Нейрокомпьютинг и его применения в экономике и бизнесе
Оценка вычислительной сложности обучения
В этой лекции мы рассмотрели два разных типа обучения, основанные на разных принципах кодирования информации выходным слоем нейронов. Логично теперь сравнить их по степени вычислительной сложности и выяснить когда выгоднее применять понижение размерности, а когда - квантование входной информации.
Как мы видели, алгоритм обучения сетей, понижающих размерность, сводится к обычному обучению с учителем, сложность которого была оценена ранее. Такое обучение требует









Кластеризация или квантование требуют настройки гораздо большего количества весов - из-за неэффективного способа кодирования. Зато такое избыточное кодирование упрощает алгоритм обучения. Действительно, квадратичная функция ошибки в этом случае диагональна, и в принципе достижение минимума возможно за




При одинаковой степени сжатия, отношение сложности квантования к сложности данных снижения размерности запишется в виде:

Рисунок 4.11 показывает области параметров, при которых выгоднее применять тот или иной способ сжатия информации.
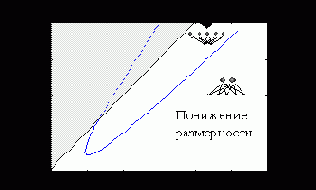
Рис. 4.11. Области, где выгоднее использовать понижение размерности или квантование
Наибольшее сжатие возможно методом квантования, но из-за экспоненциального роста числа кластеров, при большой размерности данных выгоднее использовать понижение размерности. Максимальное сжатие при понижении размерности равно



В качестве примера рассмотрим типичные параметры сжатия изображений в формате JPEG.
При этом способе сжатия изображение разбивается на квадраты со стороной





размерности. 1)
Однако, при увеличении размеров элементарного блока, появляется область высоких степеней сжатия, достижимых лишь с использованием квантования. Скажем, при



