Нейрокомпьютинг и его применения в экономике и бизнесе
В чем различие нейронных сетей и статистики?
В чем же заключается сходство и различие языков нейрокомпьютинга и статистики в анализе данных. Рассмотрим простейший пример.
Предположим, что мы провели наблюдения и экспериментально измерили N пар точек, представляющих функциональную зависимость






Если параметры
Та же самая задача может быть решена с использованием однослойной сети с единственным входным и единственным линейным выходным нейроном. Вес связи a и порог b могут быть получены путем минимизации той же величины невязки (которая в данном случае будет называться среднеквадратичной ошибкой) в ходе обучения сети, например методом backpropagation. Свойство нейронной сети к обобщению будет при этом использоваться для предсказания выходной величины по значению входа.
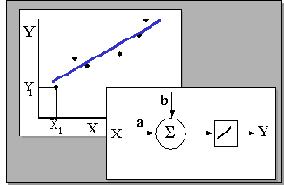
Рис. 11.1. Линейная регрессия и реализующий ее однослойный персептрон
При сравнении этих двух подходов сразу бросается в глаза то, что при описании своих методов статистика апеллирует к формулам и уравнениям, а нейрокомпьютинг к графическому описанию нейронных архитектур.
Если вспомнить, что с формулами и уравнениями оперирует левое полушарие, а с графическими образами правое, то можно понять, что в сопоставлении со статистикой вновь проявляется "правополушарность" нейросетевого подхода.
Еще одним существенным различием является то, что для методов статистики не имеет значения, каким образом будет минимизироваться невязка - в любом случае модель остается той же самой, в то время как для нейрокомпьютинга главную роль играет именно метод обучения.
В отличие от нейронных сетей, требующих обучения, факторный анализ может работать лишь с определенным числом наблюдений. Хотя в принципе число таких наблюдений должно лишь на единицу превосходить число переменных рекомендуется использовать хотя бы втрое большее число значение. Это все равно считается меньшим, чем объем обучающей выборки для нейронной сети. Поэтому статистики указывают на преимущество факторного анализа, заключающееся в использовании меньшего числа данных и, следовательно, приводящего к более быстрой генерации модели. Кроме того, это означает, что реализация методов факторного анализа требует менее мощных вычислительных средств. Другим преимуществом факторного анализа считается то, что он является методом типа white-box, т.е. полностью открыт и понятен - пользователь может легко осознавать, почему модель дает тот или иной результат. Связь факторного анализа с моделью Хопфилда можно увидеть, вспомнив векторы минимального базиса для набора наблюдений (образов памяти - см. Лекцию 5). Именно эти векторы являются аналогами факторов, объединяющих различные компоненты векторов памяти - первичные признаки.
Иными словами, в отличие от нейросетевого подхода, оценка параметров модели для статистических методов не зависит от метода минимизации. В то же время статистики будут рассматривать изменения вида невязки, скажем на

как фундаментальное изменение модели.
В отличие от нейросетевого подхода, в котором основное время забирает обучение сетей, при статистическом подходе это время тратится на тщательный анализ задачи. При этом опыт статистиков используется для выбора модели на основе анализа данных и информации, специфичной для данной области. Использование нейронных сетей - этих универсальных аппроксиматоров - обычно проводится без использования априорных знаний, хотя в ряде случаев оно весьма полезно. Например, для рассматриваемой линейной модели использование именно среднеквадратичной ошибки ведет к получению оптимальной оценки ее параметров, когда величина шума имеет нормальное распределение с одинаковой дисперсией для всех обучающих пар. В то же время если известно, что эти дисперсии различны, то использование взвешенной функции ошибки

может дать значительно лучшие значения параметров.
Помимо рассмотренной простейшей модели можно привести примеры других в некотором смысле эквивалентных моделей статистики и нейросетевых парадигм
| Многослойный персептрон | Нелинейная (в т.ч. логистическая) регрессия, Дискриминантные модели |
| Автоассоциативный персептрон | Анализ главных компонент |
| Векторная квантизация | Кластеризация с k-средними |
| Сети нейронов высоких порядков | Полиномиальная регрессия |
Сеть Хопфилда имеет очевидную связь с кластеризацией данных и их факторным анализом.
Факторный анализ используется для изучения структуры данных. Основной его посылкой является предположение о существовании таких признаков - факторов, которые невозможно наблюдать непосредственно, но можно оценить по нескольким наблюдаемым первичным признакам. Так, например, такие признаки, как объем производства и стоимость основных фондов, могут определять такой фактор, как масштаб производства.
В отличие от нейронных сетей, требующих обучения, факторный анализ может работать лишь с определенным числом наблюдений. Хотя в принципе число таких наблюдений должно лишь на единицу превосходить число переменных рекомендуется использовать хотя бы втрое большее число значение. Это все равно считается меньшим, чем объем обучающей выборки для нейронной сети. Поэтому статистики указывают на преимущество факторного анализа, заключающееся в использовании меньшего числа данных и, следовательно, приводящего к более быстрой генерации модели. Кроме того, это означает, что реализация методов факторного анализа требует менее мощных вычислительных средств. Другим преимуществом факторного анализа считается то, что он является методом типа white-box, т.е. полностью открыт и понятен - пользователь может легко осознавать, почему модель дает тот или иной результат. Связь факторного анализа с моделью Хопфилда можно увидеть, вспомнив векторы минимального базиса для набора наблюдений (образов памяти - см. Лекцию 5). Именно эти векторы являются аналогами факторов, объединяющих различные компоненты векторов памяти - первичные признаки.
Логистическая регрессия является методом бинарной классификации, широко применяемом при принятии решений в финансовой сфере. Она позволяет оценивать вероятность реализации (или нереализации) некоторого события в зависимости от значений некоторых независимых переменных - предикторов:



Достоинством нейронных сетей является то, что такая ситуация не представляет для них проблемы. Кроме того, нейросети нечувствительны к корреляции значений предикторов, в то время как методы оценки параметров регрессионной модели в этом случае часто дают неточные значения. В то же время многие нейронные парадигмы, такие как сети Кохонена или машина Больцмана не имеют прямых аналогов среди статистических методов.
В каком-то смысле недоверие и даже "ревность" к нейросетевым методам в сообществе статистиков аналогичны такому же отношению, существовавшему в недалеком прошлом среди специалистов в области Искусственного Интеллекта. Теперь же значительную часть публикаций в журналах типа Artificial Intelligence (AI) или AI Expert составляют работы, посвященные нейронным технологиям. В настоящее время в статистическом сообществе растет интерес к нейронным сетям, как с теоретической, так и с практической точек зрения. Это проявляется в инкорпорации нейросетевых средств в стандартные статистические пакеты, такие как SAS и SPSS.