Нейрокомпьютинг и его применения в экономике и бизнесе
Прореживание связей
Эта методика стремится сократить разнообразие возможных конфигураций обученных нейросетей при минимальной потере их аппроксимирующих способностей. Для этого вместо колоколообразной формы априорной функции распределения весов, характерной для обычного обучения, когда веса "расползаются" из начала координат, применяется такой алгоритм обучения, при котором функция распределения весов сосредоточена в основном в "нелинейной" области относительно обльших значений весов (см.
рисунок 3.9).
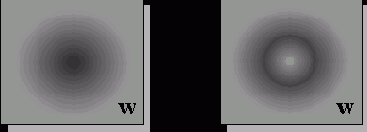
Рис. 3.9. Подавление малых значений весов в методе прореживания связей
Этого достигают введением соответствующей штрафной составляющей в функционал ошибки. Например, априорной функции распределения:

имеющую максимум в вершинах гиперкуба с


в функционале ошибки. Дополнительная составляющая градиента

исчезающе мала для больших весов,


Таким образом, происходит эффективное вымывание малых весов (weights elimination), т.е. прореживание малозначимых связей. Противоположная методика предполагает, напротив, поэтапное наращивание сложности сети. Соответствующее семейство алгоритмов обучения называют конструктивными алгоритмами.