT не удивишь уже давно, не говоря уже о различных *nix-клонах.
Впрочем, сегодня Hyper-Threading выглядит не так «свежо», как хотелось бы, ведь развитие полупроводникового производства открывает возможности для «усугубления» многопроцессорности на базе одного чипа – а именно полноценной многоядерности.
Как частный случай – двухъядерности. Повышенный интерес производителей процессоров к двухъядерному дизайну в немалой степени объясняется наличием такого мощного оружия, как изготовление чипов с применением технологических норм 90 нм. Уменьшение линейных размеров отдельно взятого полупроводникового элемента (естественно, транзистора) ведет к уменьшению линейных размеров всего чипа, позволяя выполнить инженерный маневр — допустим, разместить большее количество полупроводниковых элементов, формирующих, например, кэш-память второго уровня. А почему бы и не второе ядро?
В нашем случае многоядерность подразумевает, конечно же, всего два ядра, находящихся в пределах одного чипа – другими словами, это два раздельных процессора на одной кремниевой подложке. Преимущества такого подхода к проектированию высокопроизводительных процессоров очевидны, тем более что два сильнейших игрока на рынке серверных чипов уже выпустили подобные продукты – речь идет о Sun Microsystems и IBM. Если быть кратким, размещение двух процессоров в общем чипе — один из путей увеличения производительности без необходимости наращивания тактовых частот и «лишнего» энергопотребления. Иначе говоря, двухъядерный процессор, работающий с тактовой частотой ниже, чем у практически аналогичного одноядерного чипа, покажет более высокую производительность и потребует меньшее количество энергии. Хотя относительно последнего утверждения существуют вполне обоснованные подозрения, что прирост производительности будет наблюдаться исключительно для многопотоковых приложений.
Будущие многоядерные процессоры, уже тщательно проверенные в лабораториях, обеспечат симметричную мультипроцессорную обработку данных на одном кристалле. Так, пока одно ядро выполняет операцию, другое может извлекать данные из памяти или посылать команду операционной системе и т. п. При многопоточной обработке информации это приведет к гигантскому повышению производительности системы в целом. И если будущее вычислительной техники — за распределенной обработкой данных в неоднородных сетях, то многопоточная архитектура новых процессоров будет в большой степени соответствовать потребностям пользователей прикладного ПО.
Сегодня в Интернете сведения о новых двухъядерных чипах AMD крайне ограничены и зачастую противоречивы. Попытаемся создать образ будущего продукта, основываясь на имеющихся фактах, но никоим образом не претендуя на роль верховных судей. Как водится, в последний месяц перед официальным выходом процессора может измениться и дизайн, и спецификации, да и сами сроки.
У компании AMD есть сильный козырь — ввод в эксплуатацию предприятия Fab 36 в Дрездене (Германия), оснащенного оборудованием для выпуска чипов по технологическому процессу 65 нм. Специалисты компании полагают, что появление процессоров, изготовленных с применением данных норм не за горами — это 2006 год. Однако в 2005-м двухъядерные процессоры будут производиться с использованием технологии 90 нм. Если быть более точным, то 14 июля 2004-го года компания AMD объявила о завершении стадии разработки нового двухъядерного процессора. Процессор будет продаваться как Opteron для серверного рынка и Athlon 64 – для рынка настольных чипов. Конечно, речь не идет о практически одинаковых процессорах с разной маркировкой, они будут различаться частотой, объемом кэш-памяти и количеством выводов, имея лишь общую «начинку» — то, что называется dual-core. Существует три модификации двухъядерных Opteron – Egypt, Italy и Denmark, для «настольного» же двухъядерного Athlon 64 кодовое имя — Toledo.

Чип Athlon 64 Конечно, не стоит ожидать, что двухъядерные процессоры станут 32-разрядными. Архитектура IA32, как считают в AMD, доживает свой век, и новые чипы будут 64-разрядными, это даже не обсуждается.
Интегрированные в процессоры, спроектированные с учетом 64-разрядной архитектуры, контроллер памяти и шина Hyper Transport теоретически позволяют добиться от двухъядерного процессора производительности, аналогичной производительности двух раздельных процессоров, объединенных в рамках единой системы. Другое неоспоримое достоинство архитектуры AMD64 – своеобразное «предвидение» ситуации. Еще на стадии проектировании AMD64 разработчики предусмотрели возможность соединения до четырех процессоров Opteron, не используя набор системной логики, что позволяет без особых проблем объединить на одном кристалле кремния два процессорных ядра, так как все необходимые компоненты уже присутствуют.
По заявлению аналитика компании Mercury Research Дина МакКэррон, «чипы давно уже имеют многопроцессорный дизайн, просто изменилось физическое расположение ядер» — все, на первый взгляд, очень просто.
Немаловажное обстоятельство: в грядущих двухъядерных процессорах будет использоваться общий контроллер памяти. Он позволит избежать пресловутого «бутылочного горлышка» в конечной системе с точки зрения пропускной способности. Например, сегодняшний сервер на базе двух чипов AMD Opteron имеет, соответственно, два контроллера памяти, что обусловливает вполне достаточную пропускную способность: можно смело объединить два ядра, используя один общий контроллер.
Итак, двухъядерные процессоры будут совместимы с нынешними процессорными разъемами и, следовательно, с системными платами, отвечающими требованиям многоядерных процессоров. Потребуется обновление BIOS, но в целом новые чипы должны без проблем работать с платами сегодняшнего дня.
В отношении энергопотребления процессоров AMD собирается по-прежнему придерживаться своей нынешней тактики. Коль скоро имеются три градации энергопотребления — 30, 55 и 89 Вт, — есть все основания предполагать, что двухъядерные чипы будут им соответствовать.
Есть сведения, что двухъядерный процессор от AMD появится в форм-факторе Socket 939, будет изготавливаться по технологии «кремний-на-изоляторе» и 90-нм техпроцессу.
Точной информации о размерах ядер и количестве входящих в них транзисторов пока нет, однако можно сделать кое-какие предположения. Итак, площадь ядра ClawHammer с 1 Мбайт кэш-памяти второго уровня составляет 193 кв. мм. Для настольных систем данная площадь ядра выглядит великоватой, однако для серверных процессоров это не является проблемой.
Площадь собственно ядра ClawHammer составляет 28%, или 54 кв. мм, площадь 1 Мбайт кэш-памяти второго уровня – 42%, или 81 кв. мм, площадь блока северного моста и ввода-вывода – 30%, или 58 кв. мм.
Если мы предположим, что в двухъядерном процессоре у каждого ядра есть собственная кэш-память второго уровня объемом 1 Мбайт, то у нас будет: два ядра, два блока кэш-памяти и один общий блок северного моста и ввода-вывода, то есть без малого удвоенная площадь ядра ClawHammer.
С учетом перехода на более тонкий технологический процесс (90 нм против 130 нм) – площадь двух ядер составляет 33%, или 65 кв. мм, площадь двух блоков кэш-памяти – 49%, или 97 кв. мм, площадь блока северного моста и ввода-вывода – 18%, или 35 кв. мм. Итого, общая площадь двухъядерного процессора Opteron составит примерно 197 кв. мм.
Постараемся прояснить, каким же образом AMD удалось просто добавить еще одно процессорное ядро в чип, и обратимся к приведенной схеме.
Компания AMD не пошла по накатанному пути Intel, которая ранее просто использовала свободные ресурсы единого физического процессорного ядра для имитации логического второго процессора. Вместо этого реализовано второе физическое процессорное ядро с использованием шины Hyper Transport для межпроцессорных связей. На приведенной блок-схеме показано, каким образом компания AMD изначально предусмотрела потенциальную возможность установки на чип второго процессорного ядра. Основная идея состоит в том, что механизм, названный очередью системных запросов (System Request Queue, SRQ) может взаимодействовать с двумя процессорными ядрами «0» и «1». В нынешних чипах AMD присутствует только ядро «0», однако видно, что добавление второго ядра («1») требует минимальных усилий – вся необходимая инфраструктура присутствует с самого начала.
Одно из главных преимуществ двухъядерной архитектуры AMD перед технологией Intel Hyper-Threading — каждое процессорное ядро использует собственную кэш-память второго уровня. Не секрет, что одной из основных проблем при построении многопроцессорных и многоядерных систем является «борьба» за память. Если запущенное приложение достаточно мало и полностью помещается в кэш-памяти, то особых проблем не возникает, но сегодня время больших массивов данных. Работа с большими изображениями, обработка видеомассивов и баз данных означает интенсивное использование оперативной памяти. Именно поэтому столь существенная часть системы, как встроенный в процессоры Athlon 64 и Opteron собственный контроллер памяти, обусловливает взрывообразный рост производительности.
Борьба двух процессорных ядер за данные из основной памяти — факт отнюдь не новый. Такая же ситуация наблюдается и в более старых системах, оснащенных процессорами Xeon или Athlon MP (в таком случае ситуация далеко не радужна – в таких системах используется один двухканальный контроллер памяти для всех процессоров в системе). В подобных системах процессоры осуществляют запросы на доступ к основной памяти у контроллера памяти, находящегося, как правило, в северном мосту набора системной логики, и потому (в общем случае) прирост производительности с этой точки зрения составляет не более 50% по сравнению с однопроцессорной системой. Двухъядерная архитектура Athlon 64 и Opteron несколько больше, чем просто старая двухпроцессорная схема в рамках одного чипа.
Определенное преимущество размещения двух ядер (даже по старой двухпроцессорной схеме) на одном чипе – заметное уменьшение задержек, но маловероятно, что система с одним двухъядерным процессором Opteron будет показывать более высокую производительность, нежели система с двумя одноядерными Opteron. Последняя имеет два массива памяти, поэтому проблем с доступом к памяти, как у системы с двухъядерным Opteron, в данном случае не возникает.
На рынке присутствуют системные платы для двух процессоров Opteron, имеющие только один массив памяти, второй процессор получает доступ к памяти с помощью шины Hyper Transport. Конечные системы, собранные на основе данных плат, гораздо медленнее тех, что используют системные платы с раздельными для каждого процессора массивами памяти. Представляется, система на базе двухъядерного Opteron должна находится по производительности где-то между двумя вышеописанными случаями.
Стоит сказать несколько слов о шине Hyper Transport, которая будет применяться для межъядерных соединений в процессоре. Текущая версия Hyper Transport позволяет достичь пиковой скорости обмена данными 6,4 Гбайт/с (3,2 Гбайт/с в каждую сторону) на частоте 800 МГц — этого явно недостаточно для соединений между двумя процессорными ядрами одного чипа.
Видимо, для данного применения будет использоваться шина Hyper Transport с большей пропускной способностью.
Существует некая неопределенность относительно производства двухъядерных процессоров. Известно, что в любом случае, даже при использовании технологического процесса 90 нм, два процессорных ядра будут иметь большие линейные размеры, нежели единственное ядро, производящееся по техпроцессу 130 нм. Итого, на одну кремниевую пластину поместится меньше процессоров – ведь, по некоторым сведениям, AMD до сих пор использует кремниевые пластины диаметром 300 мм (это справедливо и для Fab 36 в Дрездене, «стартовый» техпроцесс которой – 65 нм).
Компания Intel также проявляет необычайную активность в данной области, вполне отдавая себе отчет, что «виртуальная двухъядерность», обусловленная технологией Hyper-Threading, никоим образом не может противостоять многоядерности реальной, невзирая на все свои преимущества. В мае текущего года Intel отменила планы по выпуску чипов, известных широкой общественности под кодовыми именами Tejas и Jayhawk, и предпочла заняться новыми двухъядерными продуктами для серверов и рабочих станций, чьи кодовые имена пока не обнародованы. Приблизительные сроки выпуска двухъядерных решений от Intel для серверов, рабочих станций и портативных компьютеров – 2005-й год.
Одной из перспективных задач, по мнению Intel, является переход от логического к физическому параллелизму. Как отмечает президент Intel Пол Отеллини, не стоит торопиться с выпуском "настольных" чипов с несколькими ядрами — компания будет следовать ранее намеченному плану. "В любом случае, - подчеркивает он, - наборы системной логики для десктопных многоядерных процессоров будут отличаться по своей архитектуре от чипсетов для обычных Pentium 4". Слухи о переводе Prescott на двухъядерное исполнение решительно отметаются представителями Intel. В самом деле, с точки зрения тепловыделения такой шаг равноценен безумию, ведь именно ради обратного эффекта было решено отказаться от выпуска Tejas.
Интересно, что президент Intel считает более перспективными именно процессоры с несколькими ядрами, а не чипы, поддерживающие 64-разрядные приложения, поскольку далеко не всегда 64-разрядность будет востребована, а переход на такие приложения продлится куда дольше, чем переход на ПО с поддержкой нескольких ядер.
В настоящее время вполне реальным является серверный чип с кодовым названием Montecito. И если на весеннем IDF ‘2004 в Калифорнии была показана кремниевая подложка с Montecito (двухъядерный Itanium), то к осени широкой общественности представили работающий прототип процессора, который должен пойти в серию в 2005 году. Помимо двухъядерности, Montecito будет обладать и многопоточностью, то есть операционная система будет видеть единственный процессор как четыре.
Чего стоит одно только количество транзисторов на кристалле Montecito — 1,72 млрд, которое объясняется в первую очередь поистине огромным объемом кэш-памяти третьего уровня — 24 Мбайт (по 12 Мбайт на каждое ядро). При этом задержки кэша третьего уровня останутся такими же, как и в нынешних процессорах Itanium 2. Объем кэш-памяти второго уровня у Montecito составит 1,25 Мбайт (256 кбайт — для данных, 1 Мбайт — инструкции), первого уровня — 64 кбайт (по 32 кбайт для данных и инструкций). Предусмотрены и так называемые буферы промахов, контролирующие работу кэш-памяти второго и третьего уровней.

