Нейрокомпьютинг и его применения в экономике и бизнесе
Пример: поиск промоторов в ДНК
Промоторами называются области четырехбуквенной последовательности ДНК (построенной из нуклеотидов A,T,G,C), которые предшествуют генам. Эти области состоят из 50-70 нуклеотидов и распознаются специальным белком РНК-полимеразой. Полимераза связывается с промотором и транскрибирует ее (расплетает на две нити). У кишечной палочки, например, обнаружено около трехсот различных промоторов. Несмотря на различие, эти области имеют некоторые похожие участки, которые представляют собой как бы искажения некоторых коротких последовательностей нуклеотидов (например, бокс Гильберта - TTGACA и бокс Прибноу - TATAAT). Поэтому основные методы распознавания промоторов основываются на представлении о консенсус-последовательности: некотором идеальном промоторе, искажениями которого являются реальные промоторы. Близость некоторой последовательности к консенсус-последовательности оценивается по значению некоторого индекса гомологичности. Очевидно, что представление о версии-прототипа в теории минимизирующих энергию нейронных
сетей прямо соответствует представлению о консенсус-последовательности.
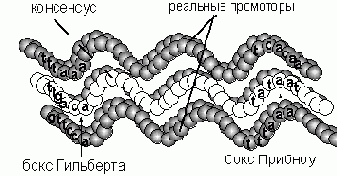
Рис. 5.7. Идеальный промотор - консенсус-последовательность (в середине) является аналогом единственной версии прототипа - аттрактора в сети Хопфилда, выработанной в ней при записи зашумленных сообщений (аналогов реальных промоторов: сверху и снизу). Аналогом гомологического индекса, определяющего близость реальных промоторов к консенсус-последовательности, является энергия состояния сети
Поэтому сеть Хопфилда, например, может непосредственно использоваться для ее поиска. Более того, оказывается, что энергия состояния сети может использоваться в качестве аналога гомологического индекса при оценке близости последовательности промотора к консенсус-последовательности. Такой подход позволил создать новый, весьма эффективный нейросетевой метод поиска промоторов. Аналогичный подход может использоваться для поиска скрытых повторов в ДНК и реконструкции эволюционных изменений в них.
Хотя молекулярная генетика представляет собой достаточно специфическую область применения методов обработки информации, она часто рассматривается как показательный пример приложений такой информационной технологии, как Извлечение Знаний из Данных (Data Mining). Применение для этих целей нейросетевых методов мы рассмотрим более подробно в отдельной лекции.