Архитектура Montecito Как сказано выше, в каждом из ядер Montecito предполагается реализовать многопоточную обработку (по два потока в каждом ядре). На одном кристалле будет два ядра и, соответственно, четыре потока инструкций. Иными словами — четыре логических процессора, то есть в системах, аналогичных сегодняшним четырехпроцессорным на базе Itanium 2, получится 16 потоков инструкций, или 16 логических процессоров.
Ожидается, что производительность Montecito будет значительно выше, чем у нынешних Itanium 2 и тех, которые выйдут в ближайшее время. Это неудивительно — большой объем кэш-памяти и более высокая тактовая частота в сочетании с многоядерностью, многопоточной обработкой и более совершенной технологией изготовления должны сделать свое дело.
Список новаций, которые планируется реализовать в новом процессоре, пестрит хорошо известными кодовыми именами — Silvervale (серверный вариант технологии виртуализации, позволяющей процессору поддерживать на аппаратном уровне одновременную работу нескольких операционных систем), Pellston (повышение надежности кэш-памяти за счет отключения неисправных сегментов), Foxton (динамическое переключение тактовой частоты и рабочего напряжения в зависимости от вычислительной нагрузки). Схема арбитража в Montecito реализуется при помощи так называемого snoop-контроллера, отслеживающего выполнение инструкций в обоих ядрах. Еще один интересный механизм под названием Dynamic Thread Switching (динамическое переключение потоков) способен, как утверждают в Intel, фиксировать обработку операций, связанных с длительными задержками, и инициировать переход к обработке соседнего потока инструкций.
Montecito будет выпускаться по технологии 90 нм (при изготовлении нынешних Itanium 2 с ядром Madison используется техпроцесс 130 нм). В настоящее время двухъядерный Montecito, изготавливаемый с применением норм 90 нм, представлен в кремне начальным степпингом A0).
Если вам часто приходится заниматься
Если вам часто приходится заниматься обработкой музыкальных файлов и изменением формата видеофайлов, то многоядерность — это однозначно то, что вам нужно. Именно здесь работает формула 1+1 = 2. То есть добавление второго ядра может привести к повышению производительности до 90%. Во всех остальных случаях ситуация выглядит не столь радужно. Однако даже в офисном ПК на сегодня найдется не одна программа, желающая загрузить второе ядро. Хочется надеяться, что оптимизация популярных приложений не заставит себя ждать — и тогда новые (и не только новые) процессоры смогут полностью реализовать свой потенциал. Что касается самых больших консерваторов в этом деле — производителей игр, то уже в следующих версиях компании Epic (создатели Unreal) и Crytek (создатели Far Cry) полностью поменяют ядро физики.
Многоядерные процессоры: первые попытки
А.Н. Бондаренко.
Компьютеры+Программы
В программах, которые оптимизировались для использования Hyper-Threading, Pentium D 840 почти вдвое быстрее своих одноядерных предшественников.
Какими будут многоядерные процессоры будущего, нам пока не известно — но мы точно знаем, что основной тенденцией в развитии процессоров на ближайшее время будет именно многоядерность. И первые серийные образцы таких процессоров уже доступны (правда, пока только в составе готовых систем). И по ним уже можно сказать, что компания Intel движется в сторону многоядерности достаточно осторожно. Pentium Extreme Edition 840, уже протестированный нашими коллегами из IDG, являет собой фактически два отдельных процессора, объединенных в одной упаковке. Несмотря на кажущуюся простоту, при этом решались достаточно сложные задачи по скоординированному использованию процессорами FSB и реализации энергосберегающих технологий, использование которых зависит от внутреннего состояния обоих процессоров. Так что Pentium EE 840 можно рассматривать как первую попытку многоядерности, предназначенную для обкатки взаимодействия ядер на самом общем уровне.
С экономической точки зрения объединение двух независимых ядер в одной упаковке тоже вполне оправданно. Фактически пластину с выращенными ядрами процессоров можно разрезать и по одному ядру, и по парам. Режим работы уже готового процессора определяется коммутацией в упаковке. Так что, выпуская всего одно ядро, можно делать весь спектр процессоров — от одно- до многоядерных.
Однако такой подход может и не стать основным, поскольку имеет заметные недостатки. Прежде всего, это неоптимальное использование кэш-памяти. Этот изъян характерен и для обычных многопроцессорных систем. Независимые процессоры с большой вероятности кэшируют одни и те же данные, и при их модификации необходим механизм взаимного уведомления процессоров и актуализации их кэш-памяти.
Очевидно, что и с точки зрения максимизации размера кэш-памяти, и с точки зрения минимизации потерь времени на ее разделение, кэш-память должна быть общей для всех ядер. Однако собрать такой процессор из нескольких независимых заготовок невозможно. Тут необходима разработка абсолютно нового ядра — а это долго и дорого. Так что интрига даже в таком вроде бы частном вопросе будет сохранятся еще долго.
Пока же первая двуядерная платформа Intel включает, помимо "сдвоенного" процессора Pentium Extreme Edition 840 (обратите внимание, цифры "4" после Pentium нет), также набор микросхем Intel 955X Express. Pentium EE 840 имеет тактовую частоту 3,2 ГГц, частоту системной шины 800 МГц и 2 Мб кэш-памяти второго уровня (по 1 Мб на каждое ядро). Каждое ядро поддерживает Hyper-Threading, поэтому в системе видны четыре процессора.
Чуть позже (во второй половине года) должны начаться продажи процессоров Pentium D серии 8хх. Это будут Pentium D 840 (3,2 ГГц), 830 (3,0 ГГц) и 820 (2,8 ГГц), которые будут отличаться от Extreme Edition, в основном, отсутствием Hyper-Threading. Появится и более демократичный чипсет — Intel 945.
Производительность
Грустный факт: скоростной потенциал процессоров, как никогда прежде, стал зависеть от качества работы программистов. Грустно все это потому, что критерии оценки результатов труда разработчиков софта и железа слишком уж разные. Об оптимизации софта начинают думать уже после его коммерческого успеха. И никогда раньше успех массового ПО не зависел от его "распараллеливаемости". Не зря именно Intel взялась за разработку инструментария для написания "правильных" программ и оптимизации существующих.
Рисунок 1.
На сегодня же даже без тестирований можно сказать, что полностью готовы к использованию многоядерных процессоров, в общем-то, те же программы, которые и раньше неплохо использовали Hyper Threading. В основном, это программы обработки потоковых данных — аудио и видео.
Таблица 1.
В нашем тесте Pentium Extreme Edition 840 работал на предсерийной материнке Intel D955XBK с чипсетом D955X и с двумя 512 Мб модулями памяти DDR2-667.
Сравнивалась эта система с Pentium 4 660 на материнке Intel D925XECV2 (чипсет i925XE) и с двумя 512 Мб модулями памяти DDR2-533 Corsair CM2X512.
Прочие параметры стендов: графика: MSI Geforce 6800 GT с 256 Мб памяти, драйвер Forceware66.77; HDD: Serial-ATA Maxtor Maxline III 250 Гб; ОС: Windows XP Professional SP2.
Результаты тестирования (кстати, весьма показательные) — в таблице ниже.
Таблица 2.
Игровые тесты тоже производились, однако ситуацию в играх достаточно хорошо иллюстрируют результаты 3D Mark 2003 CPU, также приведенные в таблице. Во всех играх Pentium Extreme Edition 840 уступает Pentium 4 660. В основном это "заслуга" создателей игр, которые пока не "параллелят" свои творения. Не исключено, что ситуация изменится — компания Intel уже довольно давно начала распространять новую платформу именно среди производителей игр.
В тесте Sysmark 2004 в дисциплине Office Productivity многоядерность не сыграла заметной роли. Другое дело — Internet Content Creation.Здесь уже присутствуют элементы обработки потоковых данных — а такие работы хорошо параллелятся. Adobe Photoshop, 3D Studio Max и Windows Media Player, использующиеся в этом подтесте, показывают до 30% прироста производительности.
Не менее хорошо заметен эффект от многоядерности в CineBench, который и раньше умел использовать все доступные процессоры, и в Spec CPU2000, который мы запускали в режиме "rate_base", позволяющем выполнять на каждом физическом и виртуальном ядре копию теста.
Nero Recode 2.2.6.9 от Ahead мы использовали, чтобы сжать фильм "Никита" с четырех до одного гигабайта. Это приложение многопоточное, поэтому эффект од многоядерности очень заметен.
Эффектный закат "гигагерц-ориентированной"
Сергей Антончук, "Комиздат"
Последнее обновление в продуктовой линейке Intel, процессор Intel Pentium 4 Extreme Edition 3.46 ГГц с технологией HT, имеет практически ту же частоту ядра, что и предшественник, но более быструю FSB в 1066 МГц.
Совсем недавно IT-общественность была взбудоражена сообщением компании Intel о том, что производство чипов с частотой 4 ГГц пока откладывается, а основное внимание компании переносится на многоядерные процессоры и архитектуры систем. Комментариев по этому поводу было много. Хотя большая часть из них просто была связана с тем, что компания Intel кардинально начала ломать стереотип "скорость=частота". То, что повышение частот в мейнстрим-сегменте откладывается, совсем не означает, что откладывается выход более быстрых процессоров для обычных систем. Резервов повышения производительности пока более чем достаточно и без повышения частоты ядра процессора. И основной резерв - это, как ни странно, не технологический, а "идеологический" резерв. Современный ПК уже нельзя рассматривать как просто вычислительную платформу. Современный ПК - это центр обработки различных по своей природе и интенсивности информационных потоков, которые не всегда должны проходить через процессор или обрабатываться им.
Это стало заметно уже довольно давно, но только недавно архитектура массовых ПК стала строиться исходя из таких принципов. Массово появившиеся четыре месяца назад PCI Express платформы и стали началом этих изменений, причем настолько многочисленных и радикальных, что не все заметили главного :). ПК стал центром коммутации и обработки информационных потоков. И шина PCI Express создала прочный скелет для этой архитектуры, которая теперь может развиваться и наращивать свою производительность во многих направлениях.
И собственно появление нового процессора, Intel Pentium 4 Extreme Edition с эффективной частотой FSB 1066 МГц, - это в некоторой степени просто отражение изменений в околопроцессорной архитектуре, направленных на повышение общесистемной производительности. Именно здесь компания Intel видит большой резерв в повышении производительности системы в целом.
Pentium 4 EE 3,46 c FSB 1066, новый флагман процессоростроения, вышел в свет вместе с модернизированной платформой Intel 925XE Express, также поддерживающей новую частоту FSB. Изменение это было запланированным. О нем компания заявляла еще при появлении семейства LGA775 процессоров и чипсетов i915/i925.
P4ee
Технические характеристики процессора Intel Pentium 4 3,46 EE
Сокет - LGA775
Тактовая частота, МГц - 3460
Front Side Bus, МГц - 266
L1-Cache, Кб - 8
L2-Cache, Кб - 512
L3-Cache, Кб - 2048
Наборы инструкций - MMX, SSE, SSE2
64-битные расширения - Отсутствуют
Hyper-Threading - Присутствует
Максимальная потребляемая мощность, Вт - 110,7
В новой связке "процессор-чипсет-память" частоты элементов и шин, их соединяющих, являются наиболее согласованными. Эффективная частота FSB - 1066 МГц, то есть ее физическая частота составляет 266 МГц (процессорная шина Pentium 4 является Quad Pumped, то есть передает четыре бита информации на каждый такт синхронизации). Такую же частоту имеет интерфейс памяти DDR2-533. Таким образом, физические частоты соотносятся как 1:1, а эффективные - как 2:1. Для всех остальных систем, использующих память DDR2-533, эти соотношения дробные, то есть они работают в асинхронном режиме, который неизбежно ведет к потерям производительности. Поэтому степень повышения пропускной способности памяти в новой системе превышает просто соотношение частот FSB - 1066 к 800, оно несколько больше.
Кроме синхронного режима работы, новый процессор имеет еще несколько преимуществ. Прежде всего это:
* Встроенный в процессор кэш L3 объемом 2 Мб, обеспечивающий быстрый доступ к большим объемам часто используемых данных. Его использование позволяет сократить среднее время доступа к основной памяти и повысить ее пропускную способность.
* Advanced Transfer Cache L2 объемом 512 Кб - работающий на частоте ядра процессора 256-разрядный кэш с развитым механизмом предварительной выборки данных.
Enhanced floating-point/multimedia unit. Регистры для работы с вещественными числами расширены до 128 бит, и добавлен дополнительный регистр для пересылки вещественных данных. Это позволяет повысить производительность и в вычислительных, и в мультимедийных задачах.
* Rapid Execution Engine. Четыре целочисленных АЛУ работают на удвоенной частоте ядра процессора, что позволяет увеличить вычислительную пропускную способность и снизить время выполнения некоторых целочисленных операций.
* Execution Trace Cache.
Модернизированный кэш инструкций L1 убирает задержки в при считывании декодированных инструкций. Это позволяет значительно повысить эффективность работы кэша по сравнению с кешированием самих инструкций. Данный подход позволяет значительно поднять производительность подсистемы памяти при выполнении повторяющихся фрагментов программного кода. * Advanced Dynamic Execution. Механизм улучшенного предсказания ветвлений позволяет повысить производительность для всех типов приложений путем оптимизации последовательностей выполняемых команд. * Расширены и возможности чипсета. Чипсет Intel 925XE теперь поддерживает работу с более быстрой памятью DDR2 533 CL3. Основная ее особенность - меньшая латентность доступа. Именно большое время доступа многие раньше считали основным недостатком памяти DDR2 533. Следует также отметить, что память типа DDR2 400 этим чипсетом не поддерживается. Эффективность изменений Естественно, нас заинтересовал практический эффект от модернизации основных скоростных характеристик "околопроцессорной" части архитектуры. Поэтому мы провели сравнение двух примерно равных по частоте и по архитектуре процессоров Pentium 4 EE 3,4 ГГц (FSB 800 МГц) и Pentium 4 EE 3,46 ГГц (FSB 1066 МГц). Платформа была одна - это материнка Intel Desktop Board D925XECV2, 1Гб памяти DDR2 533, видеокарта ATI X800XT, винчестер Maxtor MaXLine III 250Гб. Так что разницу в результатах можно смело относить именно на изменение скорости FSB. Результаты тестов и оценка прироста приведены в таблице. Как мы видим, прирост производительности составляет от 2 до 8% в зависимости от используемых приложений. Это только эффект от повышения частоты FSB. Что осталось у нас незадействованным, так это использование памяти DDR2 533 CL3. Как только она появится, мы проанализируем эффект и от нее. В ближайшей перспективе следует также ожидать поддержки памяти DDR2 667, стандарт на которую утвержден и которая уже появляется на рынке. По заявлению некоторых производителей материнских плат, им не нужно будет делать никакого редизайна существующих плат для поддержки этой памяти.
Правда, в этом случае и для FSB 800, и для FSB 1066 система будет работать в асинхронном режиме. В несколько отдаленном будущем следующей "красивой" комбинацией станет DDR2-800 и FSB 800. Это действительно будет интересно, все соотношения будут 1:1. Так что и без повышения частот процессоров скучать не придется.
Что было раньше?
Во-первых, напомним, что шина PCI, бывшая буквально до последнего времени безусловным стандартом, не так давно отметила десятилетний юбилей - а это, согласитесь, в компьютерном летоисчислении аналогично отрезку времени от египетских пирамид до наших дней. Еще в далеком 1991 году компания Intel представила первую спецификацию системной шины, известной как Peripheral Component Interconnect, которая в сжатые сроки вытеснила устаревшую даже по тем временам шину ISA, верой и правдой прослужившую очень долго, а также ее более дорогую и менее удачную серверную сестру EISA.
Что можно сказать о шине PCI? Во-первых, пропускная способность PCI была гораздо выше пропускной способности ISA. Во-вторых, важнейшее различие этих двух интерфейсов - возможность динамического конфигурирования периферийных устройств, подключенных к PCI, то есть система распределяет ресурсы между периферийными устройствами наиболее приемлемым в данный момент времени образом и без постороннего вмешательства.
Итак, начало положено. Вряд ли кто-то из разработчиков тогда думал о том, какая долгая жизнь уготована интерфейсу PCI (мы говорим не конкретно о версии 1.0, а о Peripheral Component Interconnect вообще). Однако толчком к бурному росту числа продуктов, ориентированных на использование с шиной PCI, стало появление двумя годами позднее второй редакции стандарта PCI, 2.0 - и с этого момента началось медленное, но уверенное «выдавливание» с арены ветеранов ISA и EISA.
До сих пор все прекрасно помнят основные параметры PCI 2.0 - это, конечно, ширина шины, равная 32 битам, максимальное адресуемое адресное пространство 4 Гбайт, тактовая частота шины 33 МГц при синхронном обмене данными и пиковая пропускная способность 133 Мбайт/с. И напоследок: устройства были рассчитаны на напряжение питания 5 В и 3,3 В. По сегодняшним меркам - смехотворные цифры. Но в 1993 году такие величины казались поистине громадными.
Со временем появилось множество вариаций на тему PCI 2.0, наиболее распространенные из которых - стандарт PCI 2.2, стандарт AGP, PCI-X, mini-PCI и Card Bus (32-разрядная версия стандарта PCMCIA, допускающая горячее подключение).
Каковы основные шаги в развитии PCI с точки зрения вышеупомянутых вариаций? Наиболее заметна для конечного пользователя была, естественно, шина AGP, являющаяся, тем не менее, частным случаем PCI 2.0.
AGP предназначена для использования с производительными графическими адаптерами, которым недостаточно даже пиковых скоростных значений PCI 2.0. AGP характеризуется отсутствием арбитража интерфейса - допускается подключение к этой шине только одного устройства; хотя, версия AGP 3.0 нивелирует это ограничение, к ней можно подключить уже два устройства (при наличии, разумеется, двух соответствующих разъемов на системной плате). Шина AGP появилась в четырех вариациях, которые различаются между собой пиковой пропускной способностью - AGP 1x, 2x, 4x и 8x. Несмотря на то что скоростей четыре, стандартов AGP три - AGP 1.0, 2.0 и 3.0. Кроме того имеется спецификация на питание шины AGP Pro. Не менее ярко выступил стандарт PCI 2.2, в котором ширина шины может быть увеличена до 64 бит, а также допускается «разгон» тактовой частоты до 66 МГц - вдвое по сравнению с PCI 2.0. Еще дальше пошла PCI-X - это ни что иное, как ускоренная до 133 МГц шина PCI 2.2 с обязательно 64-битной разрядностью интерфейса. PCI-X выпускалась и в более форсированных вариантах, с 266 МГц и 533 МГц тактовой частотой. Менее заметна, но не менее важна шина mini-PCI, применяющаяся в портативных компьютерах для подключения различной «мелкой» периферии. Из вышесказанного следует, что удачная разработка PCI развивалась отнюдь не линейно - встречались и ветвления для узкоспециализированных применений: AGP - графика, PCI 2.2 - периферийные потребительские устройства, PCI-X - серверная периферия, mini-PCI и Card Bus - нашли место в ноутбуках. Пиком скоростного развития стандарта PCI можно назвать PCI-X 533 и AGP 8x. А дальше - общеизвестная история: основные компоненты вычислительных систем, процессоры и память выросли из детских штанишек межкомпонентного интерфейса, что, в принципе, не так уж и страшно. Беда в том, что далее наращивать пропускную способность PCI оказалась технологически сложно и дорого. Например, для того чтобы не мудрствуя лукаво наращивать тактовую частоту, требуются дополнительные проверки для исключения сбоев - новая разводка, новые сигналы, что в конечном итоге отражается на стоимости решения.Требуется совершенно новая разработка, гарантирующая «безболезненную» масштабируемость и наращиваемость на ближайшие несколько лет.
Что впереди?
На сегодняшний день четко очерчены границы применения шины PCI Express. В привычных настольных компьютерах этот стандарт должен упразднить лишь шины PCI и AGP, грубо говоря, «PCI и компанию». Нет оснований полагать, что PCI Express станет связующим звеном для дисковой подсистемы, подсистем памяти и процессора, его удел - периферия. Более широкий круг задач - на рынке портативных систем; помимо подключения внутренних периферийных устройств PCI Express будет применяться для связи с док-станциями ноутбуков и внешними периферийными картами, которые придут на смену сегодняшним PC Card.
Производительные рабочие станции и серверы смогут задействовать PCI Express и для подключения дисковых массивов. В целом, судя по спецификациям, будущее этого интерфейса достаточно безоблачно: особую надежду вселяют значения пропускной способности 2,5 Гбит/с на канал, определенные в качестве стартовых - значит, есть куда расти. Небольшая ложка дегтя, выраженная в необходимости отдать 20% трафика по шине на служебные нужды, не может служить весомым поводом для беспокойства. Ведь по большому счету, если переживать из-за всех уступок человека железу, можно впасть в состояние перманентной депрессии. А если вспомнить о восторгах со стороны многочисленных производителей периферийного оборудования по поводу PCI Express, тем более, можно жить и радоваться. Но вернемся к названию статьи: утопия ли PCI Express? Нет, это вполне сбалансированное и своевременное решение. PCI Express - попытка общей стандартизации? Тоже нет, ведь всех под одну гребенку все равно не причесать. Чем же тогда все-таки является PCI Express? Пожалуй, требованием времени.
PCI Express, в девичестве «Arapahoe»
О грядущем тупике разработчики, конечно же, догадались отнюдь не вчера. Еще в пору ожидания AGP 3.0 в Интернете вовсю ходили слухи о новом межкомпонентном интерфейсе, разрабатываемом в недрах Intel под кодовым названием Arapahoe, сейчас 3GIO (Third Generation In-Out - ввод/вывод третьего поколения). Главным отличием этого решения должен был стать последовательный интерфейс. Это означало, во-первых, однозначное подключение «точка-точка», исключающее арбитраж шины и перетасовку ресурсов (как частный случай: прерываний). Во-вторых, упрощалась схемотехника, разводка и монтаж. В-третьих, экономилось место. Огромный плюс - отпадает необходимость в громоздкой синхронизации сигналов. Ведь при параллельной организации передачи все происходит на «делай раз, делай два», биты приходят от источника к приемнику не вразнобой, а «строем». Кстати, с увеличением таковых частот синхронизация добавляла разработчикам немало головной боли. На самом деле преимуществ последовательных интерфейсов перед параллельными гораздо больше, но они относятся, в основном, уже к «дебрям».
Итак, новая последовательная шина, которой предписывалось решить все проблемы компьютерной отрасли разом, получила название PCI Express - это случилось 22 июля 2002 года. Основной двигатель прогресса здесь, конечно же, корпорация Intel. Более того, существует весьма любопытный факт - несмотря на то что компания AMD делала большие ставки на свою шину Hyper-Transport, даже ее Intel удалось склонить на сторону продвижения PCI Express. Это обстоятельство стало буквально козырной картой интерфейса, и теперь IT-общественность не сомневается: PCI Express - быть. Давайте разберемся, чему собственно быть.
Во-первых, новая шина теоретически должна выступить в качестве основного транспорта между всеми, без исключения, узлами компьютера. В самом деле, ведь предшественница PCI ввиду своего отставания от требований к пропускной способности с течением времени оказалась постепенно вытесненной из основного «круговорота»; и выглядела уже не как первостепенной важности элемент, а, если хотите, как обуза.
Процессор с памятью, диски Serial ATA, даже сетевые контроллеры - все компоненты обходились своими собственными соединениями. Что же оставалось PCI? Диски Parallel ATA, модемы, сетевые да звуковые карты. Согласитесь, не совсем достойная участь для некогда революционной разработки. В общем, при разработке спецификаций нового стандарта Intel не стала изобретать ничего кардинально нового - в ход пошли передовые наработки из сетевой отрасли. Много внимания инженеры уделили и кодированию информации с устойчивостью к ошибкам. Опираясь на два этих факта, можно сказать, что PCI Express - это очень современно. Также стоит вспомнить, что подобный подход уже однажды был применен Intel на этапе внедрения процессора Pentium 4: как необычно звучало словосочетание Intel Hub несколько лет назад… PCI Express - последовательный интерфейс, имеющий много общего с сетевой организацией обмена данными. Сетевые термины, наподобие Hub, уже прочно вошли в лексикон не только системных администраторов, но и схемотехников: в современных платформах основной связующий компонент системной платы носит название Root Complex Hub, который выглядит как перекресток трех шин - процессорной, шины памяти и PCI Express. На данном этапе Root Complex представляется как некий альтернативный узел, снабженный одним или несколькими портами PCI Express. Для взаимодействия с остальными узлами ПК, которые так или иначе обходятся собственными шинами (это не обязательно процессорная шина и шина памяти, некоторое время неизбежно присутствие и старинных PCI 2.2 или PCI-X) предусмотрена система мостов и свитчей. Логика всей структуры такова, что любые межкомпонентные соединения непременно оказываются построенными по принципу «точка-точка», тем более, ни о какой широковещательности речь не идет, вышеупомянутые свитчи-коммутаторы выполняют однозначную маршрутизацию пакета от отправителя к получателю. Коммутаторы могут выполнять и более интеллектуальные функции, нежели простой роутинг данных. Имея последовательно-сетевую природу, стек PCI Express разделен на три уровня: аппаратный (Physical - физический), аппаратно-логический (Data link - передача данных) и логический (Transaction - транзакции).
Начнем с аппаратного - здесь есть как новинки, так и аксиомы принципов передачи информации. Уже не раз говорилось, что стандарт PCI Express «исповедует» последовательную передачу данных. На аппаратном уровне реализовано разностное усиление сигнала (сигнальный уровень PCI Express составляет 0,8 В): по одному проводнику передается положительное аналоговое представление сигнала, по второму - отрицательное. Разностный приемник сигнала на другом конце линии инвертирует принятый сигнал и складывает с сигналом, прибывшим по другому проводнику, поэтому, если где-либо сигнал был «разбавлен» помехой (которая подвергла воздействию оба проводника), то она сама себя нивелирует. PCI Express построен на принципах симплексной технологии, а это означает, что сигналы идут одновременно, в противоположных направлениях и по отдельным парам проводов - итого две пары, называемые линией. Стандарт декларирует пропускную способность симплексной линии на отметке 2,5 Гбит/с в одну сторону или, соответственно, 5 Гбит/с в обе стороны. Однако эти значения масштабируемы. Как всегда, и применительно к PCI Express не обошлось без компромиссов и обходных путей. Указанные значения пропускной способности являются идеальными - то есть в реальной жизни они, к сожалению, не достигаемы. Из-за традиционных технологических неувязок разработчики отказались от применения отдельной линии для синхросигналов, поэтому пришлось идти в обход - урезать длину последовательности нулей и единиц, которые могут вызвать проблемы с синхронизацией. Приемник воспримет входящий сигнал как постоянный ток, не различая начала и конца любой последовательности данных - впору даже лампочку подключать. Пришлось сделать «новый байт для PCI Express», состоящий из десяти бит, которые уже можно отделить друг от друга. Восемь бит - хрестоматийные, два бита - служебные. В итоге - 20%-ную избыточность, а значит, 20% от заявленных 2,5 Гбит/с и 5 Гбит/с мы так и не увидим. То есть синхронизация все-таки имеется, но выполнена она таким оригинальным образом.
Что же случится, если по шине не проходит никаких данных? Велика возможность рассогласования между отправителем и адресатом, поэтому трафик на шине PCI Express не прекращается никогда: в отсутствие данных посылаются специальные последовательности из нулей, закодированные по все той же десятибитной схеме. При инициализации линии, связывающей две точки (отправителя и адресата), происходит пересылка специальных начальных последовательностей. В этих последовательностях могут быть закодированы параметры соединения. Во время сеанса связи могут возникнуть и такие неприятности, как несоответствие работы тактовых генераторов передающей и приемной стороны. Для того чтобы поправить положение, периодически в потоке данных передаются специальные корректирующие последовательности. Степень необходимости внедрения корректирующих последовательностей определяется исходя из разницы между показателями тактовых генераторов. В любом случае дополнительные кодирующие последовательности, как и необходимость внедрения избыточности с целью синхронизации, негативно сказываются на производительности, так как неизбежно влекут за собой временные потери. Для организации связи в реальном времени такой путь не подходит, поэтому разработчикам таких критичных к латентности систем придется изобретать собственные протоколы обмена. Можно сказать, что на данном этапе последовательная передача, как таковая, заканчивается. Единственное соединение, представляющее собой линию PCI Express, две пары проводов, - этого не достаточно для обеспечения высокой пропускной способности. Поэтому линии привычно выстраивают в ряд - их может быть 32, 16, 12, 8, 4 и 2. В итоге, вся последовательность данных, которую необходимо передать, распределяется на все имеющиеся линии «веером»- передача параллельная, но не синхронная. Если имеется 12 линий, то первый байт блока данных передается по первой линии, второй - по второй, и т. д., а тринадцатый байт - снова по первой. Теоретически шина с 32 линиями способна выдать пропускную способность 20 Гбит/с, от которых отнимаем 20% - 16 Гбит/c, или же по 8 Гбит/с в каждую сторону. Более высокий уровень стека PCI Express отвечает за корректность передачи данных.
Получив от самого верхнего уровня иерархии, Transaction, для передачи пакет данных, алгоритм Data Link присоединяет к последнему номер последовательности и его контрольную сумму. Кроме того, Data Link отвечает и за информирование остальных уровней стека о состоянии канала связи. Третья важная функция Data Link - управление энергопотреблением. Наиболее интеллектуальный уровень PCI Express - Transaction Layer, который задействует четыре различных адресных пространства. Это память (адрес может быть как 32-, так 64-разрядным), сообщения, конфигурация и ввод/вывод. Интересно организовано управление функциями питания PCI Express. Конечно, новый стандарт базируется на основных принципах управления питанием своего предшественника PCI и отвечает требованиям ACPI 2.0 и PCI Bus Power Management Interface Specification 1.1. Для каждого соединения управление питанием выполняется индивидуально, а регламент предусматривает привычные четыре состояния - L3, L2, L1 и L0s. Состояние L3 соответствует режиму «выключено», L2 - отключение основного питания и частотного генератора, L1 - формальный режим совместимости с PCI, при котором уровни питания и частоты находятся в номинальном режиме, но степень готовности ниже, чем в полностью «заряженном» режиме L0s. В последнем для восстановления состояния канала связи не требуется выполнять повторную инициализацию соединения, достаточно лишь «взбодрить» линию быстрой последовательностью тренировки канала. Кроме соответствия традиционным требованиям энергосбережения, стандарт PCI Express обладает и эксклюзивными механизмами управления питания - это ASPM, Active State Power Management. ASPM обладает завидной автономностью и способен переводить устройство в оптимальный режим работы без инструкций свыше (со стороны ПО). Это не означает, что устройство, давно не подававшее признаков активности, будет полностью отключено, но переведено в режим пониженного потребления L0s - наверняка. Стандарт PCI Express считает устройство неактивным, если за время, равное 7 мкс, с ним не было никакого обмена данными.Как только возникает потребность в обмене, устройство возвращается в рабочее состояние. Напомню, у различных устройств может быть абсолютно разное время «засыпания» и «пробуждения», поэтому эти параметры сообщаются Active State Power Management на этапе конфигурирования.
Шина PCI Express: утопия или общая стандартизация?
Евгений Патий
"Экспресс-электроника", #01-02/2005
Развитие компьютерной индустрии можно изобразить в виде кривой, чем-то напоминающей электрокардиограмму: более-менее стабильные периоды сменяются экстремумами. При этом данное утверждение можно отнести как к уровню продаж, так и к технологическим достижениям. И хотя в последнем случае все не так однозначно, ведь очередному пику предшествует кропотливая исследовательская работа, тем не менее, взаимосвязь рыночных скачков и провалов с технологическими зачастую носит прямо пропорциональный характер.
Аналогична и ситуация с системными шинами для персональных компьютеров, построенных на базе архитектуры x86. Прежде чем приступить к предметному разговору, стоит провести небольшой исторический экскурс, чтобы выделить логическую необходимость новых технологических решений.
Воплощение
Аппаратная реализация слотов PCI Express чем-то напоминает матрешку. Имеются четыре разновидности контактных наборов на 1, 4, 8 и 16 линий соответственно. Периферийные карты с меньшим количеством контактов можно устанавливать в слоты с большим количеством контактов, при этом будет задействовано именно столько линий, сколько разведено на карте.
Если в 16-канальный слот установить 16-канальную PCI Express-видеокарту, это будет оправданное решение, пропускной способности в данном случае не бывает много. Но если в такой же слот установить, скажем, модем 56K, не заполняющий и один канал шины, - это уже вопиющая расточительность.
Периферийные карты опционально могут поддерживать горячую замену, что может быть полезно, например, в случае серверного применения. Для питания устройств имеется три группы контактов: +12 В, +3,3 В (основное питание), +3,3 В (вспомогательное питание).
Pentium 4: в ожидании FSB 1 ГГц!
Александр Зубанов, «Экспресс-Электроника», #12/2004
Недавно компания Intel анонсировала имиджевый процессор Pentium 4 Extreme Edition с частотой 3,46 ГГц. Новинка замечательна не только своей повышенной частотой и некоторыми технологическими особенностями, но и тем, что приоткрывает завесу тайны, частично реализуя те функции, которые будут представлены в полной мере новым поколением платформы Intel Pentium 4.
Сегодня нередко можно услышать заявления о росте продаж AMD и спаде активности Intel, однако аналитические агентства утверждают, что такую информацию нельзя воспринимать всерьез. Да, существуют отчеты, свидетельствующие, что продажи компьютеров на базе процессоров AMD действительно достигают, а то и перекрывают продажи систем на платформе Intel. Что ж, это действительно тенденция, но актуальна она только для рынка США. Что касается остальных стран мира, позиции производителей остаются неизменными.
По данным аналитической компании Mercury Research, во II квартале текущего года среди процессоров для настольных компьютеров наиболее активно продавались бюджетные решения. Вероятно, именно вследствие этой тенденции в последнее время рыночная доля Intel незначительно сократилась, в то время как AMD смогла добиться увеличения объемов поставок.
В начале текущего года доля Intel на рынке процессоров, учитывая все сегменты, сократилась на 0,8%: с 83,5% в I квартале до 82,7% — во II . На этом фоне компания AMD смогла добиться 0,5%-ного роста, увеличив свою часть мирового рынка с 15% до 15,5%. Оставшиеся 1,8% рынка делят между собой VIA Technologies и Transmeta.
Таким образом, изменения, происходящие на рынке, действительно незначительны, к тому же многие аналитики склоняются к мнению, что позиции двух ведущих игроков уже в ближайшее время могут вернуться на прежний уровень.
В целом ситуация на мировом рынке не изменилась. Однако это не значит, что продуктовые линейки компаний-конкурентов остались неизменными. Более того, не так давно главный исполнительный директор компании Dell Кевин Роллинс официально подтвердил возможность перевода его компанией некоторых моделей серверов на процессоры AMD.
Следует учесть, что сегодня Dell является самым крупным поставщиком компьютерной техники, и до последнего времени использовала только процессоры Intel.
Что ж, мы можем только гадать, а как все сложится на самом деле, покажет время. Сегодня мы предлагаем оценить соотношение производительности топовых процессоров обоих производителей и разобраться, каковы их перспективы.
Процессор Pentium 4 EE
Процессоры серии Extreme Edition всегда отличались какой-либо особенностью. И если предыдущий представитель данной линейки выделялся среди «неэкстремальных» моделей наличием кэша третьего уровня объемом 2 Мбайт, то теперь топовый процессор обзавелся и более быстрой шиной. Этот нюанс станет визитной карточкой Pentium 4 Extreme Edition, причем единственной, если не считать того, что новый процессор рассчитан на разъем LGA775, а значит, сможет работать только на новых платах, тестирование которых мы проводили в прошлом номере нашего журнала. Напомню, что новая платформа подразумевает использование памяти DDR2, которая в ряде случаев несколько уступает в производительности памяти DDR400. Также потребителю, выбравшему новый процессор, видимо, придется поискать видеокарту, работающую на PCI Express x16, хотя, эта проблема в последнее время перестает быть острой.
Как уже говорилось, изюминка нового процессора именно в большей скорости шины Quad Pumped Bus. Теперь ее тактовая частота составляет 1066 МГц против старых 800 МГц. При этом нельзя утверждать, что шина 800 МГц уже устарела, потому что согласно планам компании Intel, новые процессоры Intel Pentium 4 серий 500 и 600 будут работать все на той же шине 800 МГц, а более скоростная шина в ближайшее время станет прерогативой «экстремальной» линейки.
При производстве Pentium 4 Extreme Edition 3,46 ГГц используется техпроцесс 0,13 мк. Значит, в его основе лежит «старое» ядро Gallatin, следовательно, отсутствует и поддержка технологий Intel Enhanced SpeedStep и 64-битных расширений. Таким образом, из нововведений — лишь обновление шины и смена платформы (LGA 775), которые, тем не менее, являются важным шагом в развитии Pentium 4 EE .
А ведь еще полгода назад многие полагали, что шина 800 МГц – конец в развитии этой линейки.
Платформа
Как известно, базовые модификации чипсета i925 не поддерживают шину 1066 МГц. Поэтому вместе с Pentium 4 Extreme Edition 3,46 ГГц компания Intel выпустила новый набор микросхем – i925 X E Express, который разрабатывался специально под новый процессор, ведь единственным его отличием от i925X Express является поддержка шины 1066 МГц.
С точки зрения архитектуры новые чипсеты серии i925 аналогичны «старым», поэтому производителям не придется менять дизайн плат. К тому же увеличение частоты поддерживаемой шины должно вызвать интерес у любителей разгона, так что тайваньские производители не упустят подобную возможность для инициирования новой рекламной кампании. Ведь стоимость нового чипсета вряд ли будет значительно выше, чем у i925X, а преимущество новичка очевидно.
Выигрыш — теория
Так что же может принести увеличение скорости шины? Почему это может стать преимуществом новой линейки топовых процессоров Intel? Если вспомнить шумиху вокруг Willamette , который обладал не слишком широкой шиной и маленьким кэшем, становится понятно, почему Intel после увеличения кэша на всех моделях процессоров снова занимается ускорением шины. Надо сказать, частота шины действительно принципиальна для процессоров с длинным конвейером и этого нововведения следовало ожидать.
Во-первых, повышение тактовой частоты шины сказывается на всех коммуникациях, в которых участвует процессор. В частности это касается работы с памятью. Действительно, учитывая существующие ограничения производительности для доступа к памяти DDR2 533 МГц, большая скорость шины может улучшить производительность магистрали процессор-память и обеспечить синхронный режим ее функционирования (удвоенная частота 533 МГц равняется 1066 МГц).
Следующее преимущество состоит в общем росте производительности процессора за счет увеличения результирующей тактовой частоты. Однако для данной модели чистый рост составил лишь 60 МГц, что составляет 1,7% частоты процессора.
Не слишком впечатляющий показатель, однако рост частоты системной шины вкупе с процессорной неоднократно показывал большую эффективность, чем увеличение частоты одного лишь процессора.
Одним словом, тенденция развития процессоров Intel Pentium 4 EE вполне оправдана, просто компания проводит плановое наращивание частоты шины. Ну а к чему это приведет, покажут тесты.
Синтетические тесты
После теоретических измышлений, пожалуй, будет логичным тестирование новой процессорной шины (без учета других факторов, которые могут сказаться на быстродействии системы). Следует отметить, что в большей степени нас интересует производительность магистрали процессор-память. Ведь именно при переходе с DDR400 на DDR2 533 МГц обнаружилось некоторое снижение производительности.
Мы рассмотрели три системы с частотой процессора 3,2 ГГц, полученной благодаря изменению коэффициентов умножения частоты шины. В результате, соревновались чипсет i925X с шиной 800 МГц, i925X с шиной 1066 МГц, а также i875P с шиной 800 МГц. Следует понимать, что мы сознательно не привлекаем к тестированию процессор AMD, поскольку единственное его назначение – оценить новые возможности обращения к памяти, которые появляются у процессов Intel при увеличении скорости шины до 1066 МГц
ScienceMark 2.0
На диаграмме можно видеть, что снижение пропускной способности памяти при переходе на DDR2 действительно произошло, однако при повышении частоты системной шины пропускная способность становится даже выше, чем у DDR400 – 4173 Мбайт/с против 3687 Мбайт/с (рост 13%) при шине 800 МГц и памяти DDR2 и 4003 Мбайт/с (рост 4%) на DDR400. Что касается задержек, они, конечно, остаются выше, чем у DDR 400.
При этом следует отметить, что переход на новую шину действительно выигрышное решение при обращении к памяти; и когда на рынке появится память DDR2 c более агрессивными таймингами (например, 3-3-3-8), которые уже существуют в качестве инженерных образцов, процессоры линейки Extreme Edition с шиной 1066 МГц станут привлекательными.
Но, как известно, синтетические тесты редко отражают реальное положение вещей, поэтому мы переходим к практике.
Замечания перед тестированием
Поскольку мы говорим о флагманском процессоре, поэтому, чтобы понять, насколько эффективным оказалось повышение FSB, имеет смысл сравнивать его именно с предыдущим топовым процессором Intel и аналогичным по позиционированию процессором от AMD , а именно, Athlon 64 FX-55, а также с представителем «неэкстремальных» процессоров Intel.
Конфигурация тестовых платформ указана в таблице.
|
Процессор |
Материнская плата |
Видеокарта |
Память |
Жесткий диск |
|
Athlon 64 FX-55 |
ECS K8T800-A (S939 VIA K8T800 Pro) |
Asus AX800 XT/TVD |
512 DDR400 OCZ PC3200 SDRAM (2-2-2-10) |
WD 400 BB |
|
Pentium 4 560 (LGA775) |
ABIT AA8 (LGA775 i925X Express) |
Asus Extreme AX800XT/2DT |
512 DDR2-533 PMI4200 Gold SDRAM (4-4-4-11) |
|
|
Pentium 4 EE 3,4 ГГц (LGA775) |
||||
|
Pentium 4 EE 3,46 ГГц (LGA775) |
Intel Desktop Board D925EECV2 |
Выигрыш — практика
Итак, начнем с простого, а именно – с производительности в офисных приложениях. Вообще говоря, сомнительно, что столь дорогой процессор, как Pentium 4 EE, будут покупать для решения офисных задач, однако следует понимать, что подобная активность свойственна абсолютно любому пользователю.
SysMark 2004
Как вы можете видеть, разница в производительности минимальна, и, работая за реальным компьютером, ощутить отличия между тестируемыми платформами будет невозможно. Таким образом, анализируя этот тест, можно говорить только о небольших архитектурных преимуществах Athlon 64, любовь которого к целочисленным операциям давно известна. Однако любопытен и тот факт, что новый «неэкстремальный» процессор Intel показывает лучший результат, чем линейка Extreme Edition. Однако стоит понимать, что в этом классе задач частота оказывает влияющее действие на уровень производительности системы в целом.
Примерно такие же тенденции демонстрируют и другие офисные тестовые пакеты, результаты которых в целях экономии печатной площади мы решили не приводить.
Так что выводы достаточно прозрачны – новый процессор в совокупности с новой платформой не облегчит выполнения повседневных офисных задач.
Как уже говорилось, офисные приложения не являются приоритетной задачей для нового процессора, поэтому перейдем к графическим тестовым пакетам. Поскольку мы оцениваем не только процессор, но и платформу, с которой он должен работать, целесообразно будет привести как оценку вложения процессора, так и общий показатель графических возможностей системы.
Тестируемые видеокарты основаны на чипе Radeon X800, но используют разные шины (AGP и PCI Express). Поэтому разница в производительности платформ AMD и Intel будет обусловлена еще и методической ошибкой измерений, привнесенной отсутствием в чипсете VIA K8T800 Pro реализации шины PCI Express.
3DMark 2003
Результат комплексных графических тестов предсказуем. Процессор AMD совместно с шиной AGP показывает наилучший результат. Кстати, чистая производительность процессора в графическом приложении у Athlon 64 оказывается значительно выше, чем у процессоров Intel.
В «фамильном» соревновании семейство Pentium 4 поделило позиции просто «по-братски»: результирующие показатели графической производительности практически равны, а чистая производительность процессора линейки EE оказывается все же немного выше, чем у Pentium 560 (скорее всего, из-за увеличенной FSB и присутствия кэша третьего уровня).
Игры
Ситуация, сложившаяся в тестировании на реальных игровых приложениях, действительно говорит в пользу процессоров Pentium 4 EE, при этом новый процессор оказывается лучше старого Pentium 4 EE 3,4 ГГц, правда совсем ненамного. Однако сама платформа в сочетании с шиной PCI Express х16 серьезно проигрывает решению AMD с шиной AGP 8x.
Но, безусловно, графикой и офисными приложениями сфера применения процессоров не ограничивается, и, естественно, интересно было бы узнать, как новые модели работают с потоковыми данными, в частности кодированием и архивированием. Кроме того, эти задачи как никакие другие зависят от производительности FSB, а потому на них стоит сконцентрировать особое внимание.
Кодирование видео
На диаграмме приведена скорость кодирования двумя кодеками в кадрах в секунду. Что же мы видим? Pentium 4 EE проигрывает в обоих тестах. Причем если при работе с кодеком DivX он работает немного быстрее процессора конкурентов, хотя и отстает от «неэкстремального» Pentium 4 560, то с XviD дела обстоят намного хуже. Линейка Pentium 4 EE проигрывает как Athlon 64 FX-55, так и лучшему в этом тесте Pentium 4 560. Признаться, причина неудач Pentium 4 EE не в недостатках процессора, а в том, что он работает на старом ядре. В этом плане процессорам не помогает даже новая высокая частоты системной шины. Наверняка в следующих версиях Pentium 4 Extreme Edition ситуация должна измениться.
Сжатие данных WinRar
Что касается сжатия данных, процессор Athlon 64 FX-55 уходит далеко вперед, и Pentium 4 560 также обгоняет процессоры серии Extreme Edition: у «экстремальных» процессоров возникают серьезные задержки при общении с памятью DDR2 (вспомним, что у этого типа памяти высокая латентность). По той же причине встроенный контроллер памяти Athlon 64 позволяет ему серьезно оторваться от процессоров Intel. Так что любителям Pentium 4 придется ждать появления памяти DDR2, работающей с меньшими задержками.
Не стоит забывать, что мы говорим о дорогом и высокопроизводительном процессоре, и одной из сфер его применения вполне может стать профессиональная деятельность, например, 3D-рендеринг.
Профессиональные приложения
В вопросах рендеринга процессоры Pentium 4 EE идут «голова в голову», однако чип AMD почти не отстает. Дольше всего задача выполнялась на Pentium 4 560. Пожалуй, в этом вопросе «экстремальные» процессоры оказываются действительно производительнее. Однако от увеличения частоты шины роста скорости работы как раз не наблюдается. В этом случае большее воздействие на итог оказывает результирующая частота.
В случае с Photoshop, для которого предпочтительнее короткий конвейер, на первом месте оказывается Athlon 64 FX-55. В то же время среди процессоров Intel максимальную эффективность демонстрирует Pentium 4 560 на ядре Prescott.
Итоги
О чем же свидетельствуют тесты? К сожалению, приходится признать, что увеличение частоты шины не приводит к ошеломляющим результатам. Да, процессор стал чуть быстрее своего собрата, обладающего меньшей на 60 МГц частотой, однако одно только расширение шины не приводит к прямому выигрышу. Судя по всему, процессор Pentium 4 EE 3,46 ГГц является моделью, способной на дальнейший прирост частоты, а также стабильную работу на новой шине с использованием новой памяти. Покупать же этот процессор стоит только из соображений коллекционирования, потому как платить $1 тыс. за процессор, который не дает особого преимущества ни в одном из тестов, вряд ли имеет смысл для тех, кто стремится реально повысить производительность своего компьютера.
Безусловно, линейка станет привлекательной для тех, кто жаждет экстремальной производительности, но только тогда, когда будет решены проблемы с задержками DDR2, и процессоры Extreme Edition перейдут на новую технологию (0,09 мк). Действительно, взаимодействие памяти DDR2 с меньшими таймингами и более широкой шины выглядит весьма многообещающе. Однако сегодня однозначное лидерство принадлежит Athlon 64 FX-55, рыночная стоимость которого составляет порядка $850.
Гонка частот: смена декораций
Эрнст Долгий
«Экспресс-Электроника», #1/2004
Частоты, чипсеты, шины, мосты, наборы инструкций, напряжения питаний, степпинги: Сегодня в этих терминах хорошо разбираются не только IT-специалисты. Нас долго приучали к тому, чтобы тонко улавливать разницу между конкурентными продуктами, ведь не делай мы этого, под вопросом оказались бы такие характеристики наших электронных помощников, как стабильность, производительность, совместимость, простота настройки и конфигурирования. Удивительно, но факт: частоты верхних моделей ведущих производителей микропроцессоров в уходящем году увеличились лишь на 200 МГц. Но означает ли это, что гонка частот остановилась?
На самом деле среднестатистическому пользователю, тому самому, который идет покупать ПК в ближайший компьютерный магазин, знание всех этих нюансов и не нужно. Ведь качество и возможности современных платформ за последнее время выровнялись. Поэтому между использованием того или иного набора логики, да и процессора существенной разницы нет. Вопрос лишь в цене. Но, несмотря на это, игроков на рынке чипсетов и процессоров за последние годы меньше не стало, а их продукты не перестали быть интересными. Поэтому мы продолжаем рассказывать, тестировать и сравнивать их между собой. С одной лишь оговоркой. Мы делаем это для профессионалов.
Государевы черевички
Если главная особенность последнего времени, касающаяся Intel, - низкий прирост частоты, то для AMD это долгожданный выход линейки процессоров нового поколения - Athlon 64. Впрочем, несмотря на основные события, происходящие вокруг этой платформы, "старая" платформа Socket A и не думает кануть в Лету. В этом году старейшая из архитектур на рынке х86-систем получила инъекцию свежей крови: частота шины процессора возросла до 400 (200) МГц, появились процессоры Athlon XP на ядре Barton, обладающие 512 кбайт кэша второго уровня. Кроме того, в обновленном плане развития по выпуску процессоров AMD запланирована поддержка этой платформы вплоть до 2005 года.
Интересно, что "странных" изменений в модельном ряду Athlon XP было не меньше, чем у Intel. Пожалуй, самый парадоксальный факт, что AMD удалось выпустить не менее производительный (по ее мнению) процессор, но с меньшей тактовой частотой. Речь идет об Athlon XP с частотой 2,1 ГГц, которые в рейтингах "XP" оказались вполне равноценными решениями (3000+). Конечно же, возразят поклонники продукции AMD, первый использует FSB 333 МГц, тогда как второй - 400 МГц, но вот только проведенные нами тесты ("Экспресс-Электроника" № 4'2003) подтвердили факт "равной производительности" как-то очень неубедительно.
Впрочем, на все эти "частотные махинации" можно закрыть глаза, если учесть, что AMD все-таки выпустила долгожданный чип на новой архитектуре. Пусть сначала лишь для серверного рынка, пусть даже без поддержки шины AGP. А позже появились и версии для настольных систем, однако опять же в ограниченных количествах и лишь для крупнейших партнеров.
Кратко напомним характеристики Athlon 64: разъем Socket 754; L2-кэш объемом 1 Mбайт; технология AMD64; интегрированный в процессор контроллер памяти; интегрированный контроллер Hyper-Transport; поддержка всех современных наборов инструкций, существующих на х86-процессорах: MMX, 3DNow!, SSE, SSE2. Стартовой частотой для данной архитектуры является 2,0 ГГц, соответствующая модель получила наименование Athlon 64 3200+.
Отвечает ли заявленный рейтинг реальной производительности CPU от главного конкурента - мы увидим в тестировании. Стоимость Athlon 64 3200+ составляет $417 (в партиях по 1000 штук). Что касается планов AMD, есть информация о выпуске микропроцессоров на следующие два года, компания предполагает наступление на два наименее освоенных ею рынка - чипов для серверов и портативных ПК. В I квартале 2004 года AMD выпустит под маркой Mobile Athlon 64 первый Athlon 64 для ноутбуков. Во втором полугодии на смену ему придет чип Odessa, изготовляемый с уровнем детализации 90 нм, а серию Athlon XP-M продолжит 130-нанометровый Dublin. В 2005 году за Odessa последует Oakville (первое полугодие), а за Dublin - 90-нанометровый Trinidad (второе полугодие). Серверные планы AMD предусматривают выход во втором полугодии 2004 году трех новых Opteron: Athens, Troy и Venus, предназначенных, соответственно, для систем с 4-8, 2 и 1 процессором. Во второй половине 2005 года на смену каждому из этих чипов придут Egypt, Italy и Denmark. Все серверные процессоры AMD будет выпускать как в стандартном, так и в низковольтном варианте. Настольные ПК в первой половине следующего года получат удешевленную версию Athlon 64 с уменьшенными объемом кэша и размером подложки (Newcastle) - для массовой категории настольных ПК. Во второй половине 2004-го выйдут San Diego - развитие серии Athlon 64 FX (с 1 Мбайт кэша L2), Winchester - версия Athlon 64 (512 Кбайт кэша L2) для десктопов среднего уровня и Paris - низкобюджетный 32-битовый процессор на базе Athlon XP, единственный в этом трио, который все еще предполагается изготовлять с уровнем детализации 130 нм. Коллекция настольных чипов 2005 года будет состоять из высокопроизводительного Toledo и недорогого Palermo. Ни один из этих процессоров не будет основан на архитектуре K9 - ее дебют, по информации AMD, состоится, в лучшем случае, в самом конце 2005 года, а основным нововведением станет двуядерная архитектура.
Тестирование и комментарии к нему
Как известно, важнейшая составляющая нового поколения процессоров AMD - интегрированный контроллер памяти. С исследования этой изюминки мы и начнем тестирование, для чего применим тестовый пакет Cashe Burst 32, который, являясь синтетическим приложением, позволяет отследить целый ряд параметров. В частности, измерить скорость чтения и записи в память, а также кэш разных уровней, при этом исследователь может задать характер тестового материала, при помощи которого будет производиться тестирование. Данные могут быть представлены как в виде стандартных х86-команд, так и "разбавленных" SIMD-инструкциями (MMX, SSE).
Уже первый тест контроллеров памяти процессоров показал весьма интересные результаты. Как видно, использование SIMD-инструкций вовсе не пустой звук, и практически все контроллеры памяти показали отчетливо заметный прирост быстродействия, как при записи, так и при чтении информации, представленной в оптимизированном виде. Впрочем, создателя набора команд видно издали - практически со всеми видами оптимизированного тестового материала контроллеры памяти процессоров Intel работают быстрее (как при чтении, так и при записи). Правда, нельзя не отметить и тот факт, что и с неоптимизированными данными контроллеры Intel ведут себя аналогично. Все-таки позиции Intel в области создания наборов логики наиболее сильны.
С другой стороны, это утверждение можно легко опровергнуть, если учесть, что в процессорах нового поколения AMD используется одноканальный контроллер памяти, тогда как в чипсете i875 он двухканальный. Если обратиться к результатам теста Cashe Burst 32 по скорости записи в память процессора AMD Athlon 64 FX-51 2,2 ГГц, который, как известно, в отличие от базовой версии обладает двухканальным контроллером памяти, можно заметить, что он демонстрирует практически двойной прирост быстродействия, вне зависимости от тестового материала. Данное достижение стоит признать весьма показательным, ведь ранее при переходе от одноканальной топологии контроллера памяти к двухканальной подобного явления не наблюдалось.
Таким образом, если по скорости чтения контроллеры памяти компании Intel являются лидерами, то по показателю скорости записи все не столь однозначно. Хотя не будем забывать о весьма высокой стоимости процессора AMD Athlon 64 FX-51, а также о синтетическом характере данного тестового приложения. Обратимся к результатам теста Cashe Burst 32, характеризующих скорость работы кэшей разных уровней. Как показано на второй диаграмме (тестовым материалом послужили инструкции х86), скорости работы кешей вполне сопоставимы, а потому их производительность в задачах, активно использующих память, определит в первую очередь скорость работы контроллера памяти. Правда, уже на этом этапе тестирования можно предположить, что процессор Intel Pentium 4 Extreme Edition, в виду наличия весьма объемного и достаточно производительно кэша третьего уровня, в тех задачах, где объем оперируемых им данных не превысит суммарный объем его кэш-памяти разных уровней, окажется в заведомо более удачном положении. С другой стороны, при использовании неоптимизированного тестового материала кэш третьего уровня процессора Intel Pentium 4 Extreme Edition оказался самым медленным, даже несмотря на 64-битную организацию. А теперь перейдем к реальным приложениям. Как видно, задачи архивирования (rar) проще даются AMD Athlon 64 FX-51, тогда как в области задач с менее сложным алгоритмом (zip) победителем оказывается Intel Pentium 4 Extreme Edition. Это, кстати, достаточно просто объясняется, особенно если учесть длину конвейеров названных процессоров. Как известно, у AMD Athlon 64 она короче, что позволяет ему быстрее восстанавливать свою "вычислительную активность" после неправильного предсказания ветвлений, в то время как более длинный конвейер Pentium 4 дольше остается "неготовым" начать вычислительную процедуру заново. Таким образом, там, где требуется "грубая сила", эффективность линейки Pentium 4 оказывается выше, тогда как в области более сложных задач, даже несмотря на свою довольно низкую частоту, выигрывают процессоры AMD.
Но здесь следует сделать оговорку: процессор AMD Athlon XP 3200+ отстал как от конкурентов, так и от собратьев в лице 64-битных чипов. Для того чтобы объяснить этот парадокс, достаточно обратиться к диаграммам тестового пакета Cashe Burst 32, в которых AMD Athlon XP 3200+ продемонстрировал весьма посредственные результаты работы с памятью. При архивировании данных последняя является наиболее активно нагружаемым элементом. Переходя к рассмотрению результатов тестов по кодированию медиаданных, обратим внимание на параллельность линий, которые можно было бы построить по вершинам столбцов диаграммы. Причем в этом тесте AMD Athlon 64 FX-51 оказался безоговорочным лидером, хотя опережение ближайшего соперника - Intel Pentium 4 Extreme Edition - в общем-то, не большое, особенно при кодировании WAV-файла в МР3 при помощи кодека Lame. Интересно, что в сегменте "неэкстремальных" процессоров ситуация противоположная. Здесь результат лучше у Intel Pentium 4. Таким образом, превосходный результат AMD Athlon 64 FX-51 объясняется использованием в нем двухканального контроллера, который показал себя с наилучшей стороны еще в процессе прохождения синтетических тестов. В игровых приложениях ситуация повторяет ту картину, которую мы могли видеть при кодировании медиаданных. И хотя по очкам вновь выигрывает AMD Athlon 64 FX-51, его превосходство над Intel Pentium 4 Extreme Edition 3,2 ГГц минимально, и в этом наборе приложений наблюдается паритет. С другой стороны, Athlon 64 3200+ более производителен, как в реальном игровом приложении, так и в синтетическом. Впрочем, нелюбовь Intel Pentium 4 к коду Unreal Tournament 2003 известна издавна. Что касается сферы реальных приложений, здесь картина не столь однозначна, как в игровых. Так, при рендеринге реальной сцены в 3ds max, первое место делят между собой Intel Pentium 4 Extreme Edition и Intel Pentium 4 3,2 ГГц, тогда как при прорисовке сцен SPECviewperf 7.1 (drv-09 и других) победителем оказывается AMD Athlon 64 FX-51, и его преобладание над конкурентами ощутимо.
Тестовая платформа
1. Процессоры: Intel Pentium 4 3,2 ГГц (800 МГц FSB); Intel Pentium 4 Extreme Edition 3,2 ГГц (800 МГц FSB); AMD Athlon 64 FX-51 2,2 ГГц; AMD Athlon 64 3200+ (2,0 ГГц); AMD Athlon XP 3200+ (2,2 ГГц, 400 МГц FSB). 2. Материнские платы: ASUS P4C800 (i875P); ASUS SK8N (NVIDIA nForce3 Pro 150); ASUS A7N8X-E Deluxe Wireless Edition (NVIDIA nForce2 Ultra 400). 3. Память: DDR400 SDRAM, 1024 Мбайт, Transcend (2 x 512 Мбайт, 2-2-2-5); Registered DDR400 SDRAM, 1024 Мбайт, Transcend (2 x 512 Мбайт, 2,5-3-3-5). 4. Видеокарта NVIDIA GeForce FX 5900.
5. Жесткий диск Western Digital WD400BB.
6. Операционная система Microsoft Windows XP Professional SP1, DirectX 9.0b.
Тиха украинская ночь...
Ситуация на рынке микропроцессоров, несмотря на реванш компании AMD (выпуск процессоров Athlon 64), складывается не в ее пользу. Об этом свидетельствует исследование IDC, согласно которому в начале III квартала 17,2% рынка х86-систем принадлежали компании AMD (на 1,1% хуже, чем в I квартале), 81,6% - Intel (на 1,2% лучше, чем в I квартале). Оставшуюся долю рынка (1,2%) разделили между собой компании Transmeta и VIA. Поэтому анализ рынка и описание наиболее интересных продуктов мы начнем с компании Intel.
Несмотря на то что тактовая частота флагманского процессора компании выросла в 2003 году лишь на 200 МГц (с 3,06 ГГц до 3,2 ГГц), основная линейка чипов Intel претерпела немало изменений. Во-первых, частота FSB выросла до 800 МГц (реальные 200 МГц), а во-вторых, абсолютно все модели настольной линейки Pentium 4 в этом году обзавелись поддержкой технологии Hyper-Threading. Таким образом, даже близкий к бюджетному уровню Intel Pentium 4 2,4 (В) ГГц обладает сегодня поддержкой этой технологии.
"Что же, в таком случае, замедлило темпы роста частот?" - спросит читатель. Однозначно ответить на этот вопрос сложно. Так, одной из причин называют затянувшийся переход на новый технологический процесс (0,09 нм), другой - отсутствие должного уровня конкуренции на рынке. На наш взгляд, и то и другое стало причинами замедления роста частот. К примеру, из-за отсутствия былого уровня конкуренции со стороны AMD, компания Intel получила возможность усовершенствовать новый техпроцесс (0,09 нм) для получения более высокого процента выхода годных микросхем. При этом утверждают, что нового импульса, инициирующего гонку частот с новой силой, со стороны AMD, скорее всего, не последует. AMD планирует перейти на новый техпроцесс лишь во II квартале 2004 года. А при нынешнем технологическом процессе высоких частот обеим линейкам процессоров AMD не достичь.
Впрочем, изменения в модельных рядах процессоров естественны, ведь современный пользователь так привык к частой смене декораций на рынке процессоров, что оставить его наедине со старым продуктом было бы неправильно.
С другой стороны, " гнать лошадей" при отсутствии реальной конкуренции также ошибочно. Во-первых, продукты конкурента уже не так сильны, как это было ранее, а во-вторых, имея хороший "неприкосновенный запас", спать всегда спокойней. Именно поэтому изменения в модельном ряду Intel в 2003 году носили чисто перманентный характер. При этом маркетинговая цель была достигнута - новые модели процессоров выходили с нужной периодичностью, а уровень производительности рос. Однако если главный продукт топчется на месте, вторичный выручает ситуацию. Именно поэтому рост частоты в 2003 году демонстрировал в основном Celeron. Сегодня максимальная частота этого процессора составляет 2,8 ГГц. При этом частота системной шины у него осталась прежней и составляет всего 400 МГц, а кэш второго уровня имеет объем 128 кбайт. Стоит ли говорить, что линейка Celeron стала еще одной жертвой эффекта "бутылочного горлышка", суть которого в нашем случае состоит в том, что процессор-то данные способен обрабатывать, а вот системная шина с нужной скоростью транспортировать их в обоих направлениях, увы, нет. И Intel эту ситуацию косвенно подтвердила, записав настольный Celeron 2,8 ГГц в число процессоров, применяемых как для настольных, так и для мобильных ПК. Ведь по поводу перегрева не стоит беспокоиться, процессор все равно не сможет работать в полную силу. Спрашивается: зачем такому процессору столь высокая частота? Ответ сколь очевиден, столь и прост - он диктуется чисто маркетинговыми соображениями. Рынок требует смены декораций, а то, что Celeron 2,8 ГГц вряд ли опередит по производительности в основной массе задач даже Pentium 4 с частотой 2,4 ГГц, похоже, мало кого интересует. А те пользователи, кто ставит во главу угла производительность, покупают процессоры high-end. На традиционной осенней сессии IDF президент компании Пол Отеллини (Paul Otellini) заявил, что к IV кварталу следующего года частоту процессоров, базирующихся на ядре Prescott, планируется увеличить до 4 ГГц.
Этим он подтвердил, что замедление роста частоты - проблема технологическая. Он также отметил, что во II квартале будет выпущен Celeron с уровнем детализации 90 нм, с частотой 2,8 и 3,06 ГГц. К этому времени на долю Prescott (с максимальной частотой 3,6 ГГц) будет приходиться 60% от общего объема настольных процессоров Intel. Производство 0,13-микронных Pentium 4 Northwood будет полностью прекращено в III квартале 2004 года. Кроме этого, Пол Отеллини обрисовал в деталях планы по выпуску чипов с несколькими процессорными ядрами на общей подложке. По его словам, многоядерные процессоры для настольных ПК и серверов (Tanglewood) появятся в 2005 году. Поддержка технологии WLAN в чипсетах Intel будет реализована с выходом в 2004 году набора базовой логики Grantsdale. Подключив модем к ПК на базе Grantsdale, можно превратить последний в средство беспроводного доступа к Интернету в пределах квартиры или офиса. Наряду с другим будущим чипсетом, Sonoma, Grantsdale обеспечит поддержку памяти DDR-II, Serial ATA и стандарта Azalia (24-битовый звук 7.1). В Sonoma предусмотрен коннектор для датчика освещенности, что позволит автоматически устанавливать оптимальную яркость ЖК-дисплея в целях экономии энергии. А стратегия продвижения под общим брендом процессора и сопряженных компонентов, успешно зарекомендовавшая себя еще при Centrino, будет перенесена и на другие платформы, в том числе на защищенный файл-сервер (LaGrande) и на технологию запуска нескольких виртуальных ОС на одной системе (Vanderpool).
То ли шут, то ли король
При подведении итогов и анализе тех изменений, которые произошли в модельных рядах производителей, в стороне осталось появление двух весьма необычных процессоров, ориентированных на применение в ультрапроизводительных настольных системах класса Hi-End. Речь идет о процессорах Intel Pentium 4 Extreme Edition и AMD Athlon FX-51. Их характеристики приведены в таблице 1.
Отличий процессора Athlon FX-51 от Athlon 64 3200+ немного, но они достаточно значительные. Первое отличие касается конструктива - равно как и серверные чипы линейки AMD Opteron, Athlon 64 FX-51 предназначен для установки в разъем Socket 940. Кроме того, его реальная частота составляет 2,2 ГГц, а это уже не просто смена декораций. Таким образом, вкупе с первым отличием (фактически подразумевающим использование двухканальной памяти) Athlon 64 FX-51 становится даже теоретически наиболее производительным продуктом компании.
Впрочем, на пути достижения экстремальной производительности может оказаться преграда. Во-первых, все платы под Socket 940 работают только с регистровой DDR-памятью (наличие технологии ECC не обязательно), цена которой значительно выше, чем у стандартной, а производительность несколько занижена. Во-вторых, на сегодня существует лишь один чипсет с поддержкой Socket 940, платы на базе которого выпускаются с поддержкой работы только одного процессора - nForce3 Pro.
"Экстремальный" Pentium 4 по совокупности технических характеристик значительно ближе к стандартной версии Pentium 4. В отличие от Athlon FX-51 он имеет лишь одно отличие от базовой версии - кэш третьего уровня объемом 2 Мбайт. Очевидно, что под названием "Pentium 4 Extreme Edition" Intel предлагает своим пользователям процессоры Xeon с ядром Galatin. Именно оно содержит L3-кэш объемом 2 Мбайт.
Стоит ли говорить, что большого распространения из-за выставленных на эти процессоры цен, новинки не получат, по крайней мере, в ближайшей перспективе. Именно поэтому о перспективах новых решений мы говорить не будем. Ограничимся выяснением их производительности.
Наиболее важный вывод из тестирования
Наиболее важный вывод из тестирования в том, что оба игрока имеют очень качественные и производительные чипы. Причем наиболее мощным процессором для рабочих станций является AMD Athlon 64 FX-51, а в сфере массовых систем первенство принадлежит Intel Pentium 4. Но нужно понимать, что именно этому факту и обязан появлением на свет процессор AMD Athlon 64 FX-51. Будь базовая версия флагманского процессора AMD (Athlon 64 3200+) чуть "порасторопней", необходимость в продвижении этого чипа как сверхпроизводительного была бы излишней. С другой стороны, продвигать на массовый рынок чип с заведомо большей себестоимостью (AMD Athlon 64 FX-51 оказывается более дорогим чипом из-за большей площади кристалла) было бы непредусмотрительно, да и впоследствии совершенствовать и без того неоднократно переносившийся по срокам выхода продукт было нельзя. С этой точки зрения выпуск AMD Athlon 64 FX-51 оказывается правильным шагом, и остается только аплодировать AMD, которой не только удалось выпустить хороший продукт, но и привить пользователю мысль о техническом превосходстве своих процессоров нового поколения. Вот только чипы эти будут устанавливаться далеко не во все компьютеры.
Кремниево-ядерный реактор, Или говорим о проблеме нагрева в микросхемах
Александр Лось, Максим Федоров, "Экспресс-Электроника"
Великий маг и престидижитатор Кристобаль Хозевич Хунта из повести братьев Стругацких "Понедельник начинается в субботу" принципиально занимался решением только тех задач, которые не имели решения, поскольку все остальные он считал недостойными себя. Без сомнения, он с удовольствием занялся бы и решением задачи снижения тепловыделения в современных полупроводниковых микросхемах, ведь эта проблема всегда была одной из наиболее существенных при работе полупроводниковых устройств любой логики и размера, причем с каждым годом она становится все более актуальной. Как же с ней бороться?
О существовании эмпирического закона Гордона Мура (Gordon Moore) сегодня знают, или хотя бы слышали, многие. Далеко не все, правда, знают об условии, которое делает возможным его выполнение. Последнее является открытием Роберта Деннарда (Robert Dennard) из IBM и называется условием масштабирования MOSFET (Metal Oxide Silicon Field Effect Transistor). Суть его состоит в том, что если удерживать постоянное значение напряженности электрического поля при уменьшении размеров MOSFET, то параметры производительности улучшатся. Это значит, если, например, сократить длину затвора в n раз и одновременно во столько же раз понизить рабочее напряжение (значение напряженности при этом не изменится), время задержки логического элемента тоже уменьшится в n раз.

MOSFET-транзистор
Отсюда и жесткая зависимость размеров элементов интегральных микросхем от их производительности. Но, к сожалению, еще и от тепловыделения. Ведь с каждым годом транзисторы становятся все меньше, а значит, электронам приходится передвигаться по все более узким переходам, все более "энергично" сталкиваясь с атомами вещества,, способствуя тем выделению все большего количества теплоты. Кроме того, чем больше транзисторов размещается на единице площади, тем больше мощности они потребляют и, соответственно, тем больше выделяют энергии. Как тут не вспомнить замечание Патрика Гелсингера двухлетней давности (ныне занимающего пост генерального менеджера группы Intel по цифровым корпоративным технологиям), о том, что если продолжать использовать современные методы разработки процессоров, то к 2010 году процессоры будут вырабатывать больше тепла на квадратный миллиметр, чем ядерный реактор.
Именно поэтому снижение тепловыделения современных процессоров наравне с повышением их производительности выходит сегодня на первый план. И создать производительный процессор на нынешний день недостаточно — не менее важной задачей оказывается приведение его работы к качественным энергохарактеристикам. Собственно, масштабы проблемы ясны, самое время перейти к описанию идей по ее искоренению. Ну а начать, пожалуй, стоит со способов, не особо меняющих устои привычного производства полупроводниковых микросхем, а именно с тех, которые модифицируют используемые в производстве материалы. Но для лучшего понимания проблемы — еще немного теории. Итак, если вновь обратиться к условию масштабирования MOSFET, то выяснится, что для минимизации размеров транзисторов помимо их самих необходимо также масштабировать и другие элементы прибора. Уменьшение длины затвора требует более тонких боковых стенок, менее глубоких истоковых и стоковых переходов и, что в данном случае является самым важным, — более тонкого диэлектрика затвора (двуокиси кремния). При технологических нормах 90 нм его толщина достигает 1,2 нм, что составляет всего пять атомных слоев. При дальнейшем уменьшении толщины слоя диэлектрика его изоляционные свойства значительно ухудшаются, и ток утечки, которым можно пренебречь при крупных габаритах элементов транзистора, становится недопустимо большим. Поэтому миниатюризация элементов микроэлектроники превращается в трудоемкую, а при достижении определенных размеров — практически не решаемую задачу. Здесь же нужно отметить, что ток утечки является величиной, определяющей мощность, потребляемую в режиме ожидания или неактивном режиме, то есть активно сказывается на общем уровне энерговыделения микросхемы. Если потребляемая мощность в режиме ожидания в микросхемах, выполненных по 180-нм и 130-нм нормам, пренебрежимо мала по сравнению с общей мощностью, потребляемой в активном режиме, то использование существующих технологий в 65-нм и более "тонких" техпроцессах может привести к росту потребляемой мощности в режиме ожидания до уровня, превосходящего мощность, потребляемую в активном режиме. Вообще, на величину тока утечки влияют три главных фактора: туннельные эффекты, приводящие к миграции электронов между затвором и стоком под потенциальным барьером, ток через изолятор затвора и индуцированный этим же эффектом ток стока.
Наиболее решительно здесь можно влиять лишь на ток утечки, который определяется уровнем напряжения на изоляторе и его сопротивлением. Последнее находится в прямой зависимости электрической емкости пленки диэлектрика затвора от диэлектрической постоянной k материала, из которого он выполнен. Именно поэтому высокое значение k — столь желанный показатель для материалов. Судите сами: если значение диэлектрической постоянной для двуокиси кремния составляет 3,9, то, используя другой материал с более высоким значением этого параметра, той же емкости на единицу площади можно достичь и при более толстой пленке и тем самым снизить ток утечки. Именно в таком направлении сегодня двигаются большинство исследователей. И надо сказать, небезрезультатно, так как существует большое количество пленок со значениями k выше, чем у двуокиси кремния (вплоть до 1400). Однако большая часть из них при соединении с кремнием, к сожалению, теряет термодинамическую устойчивость, а также ряд необходимых для производства транзисторов свойств. Поэтому для изготовления затвора необходимо использовать отличный от поликремния материал. По многим причинам более эффективным оказывается сочетание диэлектрической пленки с высоким значением k и металлического затвора (high-k/metal-gate). Именно такой подход недавно удалось успешно реализовать исследователям из Intel. Применив новый сплав для изготовления затвора, они продемонстрировали высокопроизводительные КМОП-транзисторы со стеками high-k/metal-gate. Последние имеют физическую длину затвора 80 нм и толщину изолятора примерно 1,4 нм. По мнению разработчиков, эта технология позволит осуществить переход на технологические нормы 45 нм.

Структура обычного КМОП-транзистора и транзистора со стеком high-k/metal-gate Что касается других реализаций пленок с высоким показателем k, к примеру, Texas Instruments уже более пяти лет работает с силикатами гафния и, по словам специалистов компании, смогла добиться весьма низких значений тока утечки. Как отмечают, такие изоляторы помогут удержать величину токов утечки в допустимых пределах при уменьшении размеров транзисторов в микросхемах.
В Texas Instruments заявляют, что кремниевый оксинитрид гафния (HfSiON) обеспечивает необходимый уровень тепловой и электрической совместимости со стандартным КМОП-процессом, а также гарантирует приемлемый уровень подвижности носителей заряда (примерно 90% от аналогичного показателя для диоксида кремния) и стабильность порогового напряжения. В принципе, потенциал диэлектриков на основе гафния известен давно, сложность заключалась в подборе оптимального компонентного состава соединений, на решение этой задачи и были направлены усилия Texas Instruments. Но по истине ошеломляющие результаты в экспериментах с силикатом гафния достигнуты компанией NEC. Как утверждается представителями компании NEC, ее сотрудникам удалось достичь тока утечки в 1,4 пА для полевых транзисторов структуры p-n-p и 0,3 пА для транзисторов типа n-p-n. Опять-таки по данным NEC, такая величина тока утечки в 30 раз меньше, чем у когда-либо достигнутых в индустрии, и это позволяет надеяться, что выполненные по новой технологии микросхемы будут работать от источников питания до 10 раз дольше. Новая технология стала основой инициативы NEC Ultimate Low Power, направленной на внедрение энергосберегающих технологий в 65-нм и 45-нм технологические процессы, а в готовые продукты названная технология будет интегрирована уже в 2006 году. Впрочем, на фоне оптимизма относительно перспектив материалов с высоким показателем k нельзя не отметить, что их использование порождает ряд побочных проблем. Например, считается, что это может привести к снижению подвижности носителей заряда и смещению порогового напряжения. На один из возможных механизмов снижения подвижности носителей заряда, вызванного генерацией "мягких" фононов, связанных с электронами в канале проводимости, указал в прошлом году Макс Фишетти (Max Fischetti), сотрудник IBM T.J. Watson Research Center. Он предсказал также значительное снижение тока утечки при использовании его методики, эффективность которой была подтверждена компанией Intel — ее специалистам удалось снизить обнаруженное IBM рассеяние фононов использованием затвора, состоящего из слоя нитрида титана поверх оксида гафния.
Кроме того, частично бороться со снижением подвижности носителей заряда, благодаря которой транзисторы срабатывают значительно медленнее, помогает методика "напряженного кремния" (strained silicon). На этой технологии остановимся подробнее, ведь в ближайшем будущем она должна стать базовой для полупроводникового производства, и уже сегодня активно внедряется в техпроцессы компанией Intel. Идея "напряженного кремния" предельно проста. С целью обеспечения удовлетворительного уровня прохождения носителей заряда специалисты корпорации Intel решили в буквальном смысле растянуть кристаллическую решетку транзистора, чтобы увеличить расстояние между атомами и тем самым облегчить прохождение тока. Инженеры подразделения Logic Technology Development Division разработали два независимых способа растяжения кремния для разных типов транзисторов. Напомним, что существует два типа CMOS-транзисторов (CMOS, complimentary metal oxide semiconductor — полупроводниковая технология, применяемая при изготовлении всех логических микросхем, включая микропроцессоры и чипсеты): n-типа, обладающие электронной проводимостью, и p-типа — с дырочной проводимостью. Так вот, в NMOS-устройствах поверх транзистора в направлении движения электрического тока наносится слой нитрида кремния (Si3N4), в результате чего кремниевая кристаллическая решетка растягивается. В PMOS-устройствах растяжение достигается за счет нанесения слоя SiGe в зоне образования переносчиков тока — здесь решетка сжимается в направлении движения электрического тока, поэтому "дырочный" ток течет свободнее. В первом случае прохождение тока облегчается на 10%, во втором — на 25%. Последняя интерпретация технологии "напряженного кремния" компании Intel позволила улучшить рабочий ток транзисторов на 30%, тогда как ранее оговаривались 10–20%. Причем токи утечки новых 65-нм транзисторов при том же рабочем токе уменьшены вчетверо, так что можно ожидать улучшенного показателя TDP для новых процессоров, и как следствие, уменьшения размеров охлаждающих их систем.

Методика "напряженного кремния" Не менее интересна идея улучшения производительности транзисторов, а заодно и их термохарактеристик, предложенная компанией AMD. В ее основе лежат весьма интересные методы борьбы с токами утечки. В AMD уже сообщали о создании двухзатворного транзистора, но около года назад компания Intel продемонстрировала транзистор с тремя затворами. Дошла очередь до трехзатворного транзистора и в AMD. В новой разработке компании объединены несколько перспективных технологий. Во-первых, для создания токопроводящего канала транзистора используется технология "полностью обедненного кремния-на-изоляторе" (Fully Depleted SOI, FDSOI). Во-вторых, новые транзисторы будут использовать металлические затворы (изготовленные из силицида никеля (NiSi) вместо поликристаллического кремния) Ко всему прочему, транзисторы будут иметь "локально напряженный" канал:. с трех сторон он окружен затворами, выполненными из силицида никеля. Этот металлосодержащий материал обеспечивает лучшие характеристики по сравнению с традиционным кремнием. Подобный подход гарантирует более чем двукратное увеличение быстродействия. Особенностью SOI-технологий AMD является малая диэлектрическая проницаемость изолирующих пленок, в то время как Intel работает с пленками с высокой диэлектрической проницаемостью. Использование силицида никеля для создания затворов приводит к возникновению дефектов в кристаллической решетке кремния в токопроводящем канале. Наличие их позволяет электронам быстрее перемещаться по каналу, повышая быстродействие транзистора. Таким образом, технология "напряженного кремния" компании AMD основана на использовании дефектов кристаллической решетки, которые и применяются для ускорения движения электронов. Сочетание вышеперечисленных технологий позволяет улучшить характеристики транзистора: увеличить ток в открытом состоянии и уменьшить в закрытом; повысить скорость переключения транзистора и, в конечном итоге, повысить производительность всей интегральной схемы. Говоря о "деформированном кремнии" нельзя не упомянуть об аналогичных технологиях полупроводникового энергосбережения компании IBM.
Одна из них была использована при создании транзистора, в котором используется "напряженный кремний, размещенный непосредственно на изоляторе" (strained silicon directly on insulator, SSDOI). Это, по утверждению специалистов компании, позволяет добиться повышения быстродействия с одновременным устранением проблем, связанных с массовым производством. Структура SSDOI создана при помощи переноса напряженного кремния, выращенного посредством эпитаксиального метода (слой за слоем) на ненапряженном SiGe, на слой оксида кремния. Перед окончательным изготовлением микросхемы слой SiGe был удален. Напряженное состояние слоя кремния было сохранено после выполнения циклов переноса слоев и термической обработки. Увеличение подвижности электронов и "дырок" было подтверждено при помощи тестирования MOSFET-транзисторов (полевые МОП-транзисторы), изготовленных по технологии SSDOI.

Технология SSDOI По мнению представителей IBM, новая технология позволит добиться 80%-ного снижения энергопотребления или четырехкратного прироста быстродействия в сравнении с наиболее передовыми существующими решениями. Впрочем, модернизация материалов, используемых при производстве микросхем, — не единственный путь повышения привлекательности энергетических характеристик процессоров. Например, исследователи Intel ведут разработки в области новых материалов и материалов непосредственно для самих транзисторов. Так, в феврале 2005 года инженеры Intel и британской компании QinetiQ предложили новый тип транзисторов, функционирование которых основано на эффекте "квантовой ямы", для изготовления которых служит новый материал — антимонид индия (InSb). В отличие от традиционных транзисторов (в нормальном состоянии они закрыты и при работе открываются положительным потенциалом), созданные Intel и QinetiQ в нормальном состоянии открыты и при работе запираются отрицательным потенциалом. Согласно заявлению фирм, чипы на основе указанной технологии при том же энергопотреблении, что у нынешних микросхем, имеют трехкратное преимущество в быстродействии, или при той же производительности являются в 10 раз экономичнее. Впрочем, к проблеме снижения энерговыделения можно подойти и с другой стороны.
Например, как исследователи из лаборатории изучения цепей корпорации Intel: под руководством Рэма Кришнамурти (Ram Krishnamurty) они идут "путем медиков" — берутся не лечить болезнь, а устранить ее причину. Исследуя проблему высокого нагрева процессоров Intel Pentium 4, команда Рэма Кришнамурти решила разобраться, какие конкретно участки производимого их компанией микропроцессора выделяют больше тепла, а какие — меньше. С этой целью они использовали широко известную технологию "тепловидения". В результате специалисты обнаружили, что до пугающих любого пользователя 125 °С нагревается лишь небольшой участок процессора — ALU (Arithmetic and Logic Unit, элемент для логических и арифметических операций), тогда как вся остальная часть, включая кэш-память, нормально функционирует при вполне приемлемой для кристалла температуре не выше 65 °С. Решением проблемы тепловыделения может стать оптимизация расположения "горячих" элементов по кристаллу чипа, или более ровное их распространение по его площади. Кроме того, как это произошло в случае с "горячими" ALU процессора Pentium 4, разработчикам удалось переработать "электрическую" схему блоков ALU таким образом, что тепловыделение группы транзисторов, составляющих их, снизилось в 4 раза. Еще более интересных результатов в сфере пространственного размещения блоков микросхем достигла Tezzaron Semiconductor, "склеившая" чип микроконтроллера (по технологии FaStack) с оперативной памятью SRAM. В конце прошлого года Tezzaron сообщила о разработке шести прототипов, позволяющих, по ее словам, добиться снижения энергопотребления на 90% (вследствие уменьшения длины внутренних соединений) по сравнению с аналогичными двухмерными чипами. Технология Tezzaron интересна еще тем, что в отличие от, например, аналогичной разработки Samsung, также "склеивающей" флэш-память в MCP-микросхемы (MCP, Multi-Chip Package), ее подход позволяет соединять в одной микросхеме чипы, выполненные по разным технологическим процессам и даже из разных материалов.
А это может оказаться очень кстати для производителей модулей беспроводной связи, ищущих пути упрощения производства. Кстати, у Intel, также активно интегрирующей в свои процессоры ячейки памяти (они образуют кэш процессоров), имеется еще один подход к проблеме объединения кристаллов SRAM с логической частью чипов. В техпроцессе P1264 используются так называемые спящие транзисторы, которые отключают питание отдельных блоков памяти при их бездействии. Результат внедрения — троекратное уменьшение утечки кристалла SRAM, что само по себе немало, особенно если учесть, что кэши процессоров, согласно планам развития продуктов Intel, будут активно увеличиваться. Подход из области "технологий будущего" предлагает группа инженеров из Purdue University. Они недавно запатентовали принципиально новую технологию охлаждения чипов, использующую углеродные нанотрубки и в нано-масштабе повторяющую электрические процессы во время грозы. Принцип названной технологии заключается в том, что цепочка углеродных нанотрубок подвергается воздействию отрицательного электрического заряда, в результате чего происходит излучение электронов, облако которых, перемещаясь между двумя противоположно заряженными электродами, приводит к образованию холодного потока воздуха, который и охлаждает горячую микросхему. Однако несмотря на кажущуюся простоту, описанная выше технология еще далека от выхода за пределы исследовательских лабораторий, поэтому говорить о какой-либо ее коммерческой эксплуатации придется нескоро. Следующим шагом разработчиков станет создание прототипа охлаждающего устройства, встраиваемого, судя по всему, в сам чип, поиск наиболее подходящих материалов и решение различных технических проблем, таких как статическое электричество, возникающее в результате описанных процессов. А это значит, что производители вентиляторов и водяных систем охлаждения могут спать спокойно — ввиду постоянно растущего тепловыделения современных микросхем спрос на их решения будет только расти. В статье использованы открытые материалы компании Intel. document.write('
Очипованный мир
Константин Изварский
«Экспресс-Электроника», #2/2004
Мы боимся потерять свободу, а потому всеми силами противостоим тому, что способно ее ограничить. Какое отношение эта, казалось бы, избитая истина имеет к информационным технологиям? Все довольно просто: шумиха, поднятая вокруг технологии радиочастотной идентификации (Radio Frequency IDentification - RFID), связана отнюдь не с теми явными преимуществами, что несет эта технология компаниям, а, так сказать, с одной из потенциальных возможностей ее применения, ведь чипы RFID можно использовать, в том числе, для слежки за человеком.
Конечно, это повод для возмущения сторонников борьбы за права человека, и при том весьма серьезный. Но оставим спор о вероятности правового беспредела, тем более что сегодня им никого уже не удивишь, поговорим о реалиях новой технологии.
Для начала давайте посмотрим, что же происходит с нашим бытом. А происходит именно то, что когда-то представлялось маловероятным: в него, в этот самый быт (а если быть точным - дом) все интенсивнее проникают высокие технологии. Кофеварка, помимо своего прямого назначения, становится еще и узлом связи (тот, кто следил за новинками со знаменитого Consumer Electronics Show, поймет, о чем речь), холодильник сигнализирует хозяину, находящемуся вдали от дома, что запас продуктов подошел к концу, и т. д. Компьютерам, приобретающим черты самой заурядной бытовой техники, поручают все больше задач. И они с успехом их выполняют. Однако, научив компьютер с похвальной скоростью обрабатывать и надежно хранить данные, мы до сих пор не решили проблему сбора и ввода/вывода информации в компьютерную систему управления любым процессом, будь то производство, торговля или что-то иное. При этом следует учесть, сбор информации должен происходить с минимальным участием человека. Хотя бы потому, что оператор может допустить ошибку при вводе данных, например, с клавиатуры компьютера.
Информация должна быть абсолютно верна - это основной принцип в работе любой системы автоматизации.
Ведь даже на поиск и отсеивание неверно введенной информации в больших массивах данных придется затратить немало времени и средств, не говоря уже о прямых убытках, которые можно понести в результате неадекватного решения, принятого на ее основе. Наиболее же полно всем требованиям компьютерной системы управления, где необходимо распознавание и регистрация объектов в реальном масштабе времени, соответствуют технологии бесконтактной идентификации. Строятся они обычно на оптическом (это не что иное, как штрих-коды) или радиочастотном принципе. Последний как раз и является RFID-технологией. Вообще говоря, системы на базе RFID не являются чем-то принципиально новым: как известно, впервые они были опробованы еще во время Второй мировой войны, в частности, применялись американцами для того, чтобы различать свои и вражеские самолеты. RFID-система состоит из трех основных компонентов: считывателя, транспондера (обычно называемого меткой или тагом - от англ. tag) и компьютерной системы обработки данных. Считыватель имеет приемо-передающее устройство и антенну, которые посылают сигнал к тагу и принимают ответный, микропроцессор, который проверяет и декодирует данные, а также память, которая сохраняет данные для последующей передачи, если это необходимо. Основные компоненты тага - интегральная схема, управляющая связью со считывателем, и антенна. Чип имеет память, хранящую идентификационный код или другие данные. Таг обнаруживает сигнал от ридера и начинает передавать данные, сохраненные в его памяти, обратно в считыватель. Никакой потребности в контакте или прямой видимости между считывателем и тагом нет, поскольку радиосигнал легко проникает через неметаллические материалы. Таким образом, таги даже могут быть скрыты внутри тех объектов, которые подлежат идентификации. Таги могут быть активными или пассивными. Активные таги работают от присоединенного или встроенного элемента питания, они требуют меньшей мощности считывателя и, как правило, имеют большую дальность чтения. Пассивный таг функционирует без источника питания, получая энергию от сигнала считывателя.
Пассивные метки меньше и легче активных, менее дороги, имеют фактически неограниченный срок службы. Активные и пассивные таги могут быть только для чтения, с чтением-записью и однократно записываемыми, данные в которые могут быть занесены пользователем. По большому счету область применения RFID-системы определяется ее частотой. Бывают высокочастотные RFID-системы (850-950 МГц и 2,4-5 ГГц), которые используются там, где требуются большое расстояние и высокая скорость чтения, например, системы сбора отходов, контроль автомобилей. Зачастую считыватели устанавливают на воротах или шлагбаумах, а транспондер закрепляется на ветровом или боковом стекле автомобиля. Большая дальность действия делает возможной безопасную установку считывателей вне пределов досягаемости людей. RFID-системы, использующие промежуточные частоты (10-15 МГц), применяются там, где должны быть переданы большие объемы информации. И наконец, низкочастотные RFID (100-500 кГц) используются там, где допустимо небольшое расстояние между объектом и считывателем. Обычное расстояние считывания составляет 0,5 м, а для тагов, встроенных в маленькие "кнопочки", дальность чтения, как правило, еще меньше - около 0,1 м. Большая антенна считывателя может в какой-то мере компенсировать такую дальность действия небольшого тага, но излучение высоковольтных линий, моторов, компьютеров, ламп и т. п. мешает ее работе. Большинство систем управления доступом, бесконтактные карты, управления складами и производством использует низкую частоту. Из технических свойств RFID несложно вывести преимущества новой технологии: между считывателем и тагом не нужен контакт или прямая видимость, таги читаются быстро и точно (приближаясь к 100%-ной идентификации), они несут большое количество информации и могут быть интеллектуальны, и их практически невозможно подделать. Что ж, это весьма завидные преимущества, и ныне никто их не подвергает сомнению, но вот вопрос - готов ли рынок к широкому внедрению радиочастотной идентификации? Во-первых, надо сказать, что RFID по-настоящему используется, и не первый год.
Причем иногда технологию применяют в весьма необычных целях, к примеру, таги устанавливают на ошейниках домашних животных, для отслеживания ставок в настольных играх, вроде Blackjack. Случаи употребления радиочастотной идентификации в России есть, хотя их довольно мало. Один из таких примеров - используемая (кстати, уже несколько лет) в работе петербургской городской библиотеки им. В. В. Маяковского маркировка недеактивируемыми этикетками книжного фонда. В действительности, распространение RFID-технологии сдерживается высокой стоимостью ее применения (сейчас чипы стоят от 30 до 60 центов, экономическая же выгода получится в том случае, если цена снизится до двух центов, что возможно только при большем объеме их выпуска) и некоторыми техническими недоработками. Скорее всего, мощный импульс развитию технологии дадут значительные инвестиции со стороны крупнейших пользователей. Что касается перспектив, о дальнейшем развитии радиочастотной идентификации аналитики высказываются довольно сдержанно. По прогнозу IDC, объемы продаж RFID-оборудования вырастут с $91,2 млн в 2003 году до более чем $1,3 млрд в 2008-м. Из этой суммы приблизительно $875 млн составят доходы производителей RFID-микросхем и соответствующих систем, а $270 млн будет потрачено на создание инфраструктуры, необходимой для применения технологии. Вместе с тем, как утверждают наблюдатели, рост продаж станет возможным только при увеличении инвестиций в разработки промежуточного ПО, обеспечивающего функционирование систем радиочастотной идентификации. А это произойдет не ранее 2006 года. Столь же сдержанно относятся специалисты и к заявлениям о том, что радиочастотная идентификация способна сделать реальностью мир, описанный Джорджем Оруэллом. Вообще, весь шум, поднятый сторонниками неприкосновенности частной жизни, происходит от незнания явных вещей, ибо не секрет, что, допустим, практика вживления тагов людям уже не первый год существует в США и Мексике: еще в 2002 году компания Applied Digital Solutions получила право продавать микрочипы VeriChip, вживляемые человеку и содержащие его идентификационный код.
Этот код может быть связан с базой данных, в которой находится информация любого рода, в том числе и медицинские данные. Дело в том, что для семей, где есть тяжело больные люди, такой чип - возможность вовремя получить медицинскую помощь или найти потерявшегося человека, пока он не попал в беду. С другой стороны, - и это подтвердит любой эксперт в рассматриваемой области, - принципиально возможна защита от RFID-чипов. Идея состоит в том, чтобы сделать "глушилку", способную противодействовать считывающим устройствам. Разумеется, лучше всего изготовить ее по образу и подобию самих RFID-чипов: "глушилка" должна представлять собой устройство, копирующее работу радиоидентификационных микросхем, с той лишь разницей, что в ответ на запросы считывателей она будет выдавать не полезную информацию, а случайный "мусор". В работе такого блокирующего чипа важны два момента. Во-первых, он должен понимать запросы самых разных считывающих устройств. Во-вторых, на один запрос желательно выдавать сразу множество ответов. Тогда - предположительно - считыватель просто запутается. Идея эта принадлежит компании RSA Security, которая на данный момент довела ее до стадии лабораторного прототипа и рассчитывает в ближайшее время изготовить пробные микросхемы. Так что борцам за свободу можно спать спокойно: по крайней мере, эта, не столь и революционная, технология свободу ни у кого не отнимет.
хочу предупредить, что среди результатов
Прежде чем перейти к результатам тестирования в "1С:Предприятие 8.0", хочу предупредить, что среди результатов вы не найдете измерений при использовании RAID. Мы делали такие измерения, однако в данном режиме работы "1С:Предприятие 8.0" (локальном файловом) включение RAID на результаты не повлияло.


D начального уровня
GMA 900 позиционируется как заменитель дискретной графики начального уровня. Например: участвующий в тестировании PowerColor Radeon 9200 с 128-битным интерфейсом и 128 Мб памяти. Но 9200 уже устарел, сейчас на смену ему приходит Radeon 9550. В нашем случае на нем построена видеокарта ASUS А9550GE/TD. Тоже с 128-битным интерфейсом и 128 Мб памяти.
Начальным дискретным уровнем PCI Express можно считать чип от ATI - Radeon X300 (в нашем случае - референс ATI Radeon X300 SE (RV370) Low-Profile). Памяти тоже 128 Мб, но интерфейс - только 64 бит.
Подобранные видеокарты достаточно похожи по характеристикам (см. таблицу). В частности, у всех установлена память с временем доступа 5 нс - самая дешевая и самая распространенная на рынке.
Архитектурные отличия
Хотя на материнских платах, как можно заметить, стало больше SATA- и аудиоразъемов и, кроме того, появились разъемы PCI Express, эти изменения вызваны серьезными изменениями в архитектуре системы в целом. Естественно, что архитектуру системы просто так менять не станут, но в данном случае новая архитектура - это констатация того факта, что ПК давно перестал быть просто вычислителем. Это универсальная система обработки больших и разнородных информационных потоков, которые зачастую конкурируют за одни и те же ресурсы компьютера.
В качестве примера можно вспомнить, что, начиная с семейства чипсетов i925X/i915 Express, любой ПК может стать основой для предоставления мультимедиа-контента в два различных помещения. Даже система со встроенной графикой имеет два независимых видеоканала и может формировать восемь независимых аудиопотоков. Таким образом, в одном помещении можно устроить домашний кинотеатр, используя один видео- и шесть аудиоканалов (для dolby звука 5+1), а во втором - играть или работать, используя второй видеоканал и два аудио (обычное стерео).
Уже на этом примере "базового" использования ПК можно показать, сколько конкурирующих цифровых потоков присутствует в системе. Каждый видео- и аудиоканал, винчестер и DVD могут самостоятельно обращаться к памяти с помощью DMA. DVD может обращаться к аудио- и видеоканалам. Ну, а процессор может обращаться ко всем. При этом следует учесть, что, объемы информации, необходимой для передачи аудиоканалам, хоть и сравнительно невелики, приходить, тем не менее, должны вовремя, иначе супергерой на экране начнет глотать слова.
В общем, к проблеме "развода" конкурирующих информационных потоков добавляется еще и проблема обеспечения гарантированной доставки, она же - проблема обеспечения качественного сервиса QoS (quality of service), хорошо известная сетевым и телекоммуникационным специалистам. А уж поскольку мы получили типично сетевую задачу, то и решать ее логично было бы с использованием сетевых подходов.
Блок питания
Визуально заметны также отличия блока питания. Точнее, его разъемов. Ну, то, что питание SATA-винчестеров присутствует теперь в обязательном порядке, это понятно. Однако, помимо этого, стал шире и разъем для материнской платы (рис. 7). Правда, обратная совместимость по-прежнему обеспечивается. При подключении старой материнки к новому БП новые провода не используются, а при подключении новой материнки к старому БП к ней придется подсоединить еще один Peripheral Power Connector (четырехконтактный разъем от старых винчестеров).

Основная причина появления нового разъема - повышение уровня потребляемого тока напряжением 12 В в новых и перспективных системах. Так, основной разъем был расширен, чтобы обеспечить для шины PCI Express новый уровень потребляемой мощности, которая теперь может составлять до 75 Ватт. Кроме того, теперь стандарт предписывает остановку кулеров БП при "засыпании" системы.

становящаяся все более популярной программа
CineBench 2003 - становящаяся все более популярной программа тестирования для Windows и Mac OS. Она базируется на системе профессионального рендеринга 3D software CINEMA 4D R8 и позволяет не только измерять производительность процессора и памяти, но и тестировать многопроцессорные (до шестнадцати) системы, умеет использовать многопотоковость и гипертрейдинг. CineBench 2003 позволяет также тестировать производительность видеокарт - но, так как наши участники "не блещут", мы выбрали тесты Software Rendering и Raytracing, в которых рейтинг системы от видеокарты практически не зависит.
в пользу HT. Только за

Еще одно визуальное отличие новой
Еще одно визуальное отличие новой платформы - использование памяти DDR2. Это изменение не отражается на архитектуре системы, поэтому мы рассматриваем его именно как "визуальное". Вообще чипсеты i925X/i915 Express поддерживают и обычную DDR, но контроллер может работать только с одним типом памяти (хотя некоторые производители материнок это ограничение ухитрились обойти - с помощью внешней коммутации на плате). Достоинства и недостатки памяти DDR2 (см. рис. 8) очень прогнозируемы и зависят от ее принципа работы. Интерфейс модуля работает вдвое быстрее, чем в случае с DDR (и в четыре раза быстрее, чем у SDRAM), но сами ячейки памяти по сравнению с DDR быстрее не стали. Правда, выборка данных внутри модуля происходит вдвое большими порциями, чем у DDR. Поэтому и без тестирований можно утверждать, что новая память (на одинаковых частотах ввода-вывода) будет работать действительно быстрее только в приложениях, для которых характерен доступ к большим и непрерывным "порциям" памяти (например, встроенная графика). В "обычных" же приложениях производительность в лучшем случае будет не хуже, чем у DDR.

Endpoints
Об архитектуре в целом мы сказали, а то, какие новые устройства присутствуют (или какие старые отсутствуют) на новой платформе, необходимо рассматривать на примере существующих уже чипсетов i925X / i915 Express. На рис. 12 приведена блок-схема чипсетов i915P и i915G.

Блок-схема i925X отличается отсутствием встроенной графики GMA900, а чипсета i915GV - отсутствием шины PCI Express x16 для внешней графики. От "теоретической" PCI-Express-архитектуры, представленной на рис. 10, архитектура живых чипсетов отличается лишь тем, что шина PCI - традиционно для десктопов - задвинута в южный мост.
Северный мост обоих чипсетов включает: FSB с частотой 800 МГц для i925X и 533/800 МГц для чипсета i915 (который позиционируется как массовый продукт); двухканальный контроллер памяти DDR2-400/533 с поддержкой ECC DDR333/400 для i925X; более демократичный i915 поддерживает DDR333/400 и DDR2-400/533, но без ECC; шину PCI Express x16 для внешних видеоускорителей.
i915G, кроме того, содержит встроенный графический процессор GMA 900 (Graphics Media Accelerator). GMA 900 отличается от своего предшественника в плате i865G не только повышенной частотой графического ядра (333 МГц против 266 МГц) и увеличенным числом пиксельных конвейеров (четыре против одного). Кроме того, GMA 900 практически полностью аппаратно поддерживает DirectX 9 (против 7.1) и поддерживает работу с двумя независимыми мониторами.
Двухканальность памяти в современных системах стала нормой, и поэтому одним из достоинств новых чипсетов стало упрощение ее реализации. Теперь благодаря технологии Flex Memory достаточным условием для двухканального режима работы является всего лишь одинаковый объем памяти на каждом из каналов. Наконец-то память в системе можно наращивать постепенно с сохранением двухканального режима.
Южный мост ICH6 существует в четырех вариантах: ICH6 - минимальный; ICH6R - с функцией RAID; ICH6W - с функцией организации беспроводной сети (Wi-Fi); ICH6RW - c RAID и Wi-Fi.
Из привычной периферии поддерживаются: порты SATA; 8 портов USB 2.0; 6 устройств PCI Bus Master; один Parallel ATA; MAC-контроллер Fast Ethernet (10/100 Мбит/с).
А из числа новинок: четыре порта PCI Express x1; Intel High Definition Audio (восьмиканальный звук с поддержкой практически всех форматов); 4 порта SATA с поддержкой оригинальной технологии Matrix Storage.
С помощью технологии Matrix Storage, доступной на вариантах южного моста ICH6R и ICH6RW, можно создавать обычные массивы RAID0 и RAID1, возможен также вариант создания на двух жестких дисках и RAID0, и RAID1 (рис. 14). То есть один раздел с жизненно важными данными зеркалируется, а раздел со свопами и прочими темпами работает в стрипе. Учитывая полную поддержку AHCI (Advanced Host Controller Interface), мы имеем также возможность горячей замены и поддержку очередей комманд NCQ (необходима комбинация ICH6R и драйверов IAA 4.0 от Intel). Получается неплохое решение для продвинутой рабочей станции и начального сервера.
Южные мосты с индексом H поддерживают также технологию Wireless Connect. Но это еще не готовое решение - для построения Wi-Fi точки доступа понадобится специальный адаптер.
Эффективность Matrix Storage и NCQ
Мы уже отмечали, что сомнительно, чтобы простые тесты могли показать эффективность использования Matrix Storage и NCQ. Тем не менее, приводим результаты работы утилиты HD Tach 2.70. Для одного и двух Maxtor MaXLine III 250 Гб получились следующие результаты:
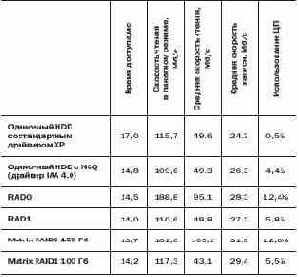
В любом случае понятно, что технология NCQ работает. Это заметно по времени доступа, которое, по меркам современных HDD, уменьшилось едва ли не до рекордных значений.
Неплохо реализован RAID1 - в обоих вариантах он показывает результаты чуть лучше, чем одиночный HDD. Но, естественно, за все нужно платить загрузкой ЦП.
Коммутация пакетов - теперь и в вашем ПК
На рис. 9 приводим оригинальный пример PCI-Express-топологии. Основная новинка - коммутатор (switch) - заметна сразу.

Вся топология - типичная сеть. И подходы к передаче информации тоже типично сетевые. Коммутатор позволяет организовывать соединения типа "точка-точка" внутри системы. Взаимодействие же устройств происходит по четырехуровневой модели (практически подмножество модели OSI), которая имеет физический уровень, уровни соединения, транзакции и ПО.
Уровень транзакций принимает запросы от ПО и формирует пакеты для передачи. Уровень соединения обеспечивает правильную последовательность передачи пакетов и их безошибочность.
Физический уровень в нынешнем варианте PCI Express - это совокупность независимых самостоятельных последовательных каналов передачи данных. Каждый из которых состоит из двух дифференциальных сигнальных пар. Пропускная способность одного канала в каждом направлении одновременно (полный дуплекс) - 2,5 Гбит/с. Однако эффективная скорость передачи данных составляет 2 Гбит/с (200 Мб/с), поскольку для помехозащищенности каждый байт передается десятью битами. Стандарт оговаривает 1-, 2-, 4-, 8-, 16- и 32-канальные варианты - то есть до 6,4 Гб/с в одну сторону. Данные передаются параллельно (но не синхронно) по всем доступным каналам, как показано на рис. 10.

Обратите внимание, что уже один канал (4 контакта) обеспечивает пропускную способность выше, чем стандартный PCI (200 Мб/с против 133 Мб/с). И мы не зря сказали о "нынешнем" физическом уровне. Все технологии, которые нужно изменить для наращивания скорости канала, сосредоточены именно в нем. Поэтому, если мы завтра вместо меди будем использовать оптику, архитектура системы от этого не изменится.

Что еще осталось сказать по поводу PCI-Express-архитектуры? Предусматривается четыре уровня приоритетов для пакетов данных, что позволяет обеспечить QoS. Ну, и пакеты могут ходить не только внутри системы - см. рис. 11.
Кулер
При разработке нового кулера (рис. 4) ставилась задача обеспечить не только охлаждение процессора, но и частичное охлаждение всей его "обвязки". Ведь преобразователи напряжения процессора и памяти выделяют очень много тепла. В новой системе их охлаждению способствуют вихревые потоки воздуха, создаваемые кулером.

Что касается самого кулера - то это, в принципе, привычная уже конструкция с медным сердечником и алюминиевыми ребрами. Значительно отличаются лишь две вещи: крепление и разъем. Крепление представляет собой четыре пластмассовых замка, которые вставляются в отверстие на плате и фиксируются поворотом на 90 градусов - просто, удобно, надежно.
Электрический разъем кулера - типичный пример принципиальных изменений, коих в новой платформе множество. Визуально - добавлен еще один провод. Но за этим проводом скрыта новая стандартизированная система управления производительностью кулеров.
Напомню, на обычном кулере было три провода: два - питание, один - тахометр. Недостаток этой схемы заключается в отсутствии явного управления оборотами (производительностью) кулера - управлять можно, изменяя напряжение питания. и на сегодня есть много систем, использующих этот подход. Но, во-первых, это внешняя аналоговая схема, а во-вторых, для каждого кулера изменение частоты вращения в зависимости от напряжения индивидуально. То есть нужна еще и обратная связь.
А между тем, возможность управлять производительностью кулеров - это просто необходимость на сегодняшний день. Для охлаждения полностью загруженного ЦПУ нужен очень производительный (и очень шумный) кулер. Но! В режиме полной загрузки типичный ПК работает, мягко говоря, редко.
Поэтому вовсе необязательно без толку воздух гонять. Именно поэтому в конструкцию нового кулера и был введен новый провод, позволяющий с помощью простого цифрового сигнала однозначно задавать режим работы вентилятора кулера. На четвертый провод подаются импульсы обычного цифрового сигнала, ширина (скважность) которых задает производительность кулера. То есть имеет место широтно-импульсная модуляция (ШИМ).

Есть два крайних положения: на цифровом входе постоянная "1" (ширина импульсов - 100%), кулер работает на полную мощность. Если же на цифровом входе постоянный "0" (ширина импульсов 0%), кулер будет работать на 20% мощности. Таким образом достигается и обратная совместимость. При подключении старого кулера к новой плате сигнал ШИМ не используется. Если же к старой плате будет подключен новый кулер (см. рис. 5), все будет работать. Так как цифровой провод будет "висеть", на нем подразумевается постоянная логическая "1" - и кулер будет работать на полную мощность. А поскольку параметры управления стандартизованы (рис. 6), появляется возможность единым образом управлять разными кулерами от разных производителей. И, самое приятное,- ПК не будет шуметь больше чем нужно.
Параметры графических подсистем

Тестирование PCI-Express-графики производилось на материнской плате Intel Desktop Board LAD915GUXLW, а AGP-графики - на материнской плате ASUS P4C800.
Процессор и сокет
Если говорить о визуальных отличиях новых процессоров, то их два. Во-первых, маркировка. Для человека, привыкшего к тому, что процессоры Intel маркировались по частоте, название "P4 560" будет, наверное, не совсем понятным. "560" - это так называемый процессорный номер.

Процессорный номер не является показателем производительности. Он зависит от отдельных характеристик процессора, таких как частота ядра, частота FSB, размер кэша и некоторых других характеристик.
P4 560 - это Socket 775 процессор с ядром Prescott с 1 Мб кэша L2 и частотой 3,6 ГГц. P4 550 - это процессор с частотой 3,4 ГГц. Подробнее о характеристиках процессоров и их номерах можно узнать на сайте производителя (www.intel.com/products/processor_number).
Для чего были введены эти номера? Для того чтобы пользователь, неискушенный в ИТ-технологиях, мог ориентироваться в сравнительной производительности процессоров. Внутри одного семейства процессоров (обычного, мобильного и "экстрим") процессор с большим номером более производителен. Но это внутри семейства! Процессоры обычный и мобильный с одинаковыми номерами могут иметь различную производительность.

Следующее визуальное отличие новых процессоров - это ножки. Точнее, их отсутствие (см. рис. 1). Вместо них - контактные площадки. На самом же сокете появились конические пружинящие ножки (рис. 2). Такая форма ножек позволяет убить сразу двух зайцев. Во-первых, в случае плохого контакта между ножкой и контактной площадкой на процессоре в месте соприкосновения будет выделяться тепло, которое будет частично размягчать острие на конце ножки, способствуя тем самым восстановлению контакта. Во-вторых, не сложно заметить, что общая длина всей контактной системы, соединяющей процессор и плату, значительно уменьшилась. Это, в свою очередь, снизило тепловое сопротивление всей системы (не говоря уже о том, что такое устройство проще, чем устройство традиционного ZIF-сокета).

Вообще, именно улучшение теплоотводящих свойств является официальной причиной появления нового сокета. Как уже было отмечено, благодаря ножкам на сокете тепло лучше отводится вниз, а если посмотреть на процессор, установленный в сокете (рис. 3), сверху, становится понятно, что массивная металлическая прижимная пластина также является дополнительным теплоотводом.
Однако у нового сокета для Intel есть еще одно немаловажное достоинство. Посмотрите еще раз на рис. 3. Кулер еще не установлен, но видно, что система в сборе более чем защищена от рук самодеятельного сборщика. Кроме того, теперь усилие посадки процессора на сокет не зависит от веса кулера и, опять же, от качества его установки. Таким образом, на сегодня LGA775 - самый "вандалоустойчивый" сокет. Конечно, можно еще повредить ножки на сокете, но, во-первых, для этого нужны осознанные зловредные телодвижения, а во-вторых, материнки, как правило, дешевле процессоров, так что это менее вероятный и менее болезненный риск.
Спокойная революция
Сергей Антончук, "Комиздат"
Новая платформа на этот раз действительно новая! - таково первое впечатление от знакомства с платформами Intel, основанными на сокете LGA775. Хотя данный сокет - это не самое главное и не самое долгоживущее нововведение, с которыми нам теперь придется жить.
Как-то слишком тихо было в последнее время в компьютерном мире. Создавалось впечатление, что одни лишь производители графических чипов не стоят на месте. Однако оказалось, что это не так - даже наоборот. Просто очень много эволюционных и революционных изменений в массовых платформах "созрело" практически одновременно. И компания Intel решила вывести их на рынок единым пакетом. Поэтому новое теперь действительно целиком ново.
Материальным воплощением новых технологий стало семейство чипсетов i925X/i915 Express с поддержкой Socket 775, DDR2 и PCI Express. Хотя, если принимать во внимание именно важность нововведений, то я бы сказал, что это PCI Express чипсет. Ведь PCI Express - это революция, остальные же нововведения более или менее эволюционны.
Тем не менее, в первую очередь в глаза бросаются именно визуальные отличия, поэтому "разбор" новинок начнем с собственно Socket 775, а о PCI Express расскажем отдельно.
с помощью SYSmark2004 добавляется платформа
В тестировании производительности в типичных офисных задачах с помощью SYSmark2004 добавляется платформа на базе Intel Desktop Board D925XCVLK. Остальные участники и параметры те же.
в данном случае не сыграли
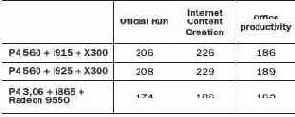
Тестирование скорости
Тестирование скорости для новой платформы мы, конечно, проводили, но в данном случае это было необязательно - и вот почему. Основные новые технологии, такие как PCI-Express и DDR2, внедрялись в новые чипсеты не для того, чтобы что-то отыграть у существующих платформ. Они создавались для того, чтобы идти дальше. Поэтому еще до начала тестирований мы точно знали, что: В существующих на сегодня игровых и десктопных тестах практически невозможно показать преимущества PCI-Express. Практически все тесты "напрягают" одну или две подсистемы ПК - как правило, графику или связку "процессор - память". Т.е. есть только один большой информационный поток. Простая шина прокачает его никак не медленнее. PCI-Express суммарно может прокачать намного больше, и с гарантированными параметрами - но за все нужно платить. На коммутации пакетов мы пару процентов потеряем. Но ведь тесты это не жизнь! В реальности даже у геймера в системе крутится не только одна игрушка. Однозначно хорошо PCI-Express должна показать в ServerBench, однако это тема другой статьи. Память DDR2-533 - ввиду большей латентности - при работе с нынешними процессорами с FSB 800 МГц не будет выглядеть лучше, чем DDR-400. Правда, у нее большая полоса пропускания, но полноценно воспользоваться ею смогут только процессоры с FSB 1066 МГц. Сегодня же разница между ними должна составлять, в зависимости от специфики задачи, максимум +-5%. Анализ эффективности Matrix Storage и NCQ - тоже задача не тривиальная. Из синтетических тестов объективными здесь будут также лишь монстры ServerBench / WebBench и, возможно, встроенные бенчмарки СУБД.
Экстремальных игровых тестов тоже не будет. PCI-Express-видеокарты пока очень дороги и не очень доступны на рынке. Наши тесты затронут, в основном, общую производительность системы в синтетических тестах, не завязанных на 3D-графике. Ну, и по традиции протестируем новую платформу в "1С:Предприятие 8.0".
Тестируемые платформы

Естественно, что графика начального уровня и не предназначена для игр с высокими аппаратными требованиями, поэтому ограничимся двумя привычными синтетическими тестами: 3D Mark 2001 SE и 3D Mark 2003 в разрешении 1024х768 без сглаживания, со свежим комплектом драйверов и без оптимизации системы "руками". Результаты ниже:

По производительности GMA 900 практически достал Radeon 9200. Разрыв составил 7% в 3D Mark 2003 и 4% 3D Mark 2001SE. Если учесть, что видеокарты с 64-битным интерфейсом памяти, как минимум, на 30% медленнее, чем наши участники, то можно утверждать, что они будут также медленнее, чем GMA 900. Однако Radeon 9200, по всей видимости, еще продержится на рынке, так как в AGP-сегменте GMA 900 ему прямо не угрожает.
Что касается PCI Express, то даже наша максимально урезанная карточка X300 SE уверенно защитила свои позиции: она на 73% быстрее, чем GMA 900 в 3D Mark 2003 (хотя в 3D Mark 2001SE - только на 12%). Это, кстати, свидетельствует о том, что аппаратная поддержка DirectX 9 в X300 реализована значительно лучше. О достаточном потенциале чипа X300 можно судить и по результатам тестов при включенном сглаживании (см. ниже). Здесь X300 более чем вдвое отрывается от 9200.
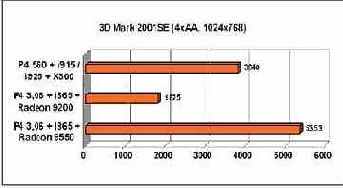
Что касается результатов А9550GE, то можно сказать, что с массовым появлением карт на Radeon 9550 для GMA 900 останется только сегмент "очень начального" уровня. Хотя красоты DirectX 9 посмотреть можно будет.
Визуальные отличия
Новая платформа "материализовалась" в нашей тестовой лаборатории в виде двух материнских плат и двух процессоров P4 560 от Intel.
Одна материнка основана на чипсете i915G - Intel Desktop Board LAD915GUXLW, вторая - на чипсете i925, Intel Desktop Board D925XCVLK.
Как уже было сказано, новая
Как уже было сказано, новая платформа создавалась не для того, чтобы что-то отыграть у уже существующих платформ. Она создавалась, чтобы был прогресс завтра. Тем не менее, уже сейчас пользователь получит увеличение производительности, пропорциональное росту частоты новых процессоров. К тому же на сегодня еще нет тестов, которые могли бы показать внутренние преимущества новой платформы. "Узкозаточенные" тесты здесь не показательны. Массовыми системы LGA775 прямо сейчас, конечно, не станут. Хотя бы потому, что для них подходят только "топовые" процессоры. Но уже сегодня видно, каким будет будущее. Запланированно быстрым.